













系統(tǒng)設計:設計URL短鏈接工具

這是一個系統(tǒng)設計問題,要求從頭開始設計一個類似于TinyURL或Bitly的URL短鏈接工具。我們將涵蓋從設計需求、架構和組件設計到高性能擴展和安全最佳實踐的各個方面。
定義范圍:功能性和非功能性需求
首先,我們需要定義該系統(tǒng)的功能性和非功能性需求。
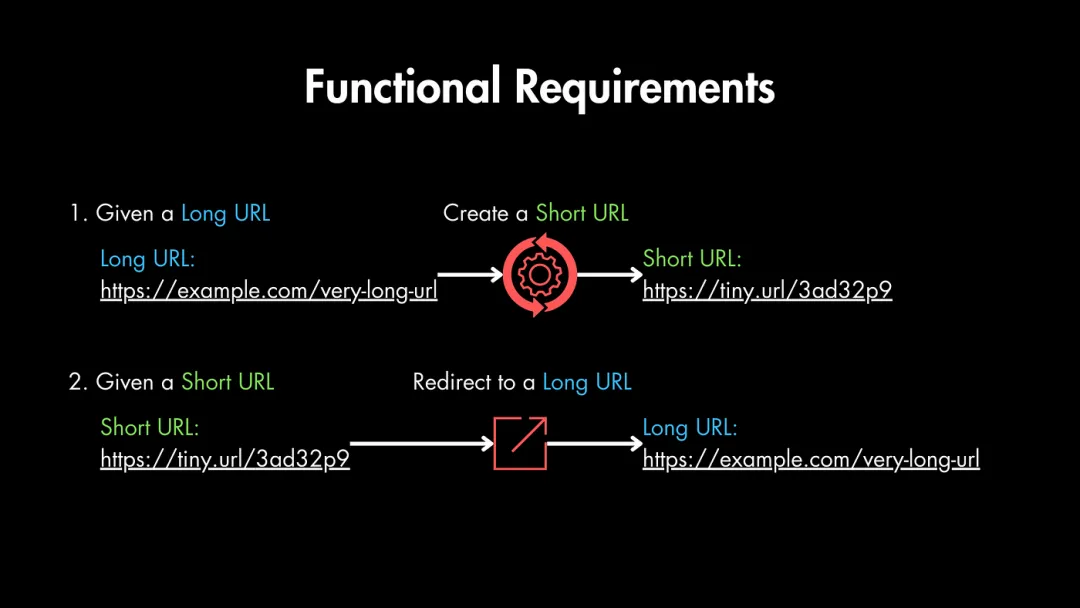
我們有兩個功能性需求:
- 給定一個長URL時,我們必須創(chuàng)建一個短URL
- 給定一個短URL時,我們必須將用戶重定向到長URL。
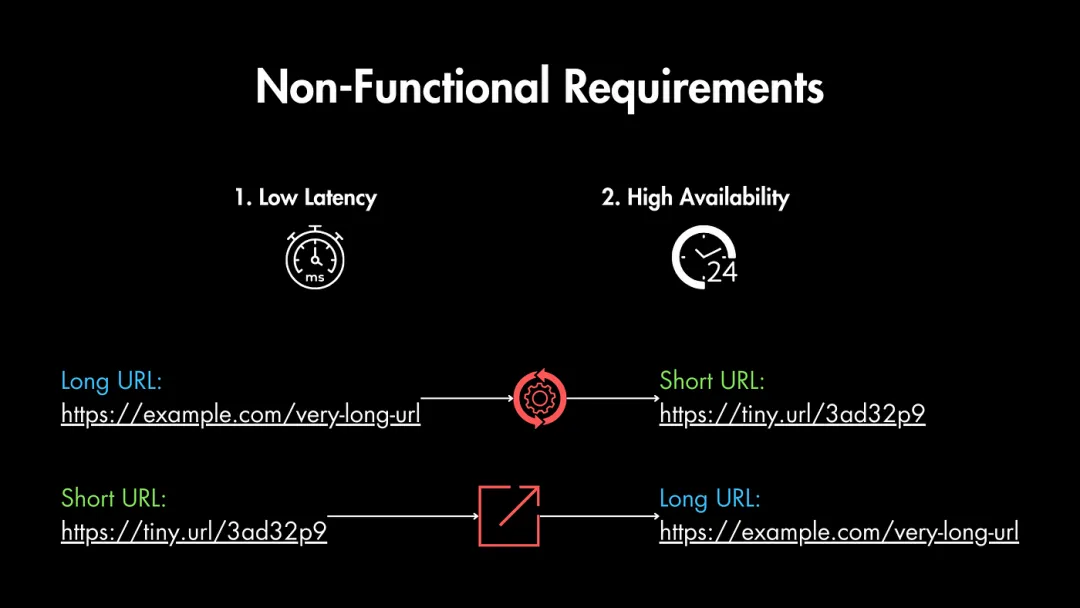
該服務的非功能性需求是優(yōu)先考慮低延遲(快速響應)和高可用性(始終在線)。
明確業(yè)務問題
以下是一些我們可能需要明確的問題,以確保我們對系統(tǒng)的規(guī)模有一致的理解:
- 使用情況:估計我們每秒需要創(chuàng)建多少個URL(假設是1000個)。
- 字符:我們可以使用數(shù)字和字母(字母數(shù)字)還是其他符號?(我們假設使用字母數(shù)字字符)。
- 唯一性:每次生成的短URL是否唯一,即使多個用戶提交相同的長URL?(在這個設計中,我們假設是唯一的)。
估算:數(shù)據(jù)計算
有了這些信息,我們需要計算縮短后的URL應該有多長。當然,我們希望它盡可能短,但我們需要考慮到每年的URL創(chuàng)建數(shù)量。
