微調真的能讓LLM學到新東西嗎:引入新知識可能讓模型產生更多的幻覺
大型語言模型(llm)是在巨大的文本語料庫上訓練的,在那里他們獲得了大量的事實知識。這些知識嵌入到它們的參數中,然后可以在需要時使用。這些模型的知識在培訓結束時被“具體化”。在預訓練結束時,模型實際上停止學習。

對模型進行對齊或進行指令調優,讓模型學習如何充分利用這些知識,以及如何更自然地響應用戶的問題。但是有時模型知識是不夠的,盡管模型可以通過RAG訪問外部內容,但通過微調使模型適應新的領域被認為是有益的。這種微調是使用人工標注者或其他llm創建的輸入進行的,模型會遇到額外的事實知識并將其整合到參數中。
模型如何集成這些新的附加知識?
在機制層面上,我們并不真正知道這種相互作用是如何發生的。根據一些人的說法,接觸這種新知識可能會導致模型產生幻覺。這是因為模型被訓練成生成不以其預先存在的知識為基礎的事實(或者可能與模型的先前知識沖突)。模型還有可能會遇到罕見的知識(例如,在預訓練語料庫中較少出現的實體)。
因此,最近發表的一項研究關注的是分析當模型通過微調得到新知識時會發生什么。作者詳細研究了一個經過微調的模型會發生什么,以及它在獲得新知識后的反應會發生什么。
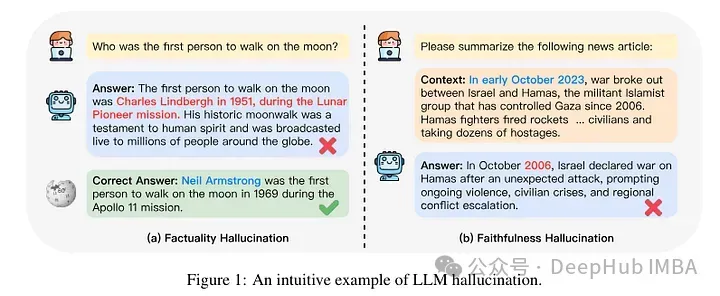
他們嘗試在微調后對示例進行知識級別的分類。一個新例子固有的知識可能與模型的知識不一致。例子可以是已知的,也可以是未知的。即使已知,它也可能是高度已知的,可能是已知的,或者是不太為人所知的知識。
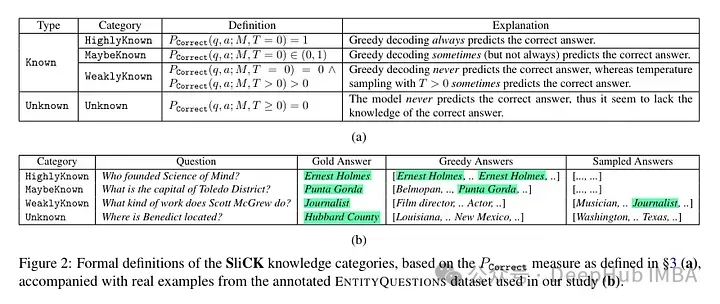
然后作者采用了一個模型(PaLM 2-M)對其進行了微調。每個微調的例子都是由事實知識構成的(主體、關系、對象)。這是為了允許模型用特定的問題、特定的三元組(例如,“巴黎在哪里?”)和基本事實答案(例如,“法國”)查詢這些知識。換句話說,它們為模型提供一些新知識,然后將這些三元組重構為問題(問答對)以測試其知識。他們將所有這些例子分成上述討論的類別,然后評估答案。
對模型進行了微調然后測試幻覺,得到了下面的結果:未知事實的高比例會導致性能下降(這不會通過更長的微調時間來補償)。
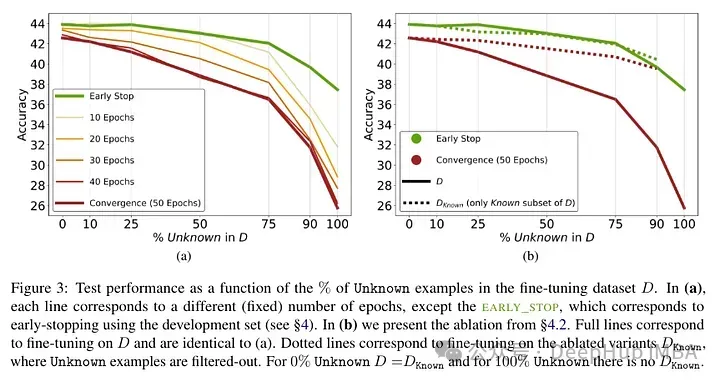
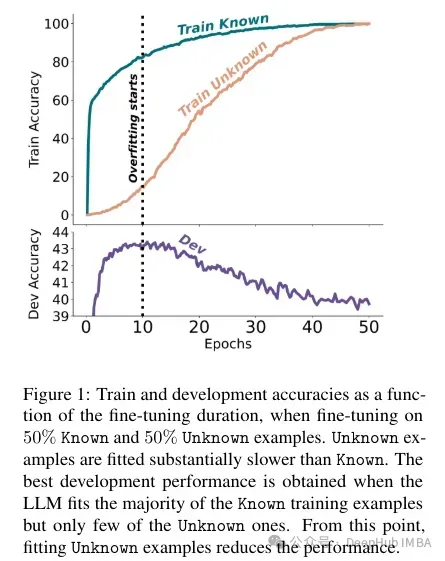
未知事實在較低的epoch數下幾乎是中性的影響,但在更多的epoch數下會損害性能。所以未知的例子似乎是有害的,但它們的負面影響主要體現在訓練的后期階段。下圖顯示了數據集示例的已知和未知子集的訓練精度作為微調持續時間的函數。可以看出,該模型在較晚階段學習了未知樣例。
Lastly, since Unknown examples are the ones that are likely to introduce new factual knowledge, their significantly slow fitting rate suggests that LLMs struggle to acquire new factual knowledge through fine-tuning, instead they learn to expose their preexisting knowledge using the Known examples.
