













ASCII、Unicode、UTF-8、utf8mb4,有啥區別?
什么是字符集?什么是編碼?什么是解碼?它們之間有什么關系?ASCII、Unicode、UTF-8、ISO-8859-1、GB2312,這些在計算中常見的名詞,它們代表的真正含義是什么?這篇文章幫你講透!

字符集
字符集(Character Set)是字符的一個集合,包含字母、數字、標點符號、控制字符、中文以及其他符號。常見的字符集包括:
- ASCII字符集(American Standard Code for Information Interchange,美國標準信息交換碼):總共 128個字符,包括英文字母、數字、一些特殊符號和控制字符
- ISO-8859-1:擴展了ASCII,包含 256個字符,支持西歐語言的字符
- GB2312:中國定義的一個標準,包含了 7445個字符,6763個漢字和 682個非漢字字符
- GBK:中國定義的一個標準,支持 21003個漢字和圖形字符,涵蓋了漢字、日文假名、韓文、特殊符號等,兼容 GB2312
- GB18030:中國定義的一個標準,支持 70000多個字符,兼容 ASCII、GB2312、GBK等多種編碼方案
- Unicode:包含了全球幾乎所有書寫系統的 110多萬個字符,它提供一個統一的字符編碼標準,支持所有語言
- Big5字符集:包含 13053個繁體中文漢字和其他字符,主要用于臺灣和香港
編碼和解碼
1.編碼
編碼(Encoding)是將字符集中的字符轉換為計算機可以處理的二進制數據的規則或方案。不同的編碼方式會使用不同的二進制模式來表示同一個字符。常見的編碼方式包括:
- ASCII編碼:使用 7位二進制數表示字符
- UTF-8:一種 Unicode編碼方式,使用1到4個字節來表示一個字符。UTF-8是目前最廣泛使用的編碼方式,具有向后兼容 ASCII的特點
- UTF-16:一種 Unicode編碼方式,使用2或4個字節表示一個 Unicode字符(不常用)
- UTF-32:一種 Unicode編碼方式,使用固定的 4個字節表示一個 Unicode字符(不常用)
- GB2312:一種為簡體中文設計的編碼方式,使用1或2個字節表示一個 Unicode字符(不常用)
- GBK:一種為簡體中文設計的編碼方式,使用1或2個字節表示一個 GBK字符
- Big5:一種主要用于臺灣和香港的繁體字符集,使用雙字節來存儲 Big5字符集
2.解碼
解碼(Decoding)是將編碼后的數據還原為其原始格式的過程,解碼通常是編碼的逆過程。
通過上面的描述可以知道:GB2312,GBK,GB18030 它即包含一套字符集,也包含了對應的一套編解碼。
ASCII碼
計算機起源于美國,計算機內部使用的是二進制(0/1),而美國的通用的語言是英文,于是,為了規范英語字符與二進制位之間的關系,在上個世紀60年代,美國制定了一套字符編碼,這就是一直沿用至今的 ASCII 碼。
在英語里,除了 26個英文字母的大小寫,再加上一些通用的符號,總共 128個字符(包括 32個不能打印的控制符號),因此,ASCII碼也定義了與之對應的 128個編碼,比如,字母 A的 ASCII碼是十進制 65(二進制:01000001)。
對于 128=2? 個字符,只需要一個字節就能存儲(1byte = 8bit),而且只需要占用了一個字節的后面7 位,因此,ASCII碼規定二進制的最前面的一位統一為 0。如下為一張 ASCII碼表:
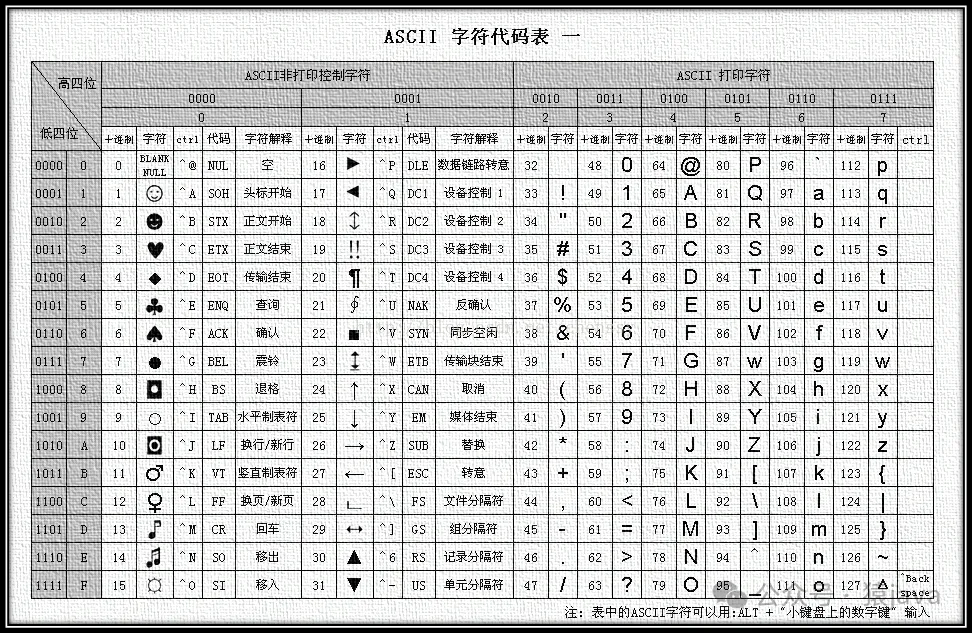
所以,ASCII碼是為了英語使用者能夠把常用的 128個字符存儲在計算機中而設置的一套規則。
GB2312
ASCII碼的設計很優秀,但對于中文使用者,怎么能接受計算機存儲不了中文的現實?于是,聰明的中國人在 1980年發布了一套適用自己的新編準:GB2312。