首先,讓我們估算一個顯著時期內(nèi)所需的唯一URL數(shù)量。常見的方法是計劃至少幾年的運營。為了簡化計算,我們假設計算10年的數(shù)據(jù)。
- 一年中的秒數(shù):每分鐘60秒 × 每小時60分鐘 × 每天24小時 × 每年365天 = 31.536百萬秒
- 10年中的總秒數(shù):31.536百萬 × 10 = 315.36百萬秒
- 10年中的總URL數(shù):1000 × 315.36百萬 = 315.36十億個唯一URL
這意味著我們的數(shù)據(jù)庫每秒需要處理1000次寫入,每年將生成1000 × 60 × 60 × 24 × 365 = 31.5B個URL。如果我們假設讀取次數(shù)通常是寫入次數(shù)的10倍,這意味著我們每秒將獲得超過10 × 1000 = 10000次讀取。
現(xiàn)在,我們需要弄清楚多少個字符能為我們未來十年的量提供足夠的唯一短URL。考慮到字符集大小為62,可以按如下計算URL標識符的長度:
- 621 = 62個唯一URL(1個字符)
- 622 = 3844個唯一URL(2個字符)?…等等。

繼續(xù)這種計算,我們看到62?(大約3.5萬億)是第一個大于我們預計的3150億URL所需的值。
因此,為了支持我們未來十年的預期增長,我們的縮短URL需要至少7個字符。
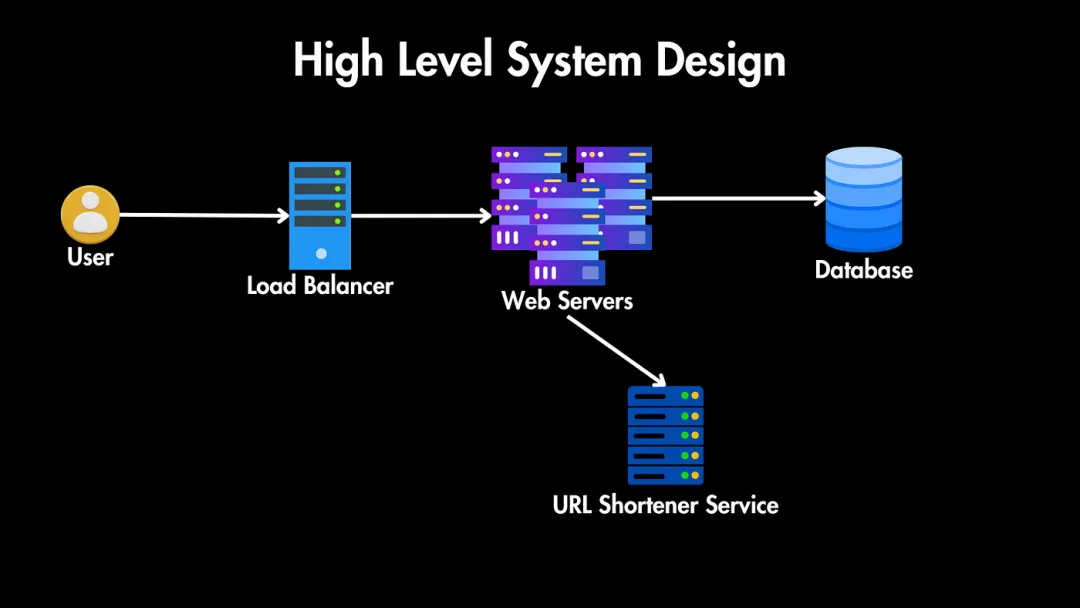
