小紅書圖數(shù)據(jù)庫在分布式并行查詢上的探索
一、背景介紹
1. 圖數(shù)據(jù)庫介紹

關(guān)于圖數(shù)據(jù)庫的概念,這里不作詳細(xì)闡述。而是以圖表的形式,對其與另外幾種 NoSQL 產(chǎn)品進(jìn)行比較。圖數(shù)據(jù)庫本身歸屬于 NoSQL 存儲,而諸如KV 類型、寬表類型、文檔類型、時序類型等其他 NoSQL 產(chǎn)品,各自具備獨(dú)特的特性。從上圖左側(cè)的坐標(biāo)軸中可以看到,從 KV 到寬表、文檔,再到圖,數(shù)據(jù)關(guān)聯(lián)度和查詢復(fù)雜度是越來越高的。前三者,即 KV、寬表和文檔,主要關(guān)注的是單個記錄內(nèi)部的豐富性,但并未涉及記錄間的關(guān)系。而圖數(shù)據(jù)庫則專注于處理這些關(guān)系。圖數(shù)據(jù)庫主要適用于需要挖掘深鏈路或多維度關(guān)系的業(yè)務(wù)場景。

接下來通過一個具體示例,再來對比一下圖數(shù)據(jù)庫與關(guān)系型數(shù)據(jù)庫。這是社交網(wǎng)絡(luò)中常見的一種表結(jié)構(gòu),包括四個數(shù)據(jù)表:用戶表、好友關(guān)系表、點(diǎn)贊行為表以及筆記詳情表。比如要查詢 Tom 這個用戶的好友所點(diǎn)贊的筆記的詳細(xì)信息,那么可能需要編寫一段冗長的 SQL 語句。在該 SQL 語句中,涉及到三個 join 操作,首先將用戶表和好友關(guān)系表進(jìn)行連接,從而獲取 Tom 的所有好友信息。然后,將得到的中間結(jié)果與點(diǎn)贊行為表進(jìn)行連接,以確定 Tom 的好友都點(diǎn)贊了哪些筆記。最后,還需要對先前生成的臨時表和筆記詳情表進(jìn)行連接,以便最終獲取這些筆記的全部內(nèi)容。
關(guān)系型數(shù)據(jù)庫中的 join 操作通常復(fù)雜度較高,其執(zhí)行過程中需消耗大量的 CPU 資源、內(nèi)存空間以及 IO,雖然我們可以通過精心的設(shè)計,例如針對所要關(guān)聯(lián)的列創(chuàng)建索引,以降低掃描操作的比例,通過索引匹配來實(shí)現(xiàn)一定程度的性能提升。然而,這樣的舉措所產(chǎn)生的成本相對較高,因?yàn)樗行碌膱鼍岸夹枰獎?chuàng)建索引,要考慮如何撰寫 SQL 中的 join 條件,選擇哪個表作為驅(qū)動表等等,這些都需要耗費(fèi)大量的精力和時間。
而如果采用圖數(shù)據(jù)庫,則會簡單很多。首先進(jìn)行圖建模,創(chuàng)建兩類頂點(diǎn),分別為用戶和筆記,同時創(chuàng)建兩類邊,一類是好友關(guān)系,即用戶到用戶的邊;另一類是用戶到筆記的點(diǎn)贊關(guān)系。當(dāng)我們將這些數(shù)據(jù)存儲到圖數(shù)據(jù)庫中時,它們在邏輯上呈現(xiàn)出一種網(wǎng)狀結(jié)構(gòu),其關(guān)聯(lián)關(guān)系已經(jīng)非常明確。查詢時,如上圖中使用 Gremlin 語句,僅需四行代碼即可獲取到所需的信息。其中第一行 g.V().has('name', 'Tom'),用于定位 Tom 節(jié)點(diǎn),兩個 out 子句,第一個 out 子句用于查找 Tom 的好友,第二個 out 子句用于查找 Tom 的點(diǎn)贊筆記。當(dāng)?shù)诙€ out 子句執(zhí)行完畢后,就可以遍歷所有外部的綠色頂點(diǎn),即筆記節(jié)點(diǎn)。最后,讀取它們的 content 屬性。可以發(fā)現(xiàn),與關(guān)系型數(shù)據(jù)庫相比,圖數(shù)據(jù)庫的查詢語句更加簡潔、清晰易懂。
此外,圖數(shù)據(jù)庫還有一個更為顯著的優(yōu)勢,就是在存儲時,它已經(jīng)將頂點(diǎn)及其關(guān)系作為一等公民進(jìn)行設(shè)計和存儲,因此在進(jìn)行鄰接邊訪問和關(guān)系提取時,效率極高。即使數(shù)據(jù)規(guī)模不斷擴(kuò)大,也不會導(dǎo)致查詢時間顯著增加。
2. 圖數(shù)據(jù)庫在小紅書的使用場景