作者嘗試對這種準確度與已知和未知例子之間的關系是進行量化,以及它是否是線性的。結果表明,未知的例子會損害性能,而已知的例子會提高性能,這之間存在很強的線性關系,幾乎同樣強烈(這種線性回歸中的相關系數非常接近)。
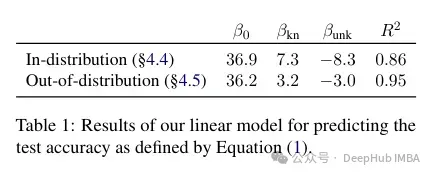
這種微調不僅對特定情況下的性能有影響,而且對模型知識有廣泛的影響。作者使用分布外(OOD)的測試集表明,未知樣本對OOD性能是有害的。根據作者的說法,這與幻覺的發生也有關系:
Overall, our insights transfer across relations. This essentially shows that fine-tuning on Unknown examples such as “Where is [E1] located?”, can encourage hallucinations on seemingly unrelated questions, such as “Who founded [E2]?”.
另外一個有趣的結果是,最好的結果不是用眾所周知的例子獲得的,而是用可能已知的例子。換句話說,這些例子允許模型更好地利用其先驗知識(過于眾所周知的事實不會對模型產生有用的影響)。
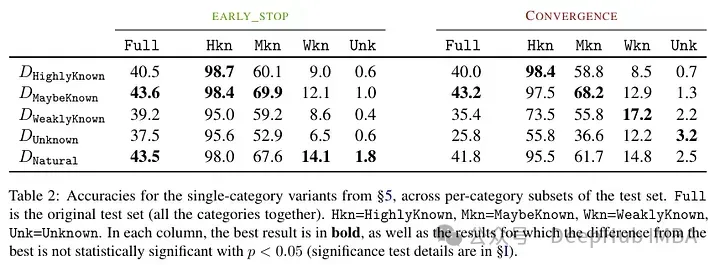
相比之下,未知和不太清楚的事實會損害模型的表現,而這種下降源于幻覺的增加。
This work highlights the risk in using supervised fine-tuning to update LLMs’ knowledge, as we present empirical evidence that acquiring new knowledge through finetuning is correlated with hallucinations w.r.t preexisting knowledge.
根據作者的說法,這種未知的知識可能會損害性能(這使得微調幾乎毫無用處)。而用“我不知道”標記這種未知知識可以幫助減少這種傷害。

Acquiring new knowledge via supervised fine-tuning is correlated with hallucinations w.r.t. pre-existing knowledge. LLMs struggle to integrate new knowledge through fine-tuning and mostly learn to use their pre-existing knowledge.
綜上所述,如果在微調過程中出現未知知識,則會對模型造成損害。這種性能下降與幻覺的增加有關。相比之下,可能已知的例子反而有有益的影響。這表明該模型難以整合新知識。也就是說在模型所學到的知識和它如何使用新知識之間存在沖突。這可能與對齊和指令調優有關(但是這篇論文沒有研究這一點)。
所以如果想要使用具有特定領域知識的模型,論文建議最好使用RAG。并且帶有“我不知道”標記的結果可以找到其他策略來克服這些微調的局限性。
這項研究是非常有意思,它表明微調的因素以及如何解決新舊知識之間的沖突仍然不清楚。這就是為什么我們要測試微調前和后結果的原因。