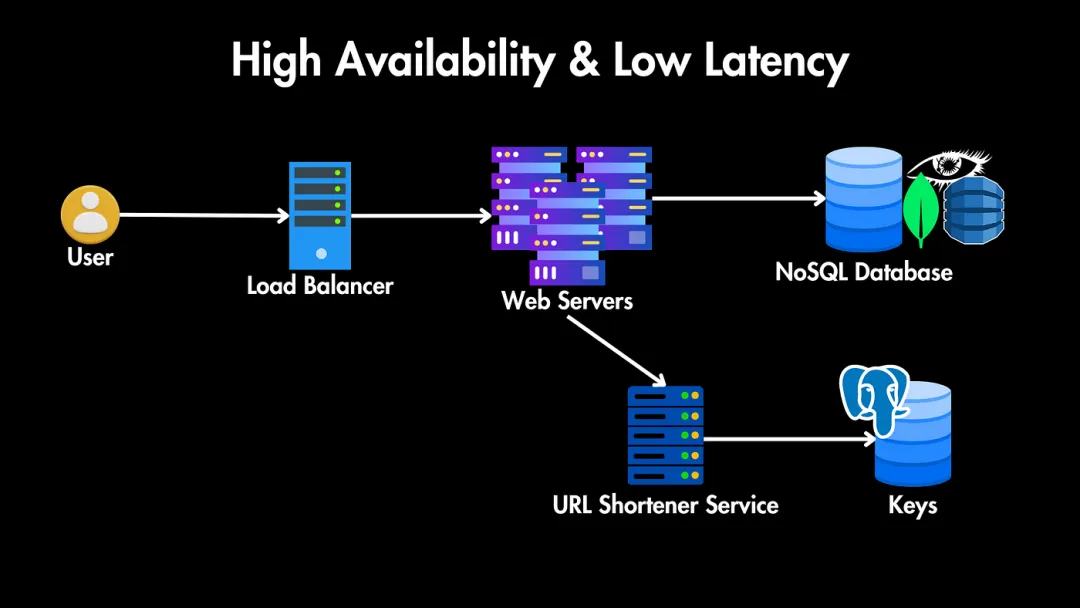
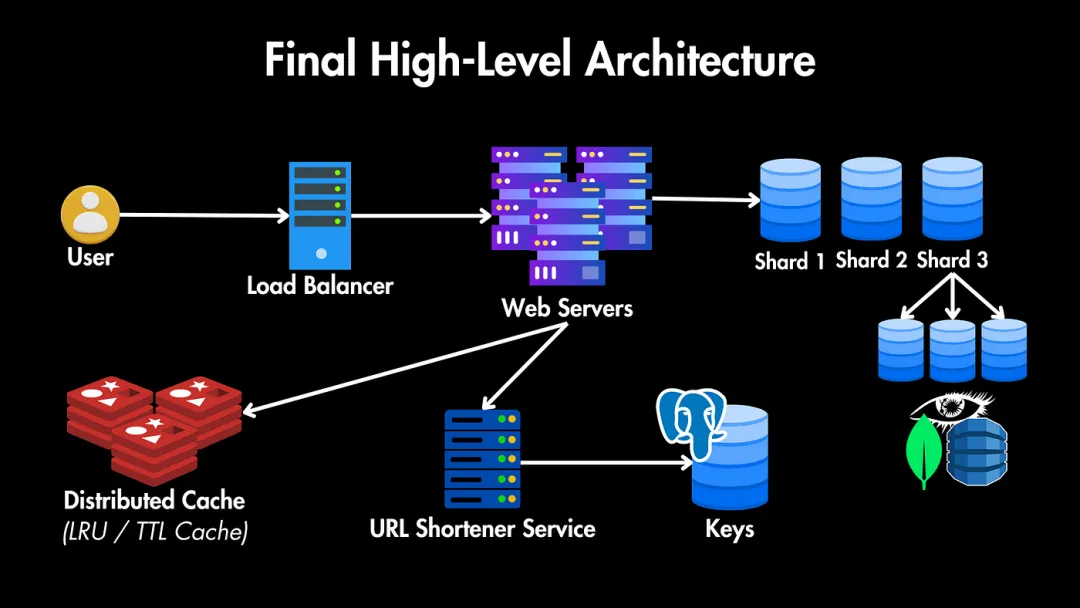
高層次架構
我們的系統(tǒng)將有以下關鍵組件:
- 用戶:用戶發(fā)送他們的長URL以生成短URL,或發(fā)送短URL,我們需要將他們重定向到長URL。
- 負載均衡器:所有這些請求通過負載均衡器,它將流量分配到多個Web服務器實例,以確保高可用性和負載均衡。
- Web服務器:這些服務器副本負責處理傳入的HTTP請求。
- URL短鏈接服務:我們還需要一個包含生成短URL、存儲URL映射和檢索原始URL以進行重定向的核心邏輯的URL短鏈接服務。
- 數(shù)據(jù)庫:存儲短URL及其長URL之間的連接。在設計數(shù)據(jù)庫之前,我們需要考慮縮短URL的潛在存儲需求。
每個URL將包括唯一標識符(大約7個字節(jié))、長URL(最多100個字節(jié))和用戶元數(shù)據(jù)(估計為500個字節(jié))。這意味著我們每個URL需要最多1000個字節(jié)。根據(jù)我們的預期量,這相當于大約315TB的數(shù)據(jù)。
在繼續(xù)之前,讓我們先考慮一下單個Web服務器的API設計。
API設計
讓我們定義服務的基本API操作。根據(jù)我們的功能需求,我們將使用REST API,并需要兩個端點。
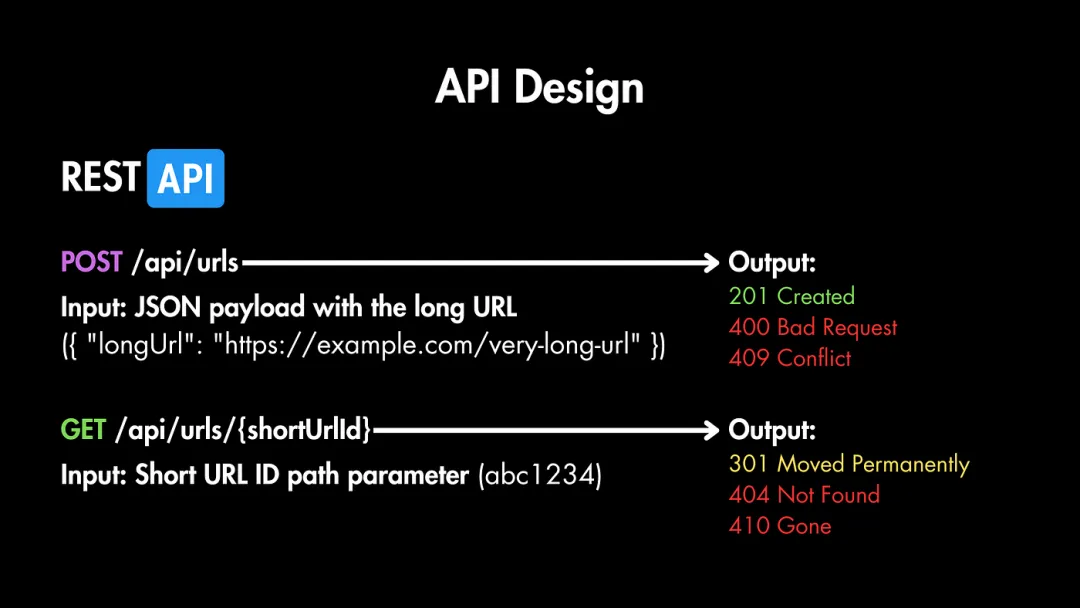