小紅書是一個年輕的生活方式共享平臺。在小紅書,用戶可以通過短視頻、圖片等方式,直觀地記錄生活的點(diǎn)點(diǎn)滴滴。在小紅書內(nèi)部,圖數(shù)據(jù)庫被廣泛應(yīng)用于多種場景中,下面將分別列舉在線、近線以及離線場景的實(shí)例。
第一個案例是社交實(shí)時推薦功能。小紅書具有典型的社區(qū)特性,用戶可以在其中點(diǎn)贊、發(fā)布貼文、關(guān)注他人、轉(zhuǎn)發(fā)信息等。譬如我進(jìn)入某用戶主頁并停留了較長時間,那么系統(tǒng)便會判定我對該用戶有興趣,而這個用戶可能同樣吸引了他人的注意。因此,系統(tǒng)會將該用戶的其他關(guān)注者以及他們所關(guān)注的其他用戶推薦給我,因?yàn)槲覀冇泄餐呐d趣愛好,所以他們的關(guān)注內(nèi)容我也有可能感興趣,這便是一種簡單的實(shí)時推薦機(jī)制。
第二個案例是社區(qū)風(fēng)控機(jī)制,小紅書社區(qū)會對優(yōu)質(zhì)筆記或優(yōu)質(zhì)視頻的創(chuàng)作者進(jìn)行獎勵,但這也給了一些羊毛黨可乘之機(jī),他們發(fā)布一些質(zhì)量較低的帖子或筆記,將其發(fā)布在互刷群中,或者轉(zhuǎn)發(fā)給親朋好友,讓他們點(diǎn)贊和轉(zhuǎn)發(fā),從而偽裝成所謂的高質(zhì)量筆記,以此來騙取平臺的獎勵。社區(qū)業(yè)務(wù)部門擁有一些離線算法,能夠?qū)σ延械臄?shù)據(jù)進(jìn)行分析,識別出哪些用戶和筆記屬于作弊用戶,在圖中用紅色的點(diǎn)標(biāo)出。在近線場景中,系統(tǒng)會判斷每個頂點(diǎn)在多跳關(guān)系內(nèi)接觸到的作弊用戶的數(shù)量或比例,如果超過一定的閾值,則會將這個人標(biāo)記為潛在的風(fēng)險用戶,即黃色的頂點(diǎn),進(jìn)而采取防范措施。
第三個案例是離線任務(wù)的調(diào)度問題,在大數(shù)據(jù)平臺中,往往存在大量的離線任務(wù),而任務(wù)之間的依賴關(guān)系錯綜復(fù)雜,如何合理地調(diào)度任務(wù),成為一個棘手的問題。圖結(jié)構(gòu)非常適合解決這類問題,通過拓?fù)渑判蚧蚱渌惴ǎ梢哉页鲎钍芤蕾嚨娜蝿?wù),并進(jìn)行反向推理。
3. 業(yè)務(wù)上面臨的困境
小紅書在社交、風(fēng)控及離線任務(wù)調(diào)度等場景中均采用了圖數(shù)據(jù)庫,然而在實(shí)際應(yīng)用過程中遇到了諸多挑戰(zhàn)。在此,簡要介紹其中基于實(shí)時推薦場景的一個痛點(diǎn)。

業(yè)務(wù)訴求是能即時向用戶推送可能感興趣的“好友”或“內(nèi)容”,如圖所示,A 與 F 之間僅需經(jīng)過三次跳躍即可到達(dá),因此 A 與 F 構(gòu)成了一種可推薦的關(guān)聯(lián)關(guān)系,如果能即時完成此推薦,則能有效提升用戶使用體驗(yàn),提升留存率。然而,由于先前 REDgraph 在某些方面的能力尚未完善,業(yè)務(wù)一直只采用了一跳和兩跳查詢,未使用三跳,風(fēng)控場景也是類似。
業(yè)務(wù)對時延的具體要求為,社交推薦要求三跳的 P99 低于 50 毫秒,風(fēng)控則要求三跳的 P99 低于 200 毫秒,這是目前 REDgraph 所面臨的一大難題。
那為何一至二跳可行,三跳及以上就難以實(shí)現(xiàn)呢?對此,我們基于圖數(shù)據(jù)庫與其他類型系統(tǒng)在工作負(fù)載的差異,做了一些難點(diǎn)與可行性分析。