GB2312 是中華人民共和國國家標準《信息交換用漢字編碼字符集 基本集》的簡稱,全稱為 GB 2312-1980。該標準定義了用于簡體中文字符和一些其他字符的編碼方法,而且兼容 ASCII,廣泛應用于中文信息處理系統中。
GB2312是一個雙字節編碼字符集,即 GB2312中的所有字符都使用兩個字節進行編碼和存儲,具體編碼結構如下:
1.字符范圍
GB2312 總共有 7445個字符,主要包括 6763個漢字和 682個非漢字字符(如 ASCII、拉丁字母、希臘字母、日文假名、符號等)。具體分為以下兩個部分:
- 一級漢字:3755個常用漢字,按拼音順序排列
- 二級漢字:3008個次常用漢字,按部首/筆畫順序排列
- 非漢字字符:682個,包括圖形符號、拉丁字母、日文假名、希臘字母、俄文字母、制表符、標點符號等。
2.編碼區間
- GB2312 將字符集劃分為 94個區(1-94),每區包含 94個位置(1-94)
- 每個字符由兩個字節表示,第一個字節(高字節)表示區號,第二個字節(低字節)表示位置號
- 第一個字節范圍:0xA1 - 0xF7
- 第二個字節范圍:0xA1 - 0xFE
3.舉例說明
GB2312 編碼表可以通過下面這兩個特定的公式計算得到:
- 高字節:0xA1 + 區號 - 1
- 低字節:0xA1 + 位置號 - 1
以“你好” 為例來演示:
“你”在 GB2312編碼表中位于第 36區第 67位:
高字節:0xA1 + 36 - 1 = 0xC4
低字節:0xA1 + 67 - 1 = 0xE3
因此,"你"的 GB2312編碼為 0xC4E3,和 GB2312編碼表中的值可以對應上。“好”在 GB2312編碼表中位于第 26區第 35位:
高字節:0xA1 + 26 - 1 = 0xBA
低字節:0xA1 + 35 - 1 = 0xC3
因此,"好"的 GB2312編碼是 0xBAC3,和 GB2312編碼表中的值可以對應上。GBK
隨著互聯網的快速發展,GB2312編碼表中定義的字符已經不夠用了,因此,GB2312的擴展版 GBK編碼表誕生了。
GBK是“國標擴展字符集”前 3個漢字拼音首字母的縮寫,全稱是《漢字內碼擴展規范》(Chinese Internal Code Extension, GBK)。GBK字符集是 1993年發布的,它是對 GB2312的擴展。
GBK是一個雙字節編碼字符集,每個字符由一個或兩個字節表示。其編碼結構如下:
1.字符范圍
- GBK支持 21003個漢字和圖形字符,涵蓋了漢字、日文假名、韓文、特殊符號等
- 包括 GB2312的全部字符,以及其他新增的漢字和符號
2.編碼區間
① GBK擴展了 GB2312的編碼范圍,使其支持更多字符
② 單字節部分(與 ASCII兼容):0x00 - 0x7F
③雙字節部分:
- 第一個字節范圍:0x81 - 0xFE
- 第二個字節范圍:0x40 - 0xFE(去掉 0x7F)
3.舉例說明
- 單字節:字符“A”,使用單個字節可以存儲,“A”的 ASCII碼十進制是65,轉換成十六進制為:0x41,二進制為:1000001
- 雙字節:字符“漢”在 GBK編碼中使用雙字節表示,GBK編碼: BABA,分成兩個字節表示成:0xBA 0xBA
GB18030
GB18030 是國家標準化委員會(SAC)發布的字符編碼標準,是一種用于漢字、漢語拼音、注音符號和漢字部首等文字的字符集和編碼方案,它是繼 GB2312和 GBK 后更強筋的版本。
GB18030的特點包括:
- 兼容性:GB18030兼容ASCII、GB2312、GBK以及Unicode等多種編碼方案。
- 完備性:GB18030收錄了70000多個字符,包括漢字、漢語拼音、注音符號、漢字部首、拉丁字母、數字、標點符號等。
