













無需OpenAI數據,躋身代碼大模型榜單!UIUC發布StarCoder-15B-Instruct
在軟件技術的前沿,UIUC張令明組攜手BigCode組織的研究者,近日公布了StarCoder2-15B-Instruct代碼大模型。
這一創新成果在代碼生成任務取得了顯著突破,成功超越CodeLlama-70B-Instruct,登上代碼生成性能榜單之巔。

StarCoder2-15B-Instruct的獨特之處在于其純自對齊策略,整個訓練流程公開透明,且完全自主可控。
該模型通過StarCoder2-15B生成數千個指令-響應對,直接對StarCoder-15B基座模型進行微調,無需依賴昂貴的人工標注數據,也無需從GPT4等商業大模型中獲取數據,避免了潛在的版權問題。
在HumanEval測試中,StarCoder2-15B-Instruct以72.6%的Pass@1成績脫穎而出,較CodeLlama-70B-Instruct的72.0%有所提升。
更為令人矚目的是,在LiveCodeBench數據集的評估中,這一自對齊模型的表現甚至超越了基于GPT-4生成數據訓練的同類模型。這一成果證明了,通過自身分布內的數據,大模型同樣能夠有效地學習如何與人類偏好對齊,而無需依賴外部教師大模型的偏移分布。
該項目的成功實施得到了美國東北大學Arjun Guha課題組、加州大學伯克利分校、ServiceNow和Hugging Face等機構的鼎力支持。
技術揭秘
StarCoder2-Instruct的數據生成流程主要包括三個核心步驟:

1. 種子代碼片段的采集:團隊從The Stack v1中篩選出高質量、多樣化的種子函數,這些函數來自海量的獲得許可的源代碼語料庫。通過嚴格的過濾和篩選,確保了種子代碼的質量和多樣性;
2. 多樣化指令的生成:基于種子函數中的不同編程概念,StarCoder2-15B-Instruct能夠創建出多樣化且真實的代碼指令。這些指令涵蓋了從數據反序列化到列表連接、遞歸等豐富的編程場景;
3. 高質量響應的生成:對于每個指令,模型采用編譯運行引導的自我驗證方式,確保生成的響應是準確且高質量的。
每個步驟的具體操作如下:
精選種子代碼片段的過程
為了提升代碼模型在遵循指令方面的能力,模型需要廣泛接觸和學習不同的編程原理與實際操作。StarCoder2-15B-Instruct受到OSS-Instruct的啟發,從開源代碼片段中汲取靈感,尤其是The Stack V1中那些格式規范、結構清晰的Python種子函數。
在構建其基礎數據集時,StarCoder2-15B-Instruct對The Stack V1進行了深度挖掘,選取了所有配備文檔說明的Python函數,并借助autoimport功能自動分析并推斷了這些函數所需的依賴項。
為了確保數據集的純凈性和高質量,StarCoder2-15B-Instruct對所有選取的函數進行了精細的過濾和篩選。
首先,通過Pyright類型檢查器進行嚴格的類型檢查,排除了所有可能產生靜態錯誤的函數,從而保證了數據的準確性和可靠性。
接著,通過精確的字符串匹配技術,識別和剔除了與評估數據集存在潛在關聯的代碼和提示,以避免數據污染。在文檔質量方面,StarCoder2-15B-Instruct更是采用了獨特的篩選機制。
它利用自身的評估能力,通過向模型展示7個樣本提示,讓模型自行判斷每個函數的文檔質量是否達標,從而決定是否將其納入最終的數據集。
這種基于模型自我判斷的方法,不僅提高了數據篩選的效率和準確性,也確保了數據集的高質量和一致性。
最后,為了避免數據冗余和重復,StarCoder2-15B-Instruct采用了MinHash和局部敏感哈希算法,對數據集中的函數進行了去重處理。通過設定0.5的Jaccard相似度閾值,有效去除了相似度較高的重復函數,確保了數據集的獨特性和多樣性。
經過這一系列的精細篩選和過濾,StarCoder2-15B-Instruct最終從500萬個帶有文檔的Python函數中,精選出了25萬個高質量的函數作為其種子數據集。這一方法深受MultiPL-T數據收集流程的啟發。
多樣化指令的生成
當StarCoder2-15B-Instruct完成了種子函數的收集后,它運用了Self-OSS-Instruct技術來創造多樣化的編程指令。這一技術的核心在于通過上下文學習,讓StarCoder2-15B基座模型能夠自主地為給定的種子代碼片段生成相應的指令。
為實現這一目標,StarCoder2-15B-Instruct精心設計了16個范例,每個范例都遵循(代碼片段,概念,指令)的結構。指令的生成過程被細分為兩個階段:
代碼概念識別:在這一階段,StarCoder2-15B會針對每一個種子函數進行深入分析,并生成一個包含該函數中關鍵代碼概念的列表。這些概念廣泛涵蓋了編程領域的基本原理和技術,如模式匹配、數據類型轉換等,這些對于開發者而言具有極高的實用價值。
指令創建:基于識別出的代碼概念,StarCoder2-15B會進一步生成與之對應的編碼任務指令。這一過程旨在確保生成的指令能夠準確地反映代碼片段的核心功能和要求。
通過上述流程,StarCoder2-15B-Instruct最終成功生成了高達238k個指令,極大地豐富了其訓練數據集,并為其在編程任務中的表現提供了強有力的支持。
響應的自我驗證機制
在獲取Self-OSS-Instruct生成的指令后,StarCoder2-15B-Instruct的關鍵任務是為每個指令匹配高質量的響應。
傳統上,人們傾向于依賴如GPT-4等更強大的教師模型來獲取這些響應,但這種方式不僅可能面臨版權許可的難題,而且外部模型并非總是觸手可及或準確無誤。更重要的是,依賴外部模型可能引入教師與學生之間的分布差異,這可能會影響到最終結果的準確性。
為了克服這些挑戰,StarCoder2-15B-Instruct引入了一種自我驗證機制。這一機制的核心思想是,讓StarCoder2-15B模型在生成自然語言響應后,自行創建對應的測試用例。這一過程類似于開發人員編寫代碼后的自測流程。
具體而言,對于每一個指令,StarCoder2-15B會生成10個包含自然語言響應和對應測試用例的樣本。隨后,StarCoder2-15B-Instruct會在一個沙盒環境中執行這些測試用例,以驗證響應的有效性。任何在執行測試中失敗的樣本都會被過濾掉。
經過這一嚴格的篩選過程,StarCoder2-15B-Instruct會從每個指令的通過測試的響應中隨機選取一個,加入最終的SFT數據集。整個過程中,StarCoder2-15B-Instruct為238k個指令生成了總計240萬個響應樣本(每個指令10個樣本)。在采用0.7的采樣策略后,有50萬個樣本成功通過了執行測試。
為了確保數據集的多樣性和質量,StarCoder2-15B-Instruct還進行了去重處理。最終,剩下5萬個指令,每個指令都配有一個隨機選取的、經過測試驗證的高質量響應。這些響應構成了StarCoder2-15B-Instruct最終的SFT數據集,為模型的后續訓練和應用提供了堅實的基礎。
StarCoder2-15B-Instruct的卓越表現與全面評估
在備受矚目的EvalPlus基準測試中,StarCoder2-15B-Instruct憑借其規模化優勢,成功脫穎而出,成為表現最出色的自主可控大型模型。
它不僅超越了規模更大的Grok-1 Command-R+和DBRX,還與Snowflake Arctic 480B和Mixtral-8x22B-Instruct等業界翹楚性能相當。
值得一提的是,StarCoder2-15B-Instruct是首個在HumanEval基準上達到70+得分的自主代碼大模型,其訓練過程完全透明,數據和方法的使用均符合法律法規。
在自主可控代碼大模型領域,StarCoder2-15B-Instruct顯著超越了之前的佼佼者OctoCoder,證明了其在該領域的領先地位。
即便與擁有限制性許可的大型強力模型如Gemini Pro和Mistral Large相比,StarCoder2-15B-Instruct依然展現出卓越的性能,并與CodeLlama-70B-Instruct平分秋色。更令人矚目的是,StarCoder2-15B-Instruct完全依賴于自生成數據進行訓練,其性能卻能與基于GPT-3.5/4數據微調的OpenCodeInterpreter-SC2-15B相媲美。