首先在并發(fā)方面,OLTP 的并發(fā)度很高,而 OLAP 則相對較低。圖的三跳查詢,服務(wù)的仍然是在線場景,其并發(fā)度也相對較高,這塊更貼近 OLTP 場景。
其次在計算復(fù)雜度方面,OLTP 場景中的查詢語句較為簡單,包含一到兩個 join 操作就算是較為復(fù)雜的情況了,因此,OLTP 的計算復(fù)雜度相對較低。OLAP 則是專門為計算設(shè)計的,因此其計算復(fù)雜度自然較高。圖的三跳查詢則介于 OLTP 和 OLAP 之間,它雖不像 OLAP 那樣需要執(zhí)行大量的計算,但其訪問的數(shù)據(jù)量相對于 OLTP 來說還是更可觀的,因此屬于中等復(fù)雜度。
第三,數(shù)據(jù)時效性方面,OLTP 對時效性的要求較高,必須基于最新的數(shù)據(jù)提供準(zhǔn)確且實(shí)時的響應(yīng)。而在 OLAP 場景中則沒有這么高的時效要求,早期的 OLAP 數(shù)據(jù)庫通常提供的是 T+1 的時效。圖的三跳查詢,由于我們服務(wù)的是在線場景,所以對時效性有一定的要求,但并不是非常高。使用一小時或 10 分鐘前的狀態(tài)進(jìn)行推薦,也不會產(chǎn)生過于嚴(yán)重的后果。因此,我們將其定義為中等時效性。
最后,查詢失敗代價方面。OLTP 一次查詢的成本較低,因此其失敗的代價也低;而 OLAP 由于需要消耗大量的計算資源,因此其失敗代價很高。圖查詢在這塊,更像 OLTP 場景一些,但畢竟訪問的數(shù)據(jù)量較大,因此同樣歸屬到中等。
總結(jié)一下:圖的三跳查詢具備 OLTP 級別的并發(fā)度,卻又有比一般 OLTP 大得多的數(shù)據(jù)訪問量和計算復(fù)雜度,所以比較難在在線場景中使用。好在其對數(shù)據(jù)時效性的要求沒那么高,也能容忍一些查詢失敗,所以我們能嘗試對其優(yōu)化。
正如前面提到的,在小紅書,三跳查詢的首要目標(biāo)還是降低延遲。有些系統(tǒng)中會考慮犧牲一點(diǎn)時延來換取吞吐的大幅提升,而這在小紅書業(yè)務(wù)上是不可接受的。如果吞吐上不去,還可以通過擴(kuò)大集群規(guī)模來兜底,而如果時延高則直接不能使用了。
二、原架構(gòu)問題分析
第二部分將詳述原體系結(jié)構(gòu)中所存在的問題及其優(yōu)化措施。
1. RedGraph 整體架構(gòu)

REDgraph 的整體結(jié)構(gòu)如上圖所示,其與當(dāng)前較為流行的 NewSQL,如 TiDB 的架構(gòu)構(gòu)相似。采用了存儲和計算分離的架構(gòu),并且存儲是 shared-nothing 的。三類節(jié)點(diǎn)分別為 meta-server,元信息的管理;query-server,用戶查詢請求的處理;store-server,存儲數(shù)據(jù)。
2. RedGraph 圖切分方式

圖切分的含義為,如果我們擁有一個巨大的圖,規(guī)模在百億到千億水平,應(yīng)該如何將其存儲在分布式集群之中,以及如何對其進(jìn)行切分。在工業(yè)界中,主要存在兩種典型的切分策略,即邊切分和點(diǎn)切分。
邊切分,以頂點(diǎn)為中心,這種切分策略的核心思想是每個頂點(diǎn)會根據(jù)其 ID 進(jìn)行哈希運(yùn)算,并將其路由到特定的分片上。每個頂點(diǎn)上的每條邊在磁盤中都會被存儲兩份,其中一份與起點(diǎn)位于同一分片,另一份則與終點(diǎn)位于同一分片。如上圖中的例子,其中涉及到 ABC 三個頂點(diǎn)的哈希定位結(jié)果。在這個例子中,A 至 C 的這條出邊,被放置在與 A 同一個節(jié)點(diǎn)上。同樣,B 至 C 的出邊跟 B 放到了一起,最后一個桶中保存了 C 以及 C 的入邊,即由 A 和 B 指向 C 的兩條入邊。
點(diǎn)切分,與邊切分相對應(yīng),以邊為中心,每個頂點(diǎn)會在集群內(nèi)保存多份。
這兩種切分方式各有利弊。邊切分的優(yōu)點(diǎn)在于每個頂點(diǎn)與其鄰居都保存在同一個分片中,因此當(dāng)需要查詢某個頂點(diǎn)的鄰居時,其訪問局部性極佳;其缺點(diǎn)在于容易負(fù)載不均,且由于節(jié)點(diǎn)分布的不均勻性,引發(fā)熱點(diǎn)問題。點(diǎn)切分則恰恰相反,其優(yōu)點(diǎn)在于負(fù)載較為均衡,但缺點(diǎn)在于每個頂點(diǎn)會被切成多個部分,分配到多個機(jī)器上,因此更容易出現(xiàn)同步問題。
REDgraph 作為一個在線的圖查詢系統(tǒng),選擇的是邊切分的方案。
3. 優(yōu)化方案 1.0

