













自動駕駛場景中的長尾問題怎么解決?
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。
自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生概率較低的可能場景。感知的長尾問題是當前限制單車智能自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經被解決,剩下的5%的長尾問題,逐漸成了制約自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。
自動駕駛中的邊緣場景
長尾”是指自動駕駛汽車 (AV) 中的邊緣情況,邊緣情況是發生概率較低的可能場景。這些罕見的事件因為出現率較低且比較特殊,因此在數據集中經常被遺漏。雖然人類天生擅長處理邊緣情況,但人工智能卻不是這樣。可能引起邊緣場景的因素有:帶有突起的卡車或者異形車輛、車輛急轉彎、在擁擠的人群中行駛、亂穿馬路的行人、極端天氣或極差光照條件、打傘的人,人在車后搬箱子、樹倒在路中央等等。
例子:
- 放透明薄膜在車前,透明物體是否可以被識別,車輛是否會減速
- 激光雷達公司Aeye就做了一次挑戰,自動駕駛如何處理一個漂浮在路中央的氣球。L4級無人駕駛汽車往往偏向避免碰撞,在這種情況下,它們會采取規避動作或者踩剎車,來避免不必要的事故。而氣球是個軟性的物體,可以直接無障礙的通過。
解決長尾問題的方法
合成數據是個大概念,而感知數據(nerf, camera/sensor sim)只是其中一個比較出圈的分支。在業界,合成數據在longtail behavior sim早已成為標準答案。合成數據,或者說sparse signal upsampling是解決長尾問題的第一性解法之一。長尾能力是模型泛化能力與數據內含信息量的乘積。
特斯拉解決方案:
用合成數據(synthetic data)生成邊緣場景來擴充數據集
數據引擎的原理:首先,檢測現有模型中的不準確之處,隨后將此類案例添加到其單元測試中。它還收集更多類似案例的數據來重新訓練模型。這種迭代方法允許它捕獲盡可能多的邊緣情況。制作邊緣案例的主要挑戰是收集和標注邊緣情況的成本比較高,再一個就是收集行為有可能非常危險甚至無法實現。
NVIDIA解決方案:
NVIDIA 最近提出了一種名為“模仿訓練”的戰略方法(下圖)。在這種方法中,真實世界中的系統故障案例在模擬環境中被重現,然后將它們用作自動駕駛汽車的訓練數據。重復此循環,直到模型的性能收斂。
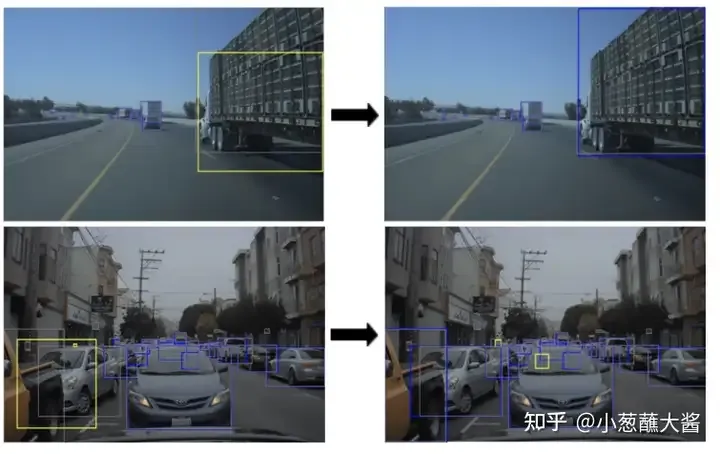
以下真實場景中由于卡車高度過高(上)、車輛凸出部分遮擋后車(下)導致模型輸出時車框丟失,成為邊緣場景,過NVIDIA改進后的模型可以在此邊緣情況下生成正確的邊界框:
一些思考:
Q:合成數據是否有價值?
A: 這里的價值分為兩種 , 第一種是測試有效性, 即在生成的場景中測試 是否能發現探測算法中的一些不足, 第二種是訓練有效性, 即生成的場景用于算法的訓練是否也能夠有效提升性能。
Q: 如何使用虛擬數據提升性能?虛擬數據真的有必要添加到訓練集中去嗎?添加進去了是否會產生性能回退?
A: 這些問題都難以回答, 于是產生了很多不一樣的提高訓練精度的方案:
- 混合訓練:在真實數據中添加不同比例的虛擬數據, 以求性能提升,
- Transfer Learning:使用真實數據預訓練好的模型,然后Freeze 某些layer, 再添加混合數據進行訓練。
- Imitation Learning:針對性設計一些模型失誤的場景, 并由此產生一些數據,進而逐步提升模型的性能, 這一點也是非常自然的。在實際的數據采集和模型訓練中, 也是針對性采集一些補充數據, 進而提升性能。
一些擴展:
為了徹底評估 AI 系統的穩健性,單元測試必須包括一般情況和邊緣情況。然而,某些邊緣案例可能無法從現有的真實世界數據集中獲得。為此,人工智能從業者可以使用合成數據進行測試。
一個例子是ParallelEye-CS,這是一種用于測試自動駕駛汽車視覺智能的合成數據集。與使用真實世界數據相比,創建合成數據的好處是可以對每個圖像的場景進行多維度控制。
合成數據將作為生產 AV 模型中邊緣情況的可行解決方案。它用邊緣案例補充現實世界的數據集,確保 AV 即使在異常事件下也能保持穩健。它也比真實世界的數據更具可擴展性,更不容易出錯,并且更便宜。



















