大規模參數的更強、更魯棒的視覺基礎模型
本文經計算機視覺研究院公眾號授權轉載,轉載請聯系出處。
01 簡介
與最近關注large dense kernels的CNN不同,InternImage以可變形卷積為核心算子,使我們的模型不僅具有檢測和分割等下游任務所需的大有效感受野,而且具有受輸入和任務信息約束的自適應空間聚合。因此,所提出的InternImage減少了傳統CNNs嚴格歸納偏差,并使其能夠從像ViT這樣的海量數據中學習具有大規模參數的更強、更穩健的模式。我們的模型的有效性在ImageNet、COCO和ADE20K等具有挑戰性的基準測試中得到了驗證。值得一提的是,InternImage-H在COCO測試開發上獲得了創紀錄的65.4mAP,在ADE20K上獲得了62.9mIoU,優于目前領先的CNNs和ViTs。
02 背景
為了彌合CNNs和ViTs之間的差距,首先從兩個方面總結了它們的差異:(1)從操作員層面來看,ViTs的多頭自注意(MHSA)具有長程依賴性和自適應空間聚合(見圖(a)段)。得益于靈活的MHSA,ViT可以從海量數據中學習到比CNN更強大、更健壯的表示。(2) 從架構的角度來看,除了MHSA之外,ViTs還包含一系列未包含在標準CNN中的高級組件,如層歸一化(LN)、前饋網絡(FFN)、GELU等。

盡管最近的工作已經做出了有意義的嘗試,通過使用具有非常大內核(例如,31×31)的密集卷積將長程依賴引入到CNN中,如圖(c)所示,在性能和模型規模方面與最先進的大型ViT仍有相當大的差距。
03 新框架介紹
通過大規模參數(即10億)和訓練數據(即4.27億),InternImage-H的top-1準確率進一步提高到89.6%,接近well-engineering ViTs和混合ViTs。此外,在具有挑戰性的下游基準COCO上,最佳模型InternImage-H以21.8億個參數實現了最先進的65.4%的boxmAP,比SwinV2-G高2.3個點(65.4對63.1),參數減少了27%,如下圖所示。

為了設計一個基于CNN的大型基礎模型,我們從一個靈活的卷積變體開始,即DCNv2,并在此基礎上進行一些調整,以更好地適應大型基礎模型的要求。然后,通過將卷積算子與現代主干中使用的高級塊設計相結合來構建基本塊。最后,探索了基于DCN的塊的堆疊和縮放原理,以構建一個可以從海量數據中學習強表示的大規模卷積模型。

使用DCNv3作為核心帶來了一個新的問題:如何構建一個能夠有效利用核算子的模型?首先介紹了基本塊和模型的其他集成層的細節,然后我們通過探索這些基本塊的定制堆疊策略,構建了一個新的基于CNN的基礎模型,稱為InternImage。最后,研究了所提出的模型的放大規則,以從增加參數中獲得增益。
Basic block
與傳CNNs中廣泛使用的瓶頸不同,我們的基塊的設計更接近ViTs,它配備了更先進的組件,包括LN、前饋網絡(FFN)和GELU。這種設計被證明在各種視覺任務中是有效的。我們的基本塊的細節如上圖所示。其中核心算子是DCNv3,并且通過將輸入特征x通過可分離卷積(3×3深度卷積,然后是線性投影)來預測采樣偏移和調制尺度。對于其他組件,默認使用后規范化設置,并遵循與普通變壓器相同的設計。

Hyper-parameters for models of different scales
Scaling rules
在上述約束條件下的最優原點模型的基礎上,進一步探索了受[Efficientnet: Rethinking model scaling for convolutional neural networks]啟發的參數縮放規則。具體而言,考慮兩個縮放維度:深度D(即3L1+L3)和寬度C1,并使用α、β和復合因子φ縮放這兩個維度。
通過實驗發現,最佳縮放設置為α=1.09和β=1.36,然后在此基礎上構建具有不同參數尺度的InternImage變體,即InternImage-T/S/B/L/XL,其復雜性與ConvNeXt的相似。為了進一步測試該能力,構建了一個具有10億個參數的更大的InternImage-H,并且為了適應非常大的模型寬度,還將組維度C‘更改為32。上表總結了配置。
04 實驗&可視化
Object detection and instance segmentation performance on COCO val2017.
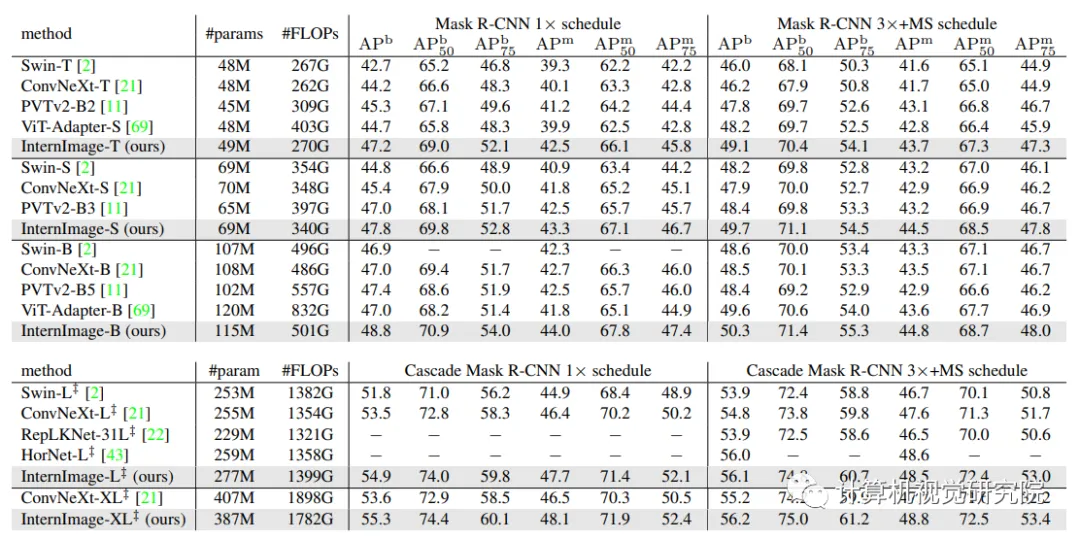
為了進一步提高目標檢測的性能,在ImageNet-22K或大規模聯合數據集上預先訓練的權重初始化主干,并通過復合技術將其參數翻倍。然后,在Objects365和COCO數據集上一個接一個地對其進行微調,分別針對26個epochs和12個epochs。如下表所示,新方法在COCO val2017和test-dev上獲得了65.0 APb和65.4 APb的最佳結果。與以前最先進的模型相比,比FD-SwinV2-G[26]高出1.2分(65.4比64.2),參數減少了27%,并且沒有復雜的蒸餾過程,這表明了新模型在檢測任務上的有效性。

共享權重的模型參數和GPU內存使用v.s卷積神經元之間的非共享權重。左縱軸表示模型參數,右縱軸表示批量大小為32且輸入圖像分辨率為224×224時每個圖像的GPU內存使用情況。

不同階段不同組的采樣位置可視化。藍色的星表示查詢點(在左邊的羊),不同顏色的點表示不同組的采樣位置。