- 可擴展性:GB18030采用了四字節編碼方案,可以容納未來出現的所有字符。其中漢字使用雙字節或四字節編碼,而非漢字字符則使用單字節或雙字節編碼。
ISO-8859-1
ISO-8859-1,全稱為”ISO/IEC 8859-1”,是國際標準化組織(ISO)和國際電工委員會(IEC)發布的字符編碼標準之一,也被稱為 Latin-1或 Western European (ISO)。它是 ISO-8859系列中的第一個字符編碼標準,旨在支持西歐地區的主要語言,如英語、法語、德語、西班牙語等。
ISO-8859-1的特點包括:
- 單字節編碼:ISO-8859-1采用單字節編碼方案,即每個字符占用一個字節(8位),可以表示 256個不同的字符
- 西歐語言支持:該編碼標準主要針對西歐地區的語言,覆蓋了西歐語言中常用的字符、標點符號和特殊符號
- ASCII兼容:ISO-8859-1是 ASCII編碼的擴展,完全兼容 ASCII
ISO-8859-1的一些限制:
- 不支持非拉丁字符集:ISO-8859-1無法表示除拉丁字母外的字符,因此對于不使用拉丁字母的語言,如希臘語、俄語等,需要使用其他字符編碼標準
- 只支持 256個字符,表示的字符范圍比較小
總的來說,ISO-8859-1是一個針對西歐語言的基本字符編碼標準,雖然在全球范圍內的使用逐漸減少,但在某些特定的場景和遺留系統中仍然可能會遇到。
Unicode
上面介紹的字符集,要么是為英語或者西歐使用者設計的,要么是兼容漢字但對其他語言不友好,因此,有沒有一種全球通用并且包含全球所有通用的字符呢?
于是,Unicode字符集誕生了!
1.Unicode是什么
Unicode,正如它的中文意思“統一碼”一樣,它包含了世界上所有的通用符號(超過 110多萬個符號),而且給每個符號賦予一個獨一無二的編碼,通常表示為:U+后跟一個十六進制數,例如,U+56fd 表示漢字的“國”,U+0639 表示阿拉伯字母 Ain,U+0041 表示英語的字母 A等。
2.Unicode存在的問題
Unicode盡管包含了全球所有通用的字符,但它只是統一了所有的字符集,也就是說它只規定了符號的二進制代碼格式,卻沒有規定這個二進制代碼應該如何存儲(編解碼)。
比如,Unicode 包含的這些字符集中,有的 1個字節能存儲,有的 2個字節能存儲,有的需要 4個字節才能存儲,因此,對于一個 Unicode字符,計算機如何知道需要采用幾個字節來存儲?基于此局面,急需一套統一的編碼方式。
UTF-8
對于 Unicode字符集,通常有 UTF-8,UTF-16,UTF-32等編碼方式。
UTF,Unicode Transformation Format(Unicode 轉換格式),而 UTF-8是目前互聯網上使用最廣的一種 Unicode實現方式,因此,本文重點分析 UTF-8。
1.可變長度
UTF-8 是一種變長的編碼方式,使用 1~4個字節來表示不同的 Unicode字符:
- 1 字節: 用于編碼 7 位 ASCII 字符,表示范圍:U+0000 到 U+007F,與 ASCII 碼完全兼容
- 2 字節: 用于編碼 11 位字符,表示范圍:U+0080 到 U+07FF
- 3 字節: 用于編碼 16 位字符,表示范圍:U+0800 到 U+FFFF
- 4 字節: 用于編碼 21 位字符,表示范圍:U+10000 到 U+10FFFF
2.字節結構
UTF-8 編碼的字節結構如下:
1字節: 0xxxxxxx
2字節: 110xxxxx 10xxxxxx
3字節: 1110xxxx 10xxxxxx 10xxxxxx
4字節: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx通過上述字節結構,可以總結兩個規律:
- 對于單字節的符號,UTF-8編碼和 ASCII碼是相同的:第一位為 0,后面 7位為 Unicode碼