我們之前已經(jīng)實(shí)施了一些優(yōu)化,可以稱之為優(yōu)化方案 1.0。當(dāng)時主要考慮的是如何快速滿足用戶需求,因此我們的方案包括:首先根據(jù)常用的查詢模式提供一些定制化的算法,這些算法可以跳過解析、校驗(yàn)、優(yōu)化和執(zhí)行等繁瑣步驟,直接處理請求,從而實(shí)現(xiàn)加速。其次,我們會對每個頂點(diǎn)的扇出操作進(jìn)行優(yōu)化,即每個頂點(diǎn)在向外擴(kuò)展時,對其擴(kuò)展數(shù)量進(jìn)行限制,以避免超級點(diǎn)的影響,降低時延。此外,我們還完善了算子的下推策略,例如 filter、sample、limit 等,使其盡可能在存儲層完成,以減少網(wǎng)絡(luò)帶寬的消耗。同時,我們還允許讀從節(jié)點(diǎn)、讀寫線程分離、提高垃圾回收頻率等優(yōu)化。
然而,這些優(yōu)化策略有一個共性,就是每個點(diǎn)都比較局部化和零散,因此其通用性較低。比如第一個優(yōu)化,如果用戶需要發(fā)起新的查詢模式,那么此前編寫的算法便無法滿足其需求,需要另行編寫。第二個優(yōu)化,如果用戶所需要的是頂點(diǎn)的全部結(jié)果,那此項也不再適用。第三個優(yōu)化,如果查詢中本身就不存在這些運(yùn)算符,那么自然也無法進(jìn)行下推操作。諸如此類,通用性較低,因此需要尋找一種更為通用,能夠減少重復(fù)工作的優(yōu)化策略。
4. 新方案思考

如上圖中,是對一個耗時接近一秒的三跳查詢的 profile 分析。我們發(fā)現(xiàn)在每一跳產(chǎn)出的記錄數(shù)量上,第一跳至第二跳擴(kuò)散了 200 多倍,第二跳至第三跳擴(kuò)散了 20 多倍,表現(xiàn)在結(jié)果上,需要計算的數(shù)據(jù)行數(shù)從 66 條直接躍升至 45 萬條,產(chǎn)出增長速度令人驚訝。此外,我們發(fā)現(xiàn)三跳算子在整個查詢過程中占據(jù)了較大的比重,其在查詢層的耗時更是占據(jù)了整個查詢的 80% 以上。
那么應(yīng)該如何進(jìn)行優(yōu)化呢?在數(shù)據(jù)庫性能優(yōu)化方面,有許多可行的方案,主要分為三大類:存儲層的優(yōu)化、查詢計劃的優(yōu)化以及執(zhí)行引擎的優(yōu)化。
由于耗時大頭在查詢層,所以我們重點(diǎn)關(guān)注這塊。因?yàn)椴樵冇媱澋膬?yōu)化是一個無止境的工程,用戶可能會寫出各種查詢語句,產(chǎn)生各種算子,難以找到一個通用且可收斂的方案來覆蓋所有情況。而執(zhí)行引擎則可以有一個相對固定的優(yōu)化方案,因此我們優(yōu)先選擇了優(yōu)化執(zhí)行引擎。
圖數(shù)據(jù)庫的核心就是多跳查詢執(zhí)行框架,而其由于數(shù)據(jù)量大,計算量大,導(dǎo)致查詢時間較長,因此我們借鑒了 MPP 數(shù)據(jù)庫和其他計算引擎的思想,提出了分布式并行查詢的解決方案。

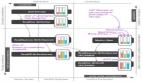
原有的多跳查詢執(zhí)行流程如上圖所示。假設(shè)我們要查詢933 頂點(diǎn)的三跳鄰居節(jié)點(diǎn) ID,即檢索到藍(lán)圈中的所有頂點(diǎn)。經(jīng)過查詢層處理后,將生成右圖所示執(zhí)行計劃,START 表示計劃的起點(diǎn),本身并無實(shí)際操作。GetNeighbor 算子則負(fù)責(zé)實(shí)際查詢頂點(diǎn)的鄰居,例如根據(jù) 933 找到 A 和 B。后續(xù)的 Project、InnerJoin 以及 Project 等操作均為對先前產(chǎn)生的結(jié)果進(jìn)行數(shù)據(jù)結(jié)構(gòu)的轉(zhuǎn)換、處理及裁剪等操作,以確保整個計算流程的順利進(jìn)行。正是后續(xù)的這幾個算子耗費(fèi)的時延較高。