(1) 創(chuàng)建短URL (POST **/urls**)
- 輸入:包含長URL的JSON負載 {“l(fā)ongUrl”: “[https://example.com/very-long-url](https://example.com/very-long-url)"}
- 輸出:帶有短URL的JSON負載 {“shortUrl”: “[https://tiny.url/3ad32p9](https://tiny.url/3ad32p9)"} 和 201 Created 狀態(tài)碼。
如果請求無效或格式錯誤,我們將返回 400 Bad Request 響應,如果請求的URL已經(jīng)存在于系統(tǒng)中,我們將返回 409 Conflict。
(2) 重定向到長URL (GET **/urls/{shortUrlId}**)
- 輸入:shortUrlId 路徑參數(shù)
- 輸出:帶有 301 Moved Permanently 的響應,響應體中包含新創(chuàng)建的短URL作為JSON { "shortUrl": "https://tiny.url/3ad32p9" }
301狀態(tài)碼指示瀏覽器緩存信息,這意味著下次用戶輸入短URL時,瀏覽器會自動重定向到長URL而不需要再次訪問服務器。
然而,如果你想跟蹤每個請求的分析并確保它通過你的系統(tǒng),可以使用302狀態(tài)碼。
數(shù)據(jù)庫:存儲短URL
下一部分是數(shù)據(jù)庫層。該層存儲短URL和長URL之間的映射。它應該針對快速讀寫操作進行優(yōu)化。
模式可以很簡單:短URL id的主鍵,以及長URL和可能的創(chuàng)建元數(shù)據(jù)字段。
{
"shortUrlId": "3ad32p9",
"longUrl": "https://example.com/very-long-url",
"creationDate": "2024-03-08T12:00:00Z",
"userId": "user123",
"clicks": 1023,
"metadata": {
"title": "Example Web Page",
"tags": ["example", "web", "url shortener"],
"expireDate": "2025-03-08T12:00:00Z"
},
"isActive": true
}在這里,我們主要需要考慮數(shù)據(jù)庫的讀取次數(shù)。如果我們通常每秒有1000次寫入,那么我們可以假設至少每秒有10到100000次讀取。
在這種情況下,我們需要使用支持快速讀取和寫入的高性能數(shù)據(jù)庫。這意味著我們需要使用NoSQL數(shù)據(jù)庫(如MongoDB這樣的文檔存儲、Cassandra這樣的寬列存儲或DynamoDB這樣的鍵值存儲),因為它們專門設計用于處理大量的擴展。