- 對于n(n >= 2)字節的符號,二進制的第一個字節,最高位有 n個“1”(“1”后面緊跟一位 0),二進制后面的每個字節,前兩位都固定為“10”,xxx部分全部是 Unicode碼
3.舉例說明
(1) 字符 ‘A’ (U+0041)
分析:字符’A’的 Unicode是 U+0041,位于 U+0000 到 U+007F之間,因此,一個字節就可以表示,因此,二進制為:01000001,轉成十六進制為:0x41
(2) 字符 ‘€’ (U+20AC)
分析:字符 ‘€’的 Unicode是 U+20AC,位于 U+0800 到 U+FFFF之間,因此,需要用 3個字節表示,即1110xxxx 10xxxxxx 10xxxxxx,將“20AC”中的每個字符直接轉換成二進制為:0010 0000 1010 1100,然后將它從低位往高位(從右到左)依次替換x,如下圖:
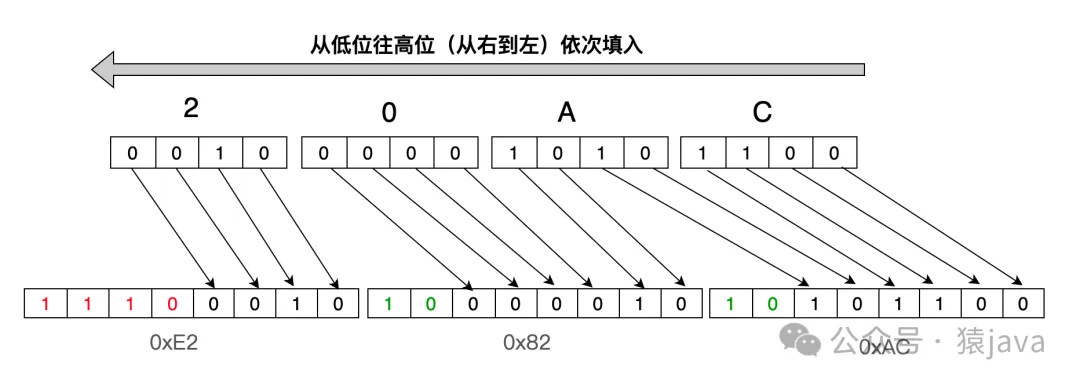
這樣得出字符 ‘€’ (U+20AC)用 UTF-8編碼的二進制為:11100010 10000010 10101100,轉換成十六進制為:0xE2 0x82 0xAC
utf8mb4
使用過 MySQL數據庫的小伙伴對 utf8mb4肯定不陌生,它是 MySQL數據庫中的一種字符集,具體來說是 UTF-8的一個變種,能夠支持所有的 Unicode字符,包括那些需要 4個字節表示的字符(例如某些 emoji表情符號和一些罕見的漢字)。
在 MySQL中,utf8字符集最多支持 3個字節的字符,因此,它不能存儲所有的 Unicode字符,而 utf8mb4字符集支持 4個字節的字符,能夠存儲所有的 Unicode字符。
因此,在一些涉及聊天業務的場景,utf8mb4字符集經常被使用,主要是用于存儲 emoji表情,比如:????♂???♀?????????????
為什么會亂碼?
從上文的分析中,我們知道了什么是字符集,什么是編碼以及兩者之間的關系。假如某字符在保存時使用了一種編碼,讀取時使用了另外一種編碼,試想下,是不是就會出現亂碼?
為了更好的證實我們的猜想,這里以“國”字的為例進行說明,使用 UTF-8編碼,使用 GBK解碼:
1.編碼
“國”字的 Unicode是 U+56FD,在 UTF-8中,它被編碼為三個字節:11100101 10011011 10011101 (0xE5 0x9B 0xBD)
2.解碼
使用 GBK編碼讀取,它是一種雙字節編碼方案,因此,它可能會將這三個字節解釋為兩種:
- 解釋成 2個字節 + 1個字節,導致亂碼。
- 解釋成 2個字節 + 2個字節(包含下一個字符的第一個字節),導致亂碼。
所以,為了防止亂碼,我們需要使用統一的編解碼。
總結
本文分析了什么是字符集,什么是編碼編碼,兩者的關系,分析了常見的字符集以及編碼以及亂碼產生的原因,這里總結幾個核心點:
- 字符集(Character Set)是字符的集合,包含字母、數字、標點符號、控制字符、中文以及其他符號
- 編碼(Encoding)是將字符集中的字符轉換為計算機可以處理的二進制數據的規則或方案
- 解碼(Decoding)是將編碼后的數據還原為其原始格式的過程,解碼通常是編碼的逆過程
- ASCII主要是為英語使用者設計,只能支持 128個字符
- ISO-8859-1主要是為西歐設計的
- GB2312,GBK,GB18030有對應的編碼表,只要查表然后按照其字節規則就能很清晰的知道它在計算機中如何存儲
- UTF-8 是一種變長的編碼方式,使用 1~4 個字節來表示不同的 Unicode 字符
- utf8mb4 是MySQL中的一種字符集,它是 UTF-8的變種,用于存儲表情符號、某些罕見漢字或其他特殊字符
- 很多亂碼的根本原因是編解碼不一致,因此,為了防止亂碼,需要使用統一的編解碼

