算子的物理執(zhí)行過程如上圖所示。查詢服務(wù)器(Query Server)執(zhí)行 START 指令后,將請求發(fā)送至存儲節(jié)點(diǎn)(Store Server)中的一個,該節(jié)點(diǎn)獲取其鄰居信息,并反饋至查詢層。查詢層接收到結(jié)果后,會對其中的數(shù)據(jù)進(jìn)行去重或其他相關(guān)處理,然后再次下發(fā),此次的目標(biāo)是另外兩個 Store Server。這一步驟即為獲取二度鄰居的信息,返回至查詢層后,再對這些結(jié)果進(jìn)行匯總和去重處理,如此往復(fù)。
在整個流程中,我們明顯觀察到三個問題。首先,圖中藍(lán)色方框內(nèi)的算子都是串行運(yùn)行的,必須等待前一個計算完成后,才能執(zhí)行下一個。對于大規(guī)模的數(shù)據(jù),串行執(zhí)行的效率顯然無法與并行執(zhí)行相提并論。其次,Query Server 內(nèi)部存在一個同步點(diǎn),即左側(cè)標(biāo)注為紅色的字(等待所有響應(yīng)返回),要求 query Server 等待所有存儲節(jié)點(diǎn)的響應(yīng)返回后,才能繼續(xù)執(zhí)行后續(xù)操作。若某一存儲節(jié)點(diǎn)的數(shù)據(jù)量較大或負(fù)載過高,導(dǎo)致響應(yīng)速度較慢,則會耗費(fèi)大量時間在等待上,因此我們考慮取消同步等待的過程。最后,存儲層的結(jié)果需要先轉(zhuǎn)發(fā)回查詢層進(jìn)行簡單處理,然后再向下發(fā)送,這無疑增加了不必要的轉(zhuǎn)發(fā)成本。如果存儲節(jié)點(diǎn)(Store Server)能夠自行轉(zhuǎn)發(fā),便可避免一次網(wǎng)絡(luò)轉(zhuǎn)發(fā)過程,從而降低開銷。
相應(yīng)的解決策略便是三點(diǎn):算子并行執(zhí)行,取消同步點(diǎn),以及讓 Store Server 的結(jié)果直接轉(zhuǎn)發(fā)。基于此,我們提出了如下的改造思路。

首先,查詢服務(wù)器(Query Server)將整個執(zhí)行計劃以及執(zhí)行計劃所需的初始數(shù)據(jù)傳輸至存儲服務(wù)器(Store Server),之后 Store Server 自身來驅(qū)動整個執(zhí)行過程。以 Store Server 1 為例,當(dāng)它完成首次查詢后,便會根據(jù)結(jié)果 ID 所在的分區(qū),將結(jié)果轉(zhuǎn)發(fā)至相應(yīng)的 Store Server。各個 Store Server 可以獨(dú)立地繼續(xù)進(jìn)行后續(xù)操作,從而實(shí)現(xiàn)整個執(zhí)行動作的并行化,并且無同步點(diǎn),也無需額外轉(zhuǎn)發(fā)。
需要說明的是,圖中右側(cè)白色方框比左側(cè)要矮一些,這是因?yàn)閿?shù)據(jù)由上方轉(zhuǎn)到下方時,進(jìn)行了分區(qū)下發(fā),必然比在查詢服務(wù)器接收到的總數(shù)據(jù)量要少。
可以看到,在各部分獨(dú)立驅(qū)動后,并未出現(xiàn)等待或額外轉(zhuǎn)發(fā)的情況,Query Server 只需在最后一步收集各個 Store Server 的結(jié)果并聚合去重,然后返回給客戶端。如此一來,整體時間相較于原始模型得到了顯著縮短。
三、分布式并行查詢實(shí)現(xiàn)
分布式并行查詢的具體實(shí)現(xiàn),涉及到多個關(guān)鍵元素。接下來介紹其中一些細(xì)節(jié)。
1. 如何保證不對 1-2 跳產(chǎn)生負(fù)優(yōu)化

首先一個問題是,在進(jìn)行改造時如何確保不會對原始的 1-2 跳產(chǎn)生負(fù)優(yōu)化。在企業(yè)內(nèi)部進(jìn)行新的改造和優(yōu)化時,必須謹(jǐn)慎評估所采取的措施是否會對原有方案產(chǎn)生負(fù)優(yōu)化。我們不希望新方案還未能帶來收益,反而破壞了原有的系統(tǒng)。因此,架構(gòu)總體上與原來保持一致。在 Store Server 內(nèi)部插入了一層,稱為執(zhí)行層,該層具有網(wǎng)絡(luò)互聯(lián)功能,主要用于分布式查詢的轉(zhuǎn)發(fā)。Query Server 層則基本保持不變。
這樣,當(dāng)接收到用戶的執(zhí)行計劃后,便可根據(jù)其跳數(shù)選擇不同的處理路徑。若為 1 至 2 跳,則仍沿用原有的流程,因?yàn)樵械牧鞒棠軌驖M足 1-2 跳的業(yè)務(wù)需求,而 3 跳及以上則采用分布式查詢。
2. 如何與原有執(zhí)行框架兼容