它不會是ACID兼容的,但我們不關心這一點,因為我們不會進行大量的JOIN或復雜的查詢,我們不需要那些ACID規(guī)則和原子事務。
URL短鏈接服務
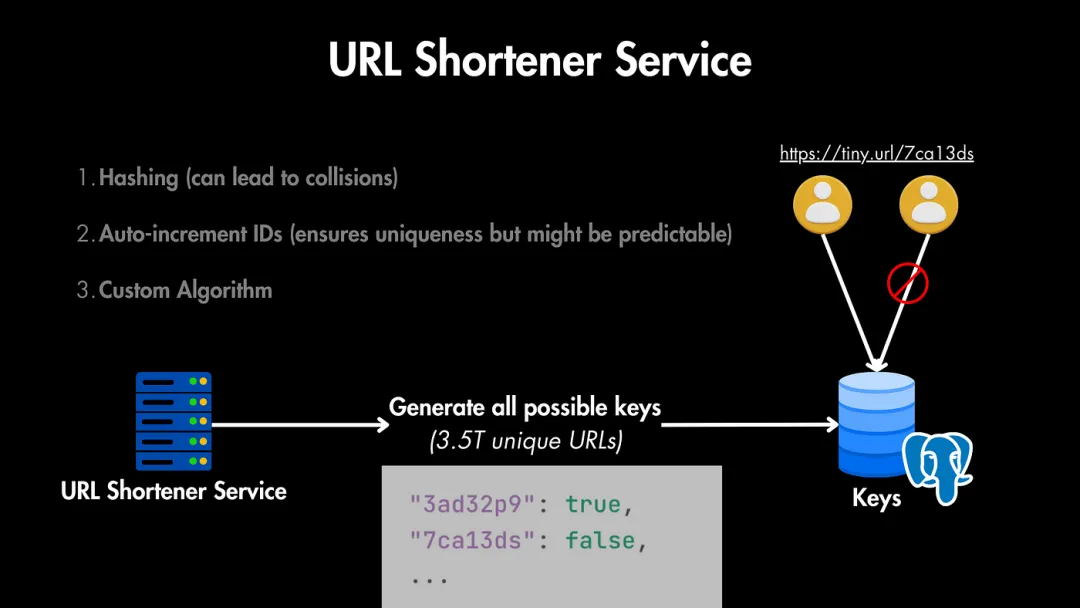
該系統(tǒng)的核心部分之一是URL短鏈接服務。該服務生成短URL,且不會在不同的長URL指向相同的短URL時引入沖突。
有多種方法可以實現(xiàn)這個服務;以下是其中一些:
- 哈希:生成長URL的哈希,并使用其中的一部分作為標識符。然而,哈希可能導致沖突。
- 自增ID:使用數(shù)據(jù)庫的自增ID并將其編碼為一個短字符串。這確保了唯一性,但可能是可預測的。
- 自定義算法:設計一個自定義算法,用字符的混合來生成唯一ID,以確保唯一性和不可預測性。
例如,為了避免沖突,有一個非常簡單的方法——我們可以生成
所有可能的7字符鍵,并將它們存儲在數(shù)據(jù)庫中作為鍵,其中鍵是生成的URL,值是布爾值;如果為true,則表示該URL已被使用,如果為false,則可以使用該URL創(chuàng)建新映射。
因此,每當用戶請求生成一個鍵時,我們可以從這個數(shù)據(jù)庫中找到一個當前未使用的URL,并將其映射到請求體中的長URL。
你認為我們在這種情況下會使用SQL還是NoSQL數(shù)據(jù)庫?考慮一種場景:兩個用戶請求縮短他們的長URL,并且他們都被映射到這個數(shù)據(jù)庫中的同一個鍵。
