YotoR:融合 Swin Transformer 和YoloR 的混合架構,提升目標檢測性能
本文經計算機視覺研究院公眾號授權轉載,轉載請聯系出處。

- 論文地址:https://arxiv.org/pdf/2405.19629
PART/1
摘要
Transformers是自然語言處理領域的一項革命性技術,它也對計算機視覺產生了重大影響,有可能提高準確性和計算效率。YotoR將堅固的Swin Transformer主干與YoloR頸部和頭部相結合。在實驗中,YotoR模型TP5和BP4在各種評估中始終優于YoloR P6和Swin Transformers,比Swin Transformer模型提供了改進的目標檢測性能和更快的推理速度。這些結果突出了進一步的模型組合和改進Transformer實時目標檢測的潛力。最后強調了YotoR的更廣泛含義,包括它在增強基于Transformer的圖像相關任務模型方面的潛力。
PART/2
背景&動機
在過去的十年里,卷積神經網絡徹底改變了計算機視覺應用,實現了目標檢測、圖像分割和實例分割等任務求解。盡管近年來卷積網絡主干得到了改進,甚至在一些任務上超過了人類的性能,但Transformer在計算機視覺任務中的使用在幾年內仍然難以捉摸。Transformer在計算機視覺任務中的首次應用于2020年提出。然而,由于圖像的高分辨率,Transformers的使用僅限于圖像分類等低分辨率應用。像物體檢測這樣的高分辨率任務需要開發更專業的Transformer架構,比如Swin Transformer,它通過動態改變注意力窗口來規避變形金剛的計算限制,并允許它們用作多視覺任務的通用主干。此外,基于DETR等Transformer的目標檢測頭在以前由卷積神經網絡主導的任務中已經成為最先進的。
另一方面,以Yolo/YoloR家族為例的實時目標檢測器對于依賴高幀率的任務(如自動駕駛)或受有限硬件資源限制的平臺上的任務仍然是必不可少的。盡管計算機視覺的Transformer最近取得了進展,但實時物體檢測主要依賴于卷積神經網絡。它們在特征提取中建立的可靠性和計算效率一直是Transformers需要克服的挑戰。然后,將Transformer與類Yolo目標檢測器相結合,可以提供能夠實現高幀率和高檢測精度的新型架構。
PART/3
新框架
多任務架構的使用前景看好,因為它們可以整合多種信息模態以提高所有任務的性能。然而,設計能夠在實時中執行多任務的建筑結構是具有挑戰性的,因為使用每個任務的網絡集合會負面影響系統的運行時間。

在這項工作中,引入了一系列網絡體系結構,將Swin Transformer主干與YoloR頭融合在一起。受Yolo命名法的啟發,這些架構被命名為YotoR:You Only Transform One Representation。這反映了使用由Transformer塊生成的單一統一表示,該表示通用且適用于多個任務。該提案背后的想法是使用強大的Swin Transformers特征提取來提高檢測精度,同時還能夠通過使用YoloR頭以快速推理時間解決多個任務。
Backbone
與YoloR及其基本模型P6之間的關系類似,YotoR TP4是YotoR模型的起點,代表了最基本的組件組合。使用不變的SwinT主干也有一個顯著的優勢,可以應用遷移學習技術。這是因為,通過不改變Swin Transformer的結構,可以使用其創建者公開提供的重量。這簡化了將預先訓練的Swin-Transformer權重轉移到其他數據集的過程,加快了訓練過程并提高了性能。

Head
為了構建YoloR模型,決定以Scaled YoloV4的架構為基礎。特別是,他們從YoloV4-P6光作為基礎開始,并依次對其進行修改,以創建不同版本的YoloR:P6、W6、E6和D6。這些版本之間的變化如下:
–YoloR-P6:用SiLU替換了YoloV4-P6-light的Mish激活功能
–YoloR-W6:增加了主干塊輸出中的通道數量
–YoloR-E6:將W6的通道數乘以1.25,并用CSP卷積代替下采樣卷積
–YoloR-D6:增加了骨干的深度
YotoRmodels
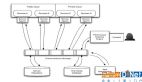
選擇YotoR模式進行實施涉及到兩個重要方面。首先,分析了Swin Transformer主干生成的特征金字塔尺寸與YoloR頭所需尺寸之間的差異。這些維度之間的顯著差異可能會在網絡中造成瓶頸,從而限制其性能。其次,為了調整連接,Swin Transformer的功能必須重新整形為帶有注意力圖的圖像。然后將其歸一化并通過1×1卷積來調整通道的數量。這樣做是為了使YoloR頭具有與DarknetCSP主干相同的功能大小,并軟化連接之間的信息瓶頸。

顯示了YotoR BP4體系結構。它介紹了STB(Swin Transformer Block),代表了不同YotoR架構中使用的Swin TransformerBlock。此外,在這些組件之間還包含一個線性嵌入塊。這個線性嵌入塊來自用于目標檢測的Swin Transformer實現,并在沒有更改的情況下被合并到YotoR實現中。之所以選擇這四個模型,是因為它們由YoloR和Swin Transformer的基本架構組成,從而可以進行有效的比較來評估所提出的模型的有效性。雖然考慮了對YotoR BW4或YotoR BW 5等大型模型進行訓練和評估,但V100 GPU的資源限制使此選項不可行。
PART/4
實驗及可視化
訓練參數:



左圖:val2017和testdev的圖片。右圖:YotoR BP4的預測。
與開始時的狀態比較(批次=1,GPU=V100)。*表示我們自己使用16GBV100GPU確認的測量結果