第二個關(guān)鍵問題是如何維持與原有執(zhí)行框架的兼容性,即在進(jìn)行分布式技術(shù)改造時,不希望對原有代碼進(jìn)行大幅修改,而希望通過最小化的調(diào)整達(dá)到目的。這里參考了其他產(chǎn)品的一些思路,具體來說,就是在一些需要切換分區(qū)訪問的算子(如 GetNeighbor 等)之前,添加具有路由功能的算子。這里有三種,分別為 Forward、Converge 和 Merge。Forward 的作用顯而易見,即當(dāng)遇到任何運(yùn)算符時,表示數(shù)據(jù)需要轉(zhuǎn)發(fā)給其他節(jié)點(diǎn)處理,而當(dāng)前節(jié)點(diǎn)無法繼續(xù)處理。Converge 運(yùn)算符則是在整個執(zhí)行計劃的最后一步添加,用于指示最終結(jié)果應(yīng)返回至最初接收用戶請求的節(jié)點(diǎn)。在 Converge 后,還需添加一個 Merge 運(yùn)算符,該節(jié)點(diǎn)在收到結(jié)果后需要進(jìn)行聚合操作,然后才能將結(jié)果返回給客戶端。如此修改后,我們只需實(shí)現(xiàn)這三個算子本身,無需對其他算子進(jìn)行任何修改,且不會對網(wǎng)絡(luò)層造成干擾,實(shí)現(xiàn)了極輕量級的改造。在執(zhí)行計劃修改的過程中,我們還進(jìn)行了一些額外的優(yōu)化,例如將 GroupBy、OrderBy 等算子也進(jìn)行了下推處理。
3. 如何做熱點(diǎn)處理

第三問題是如何進(jìn)行熱點(diǎn)處理,或者說是重復(fù) ID 的處理。當(dāng)整個執(zhí)行流程改造成由 Store Server 自行驅(qū)動之后,會出現(xiàn)一種情況,例如邊 AC 和邊 BC 位于兩個不同的 Store Server 上,查詢都是單跳的操作,可能左側(cè)的機(jī)器查詢 AC 操作更快,而右側(cè)的機(jī)器查詢 BC 操作較慢,因此導(dǎo)致左側(cè)的機(jī)器首先查找到 C,然后將結(jié)果轉(zhuǎn)發(fā)給其他機(jī)器,向下一級中間機(jī)器查詢 C 的鄰居,即執(zhí)行 GetNeighbor from C,右側(cè)的節(jié)點(diǎn)雖然稍顯滯后,但也需要執(zhí)行查詢 C 鄰居操作。
若不進(jìn)行任何操作,在中間節(jié)點(diǎn)便會對 C 的鄰居進(jìn)行兩次查詢,造成資源浪費(fèi)。優(yōu)化策略非常簡單,即在每個存儲節(jié)點(diǎn)之上添加 NeighborCache。本質(zhì)是這樣一個 Map 結(jié)構(gòu),每當(dāng)讀請求到來時,首先在 Map 中查找是否存在 C 的鄰節(jié)點(diǎn),若存在則獲取,否則再訪問存儲層,訪問完畢后填充 NeighborCache 的條目,每個條目的生存時間都非常短暫。之所以短暫,其充分性在于左右節(jié)點(diǎn)發(fā)出請求的間隔肯定不會很久,不會達(dá)到數(shù)秒的級別,否則業(yè)務(wù)上也無法承受。因此,NeighborCache 的每個條目也只需存活在秒級,超過則自動刪除。必要性則在于 Map 的 Key 的組合模式,即 Vid+edgeType 這種組合模式還是非常多的,若不及時清理,內(nèi)存很容易爆炸。此外,查詢層從 Disk Store 中查詢到數(shù)據(jù)并向 NeighborCache 回填時,也需進(jìn)行內(nèi)存檢查,以避免 OOM。
4. 如何做負(fù)載均衡