在這種情況下,URL將被映射到其中一個請求,另一個將被破壞。所以,我們將使用SQL,因為它具有ACID屬性。我們可以為這里的每個會話創(chuàng)建一個事務,以在隔離中執(zhí)行這些步驟,在這種情況下我們不會有這種問題。
高可用性和低延遲
我們的當前系統(tǒng)顯然無法處理每秒1000個URL的流量。
緩存
為了使其更具可擴展性,我們首先需要一個緩存層(例如Redis)來緩存流行的URL,以便在內(nèi)存中快速檢索。
鑒于某些URL可能比其他URL訪問頻率更高,我們需要一種優(yōu)先考慮頻繁訪問項的逐出策略。兩種適合此場景的緩存逐出策略是:
- LRU逐出策略:首先刪除最近最少訪問的項目。對于URL短鏈接服務,這種策略非常有效,因為它確保緩存保持最新和最頻繁訪問的URL,這可以顯著減少流行鏈接的訪問時間。
- 或者基于TTL的逐出策略:為每個緩存條目分配一個固定的生存時間(TTL)。一旦條目的TTL過期,它將從緩存中移除。對于只在短時間內(nèi)流行的URL,TTL策略對URL短鏈接服務很有用。
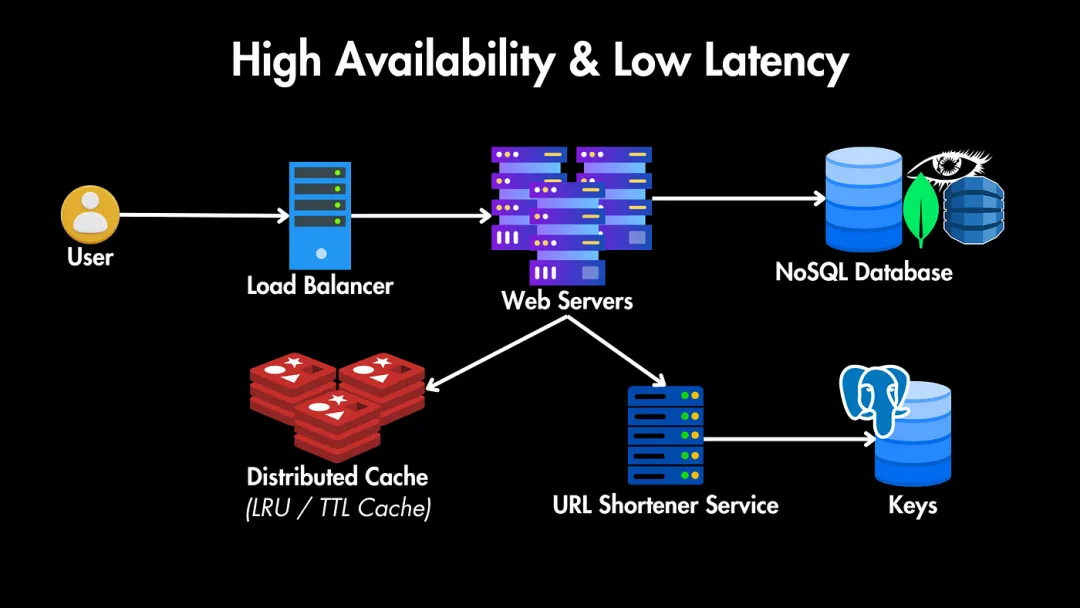
TTL還可以幫助我們自動刷新緩存內(nèi)容,并可以與其他策略(如LRU)結合使用,以更有效地管理緩存。
數(shù)據(jù)庫擴展:結合復制和分片
我們需要實現(xiàn)復制和分片策略,以確保數(shù)據(jù)庫支持高可用性、容錯性和可擴展性。
考慮到我們的7字符集有3.5T個唯一URL,我們可以使用基于鍵的分片將URL記錄均勻分布在多個分片上。