第四個問題是怎么做負(fù)載均衡,包括兩塊,一個是存儲的均衡,另一個是計算的均衡。
首先存儲的均衡在以邊切分的圖存儲里面其實(shí)是很難的,因?yàn)樗烊坏木褪前秧旤c(diǎn)和其鄰居全部都存在了一起,這是圖數(shù)據(jù)庫相比其他數(shù)據(jù)庫的優(yōu)勢,也是其要承擔(dān)的代價。所以目前沒有一個徹底的解決方法,只能在真的碰到此問題時擴(kuò)大集群規(guī)模,讓數(shù)據(jù)的哈希打散能夠更加均勻一些,避免多個熱點(diǎn)都落在同一個機(jī)器的情況。而在目前的業(yè)務(wù)場景上來看,其實(shí)負(fù)載不均衡的現(xiàn)象不算嚴(yán)重,例如風(fēng)控的一個比較大的集群,其磁盤用量最高和最低的也不超過 10%,所以問題其實(shí)并沒有想象中的那么嚴(yán)重。
另外一個優(yōu)化方法是在存儲層及時清理那些過期的數(shù)據(jù),清理得快的話也可以減少一些不均衡。
計算均衡的問題。存儲層采用了三副本的策略,若業(yè)務(wù)能夠接受弱一致的讀取(實(shí)際上大多數(shù)業(yè)務(wù)均能接受),我們可以在請求轉(zhuǎn)發(fā)時,查看三副本中的哪個節(jié)點(diǎn)負(fù)載較輕,將請求轉(zhuǎn)發(fā)至該節(jié)點(diǎn),以盡量平衡負(fù)載。此外,正如前文所述,熱點(diǎn)結(jié)果緩存也是一種解決方案,只要熱點(diǎn)處理速度足夠快,計算的不均衡現(xiàn)象便不易顯現(xiàn)。
5. 如何做流程控制

接下來的問題是如何進(jìn)行流程控制。執(zhí)行流程轉(zhuǎn)變?yōu)橛?Store Server 自行驅(qū)動之后,僅第一個 Stage 有 Driver 參與,而后續(xù)步驟則由 Worker 之間相互傳輸和控制。那么,Driver 應(yīng)如何了解當(dāng)前執(zhí)行的階段以及其對應(yīng)的某個 Stage 何時可以開始執(zhí)行呢?有一種解決方案便是要求每一個 Worker 在接收到請求后或下發(fā)請求后,向 Driver 回傳一個響應(yīng),如此便可在 Driver 內(nèi)記錄所有節(jié)點(diǎn)的進(jìn)度信息,這是可行的。
然而,此設(shè)計方案較重,因?yàn)?driver 并不需要深入了解每個節(jié)點(diǎn)的具體狀態(tài),它僅需判斷自身是否具備執(zhí)行條件,因此在工程實(shí)現(xiàn)中,我們采取了更為輕便的方式,即每個 Stage 生成一個 32 位的二進(jìn)制數(shù)字 reqId,將其發(fā)送至 ACKer 確認(rèn)器以傳達(dá)相關(guān)信息。Acker 也以 32 位整數(shù)形式記錄該信息,Stage1 同樣會接收到 Stage 0 發(fā)來的 reqId,經(jīng)過內(nèi)部一系列處理后,它會將接收到的 reqId 與自身生成的 3 個 reqId 進(jìn)行異或運(yùn)算,并將異或結(jié)果再次發(fā)送至確認(rèn)器。由于異或操作的特性,當(dāng)兩個數(shù)相同時,結(jié)果為 0,因此,當(dāng) 0010 數(shù)進(jìn)行異或運(yùn)算后,這部分將變?yōu)?0。這就意味著 Stage 0 已經(jīng)執(zhí)行完畢。后續(xù)的所有階段均采用類似的方式,當(dāng)確認(rèn)器的結(jié)果再次變?yōu)?0 時,表示整個執(zhí)行流程已經(jīng)完成,即前面的 Stage 0 至 Stage 3 已經(jīng)讀取完畢,此時可以執(zhí)行 Stage 4,從而實(shí)現(xiàn)流程驅(qū)動。
另一個重要的問題便是全程鏈路的超時自檢,例如在 Stage2 或 Stage3 的某一個節(jié)點(diǎn)上運(yùn)行時間過長,此時不能讓其余所有節(jié)點(diǎn)一直等待,因?yàn)榭蛻舳艘呀?jīng)超時了。因此我們在每個算子內(nèi)部的執(zhí)行邏輯中都設(shè)置了一些埋點(diǎn),用以檢查算子的執(zhí)行是否超過了用戶側(cè)的限制時間,一旦超過,便立即終止自身的執(zhí)行,從而迅速地自我銷毀,避免資源的無謂浪費(fèi)。
以上就是對一些關(guān)鍵設(shè)計的介紹。
6. 性能測試
我們在改造工程完成后進(jìn)行了性能測試,采用 LDBC 組織提供的 SNB 數(shù)據(jù)集,生成了一個 SF100 級別的社交網(wǎng)絡(luò)圖譜,規(guī)模達(dá)到 3 億頂點(diǎn),18 億條邊。我們主要考察其一跳、二跳、三跳、四跳等多項查詢性能。

根據(jù)評估結(jié)果顯示,在一跳和二跳情況下,原生查詢和分布式查詢性能基本相當(dāng),未出現(xiàn)負(fù)優(yōu)化現(xiàn)象。從三跳起,分布式查詢相較于原生查詢能實(shí)現(xiàn) 50% 至 60% 的性能提升。例如,在 Max degree 場景下的分布式查詢已將時延控制在 50 毫秒以內(nèi)。在帶有 Max degree 或 Limit 值的情況下,時延均在 200 毫秒以下。盡管數(shù)據(jù)集與實(shí)際業(yè)務(wù)數(shù)據(jù)集存在差異,但它們皆屬于社交網(wǎng)絡(luò)領(lǐng)域,因此仍具有一定的參考價值。

四跳查詢,無論是原始查詢還是分布式查詢,其時延的規(guī)模基本上都在秒至十余秒的范圍內(nèi)。因?yàn)樗奶樵兩婕暗臄?shù)據(jù)量實(shí)在過于龐大,已達(dá)到數(shù)十萬甚至百萬級別,僅依賴分布式并行查詢難以滿足需求,因此需要采取其他策略。然而,即便如此,我們所提出的改進(jìn)方案相較于原始查詢模式仍能實(shí)現(xiàn) 50% 至 70% 的提升,效果還是很可觀的。
四、總結(jié)與展望

我們結(jié)合 MPP 的思想,成功地對原有 REDgraph 的執(zhí)行流程實(shí)現(xiàn)了框架級別上的革新,提出了一種較為通用的圖中分布式并行查詢方案。在完成改良后,至少在業(yè)務(wù)層面上,原本無法執(zhí)行的三跳任務(wù)現(xiàn)在得以實(shí)現(xiàn),這無疑是一項重大突破。同時,通過實(shí)驗(yàn)驗(yàn)證,效率得到了 50% 的顯著提升。

隨著小紅書 DAU 的持續(xù)攀升,業(yè)務(wù)數(shù)據(jù)規(guī)模正逐步向著萬億的規(guī)模發(fā)展。在這樣的大背景下,業(yè)務(wù)對多條查詢的需求也將日益強(qiáng)烈。因此,該方案本身具有優(yōu)化的潛力,具備落地的可能性,且有實(shí)際應(yīng)用的場景。因此,我們將繼續(xù)致力于提升 REDgraph 的查詢能力。另外,盡管該方案主要在圖數(shù)據(jù)庫上實(shí)施,但其思想對于其他具有類似重查詢需求的在線存儲系統(tǒng)同樣具有一定的參考價值。因此,其他產(chǎn)品也可借鑒此方案,設(shè)計出符合自身需求的高效執(zhí)行框架。
最后。我們誠摯地邀請對技術(shù)有著極致追求、志同道合的同學(xué)們加入我們的團(tuán)隊。在此,我們特別推薦兩個渠道:一是掃描上方二維碼加入微信群,共同探討圖數(shù)據(jù)庫相關(guān)的技術(shù)問題;二是關(guān)注小紅書的技術(shù)公眾號 REDtech,該公眾號會不定期發(fā)布技術(shù)文章,歡迎大家關(guān)注和轉(zhuǎn)發(fā)。
五、問答環(huán)節(jié)
Q:介紹中提到的 LDBC-SF 100 那個數(shù)據(jù)集選擇測試樣本的規(guī)模有多大?另外,分布式方式能夠提升性能,但分布式實(shí)施過程中可能會帶來消息通信的成本開支,反而可能導(dǎo)致測試結(jié)果表現(xiàn)不佳,可否介紹一下小紅書的解決方法。
A:三跳基本上都是在幾十萬的量級。
關(guān)于分布式引發(fā)的消息通信,這確實(shí)是一個問題,但在我們的場景下,目前這還不是最嚴(yán)重的問題。因?yàn)槊恳惶貏e是三跳中產(chǎn)生的數(shù)據(jù)量是巨大的,計算算子處理這些數(shù)據(jù)量所需的時間已經(jīng)遠(yuǎn)遠(yuǎn)超過了消息通信的耗時。尤其是在多跳并存的環(huán)境中,比如一跳和二跳,其實(shí)它們作為中間結(jié)果其數(shù)據(jù)量并不大,一跳只有幾十上百個,二跳可能也就幾萬個,但是三跳作為最后的需要參與計算的結(jié)果直接到了幾十萬,所以通信開銷跟這個比起來,其實(shí)是非常微小的。
在消息通信方面,我們也有一些解決思路,比如在發(fā)送端開一些很小的窗口(比如 5 毫秒)來做一些聚合,把那些目標(biāo)點(diǎn)相同的請求進(jìn)行聚合,這樣可以減少一些通信的請求次數(shù)。