假設我們將其分布在3個分片上,每個分片將存儲大約1.16T個URL。這確保了隨著URL數(shù)量的增長系統(tǒng)的可擴展性。
我們還可以在每個分片內(nèi)實現(xiàn)主從復制,以確保高可用性和容錯性。這種設置允許在節(jié)點故障時快速故障轉移和恢復。
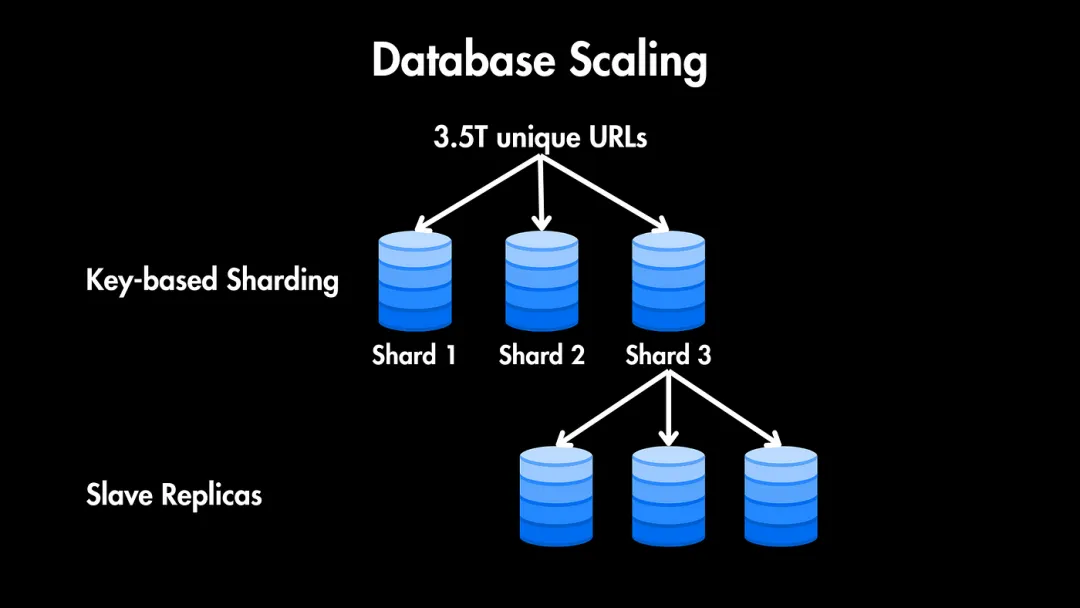
另外,如果服務面向全球用戶,我們可以考慮地理分片和復制,以最小化延遲并改善不同地區(qū)的用戶體驗。
這種組合允許服務處理大量URL縮短和重定向,并且?guī)缀鯖]有停機時間和快速響應時間。
安全考慮
以下是我們服務的一些安全考慮:
- 輸入驗證:我們必須對用戶提交的每個URL進行消毒。我們必須檢查有效的協(xié)議(HTTP、HTTPS等)并確保URL格式正確。這有助于防止注入攻擊。
- 速率限制:我們可以通過限制單個源的請求次數(shù)來保護我們的服務免受DDoS攻擊。可以考慮使用令牌桶算法。
- 監(jiān)控和日志記錄:需要一個強大的日志記錄系統(tǒng)(如ELK堆棧)。它允許我們分析日志以查找瓶頸和可疑活動,并確保整體系統(tǒng)健康。
- 混淆:我們不希望輕易預測的短URL。為了阻止攻擊者猜測有效鏈接,我們可以在生成算法中添加隨機性。
- 鏈接到期:可選地,我們可以考慮允許用戶為他們的短URL設置到期日期。這可以限制潛在惡意鏈接的生命周期。


