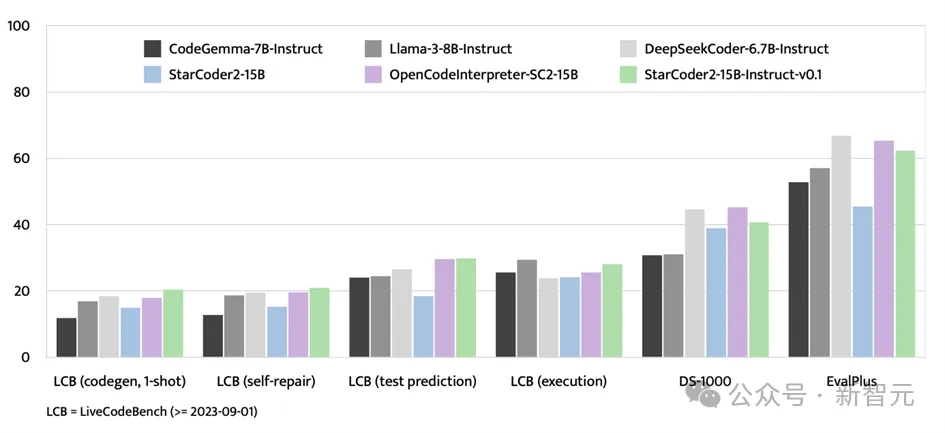
除了EvalPlus基準測試,StarCoder2-15B-Instruct在LiveCodeBench和DS-1000等評估平臺上也展現出了強大的實力。
LiveCodeBench專注于評估2023年9月1日之后出現的編碼挑戰,而StarCoder2-15B-Instruct在該基準測試中取得了最優成績,并且始終領先于使用GPT-4數據進行微調的OpenCodeInterpreter-SC2-15B
盡管DS-1000專注于數據科學任務,StarCoder2-15B-Instruct在訓練數據中涉及的數據科學問題相對較少,但其在該基準測試中的表現依然強勁,顯示出廣泛的適應性和競爭力。
StarCoder2-15B-Instruct-v0.1的突破與啟示
StarCoder2-15B-Instruct-v0.1的發布,標志著研究者們在代碼模型自我調優領域邁出了重要一步。這款模型的成功實踐,打破了以往必須依賴如GPT-4等強大外部教師模型的限制,展示了通過自我調優同樣能夠構建出性能卓越的代碼模型。
StarCoder2-15B-Instruct-v0.1的核心在于其自我對齊策略在代碼學習領域的成功應用。這一策略不僅提升了模型的性能,更重要的是,它賦予了模型更高的透明度和可解釋性。這一點與Snowflake-Arctic、Grok-1、Mixtral-8x22B、DBRX和CommandR+等其他大型模型形成了鮮明對比,這些模型雖然強大,但往往因缺乏透明度而限制了其應用范圍和可信賴度。
更令人欣喜的是,StarCoder2-15B-Instruct-v0.1已經將其數據集和整個訓練流程——包括數據收集和訓練過程——完全開源。這一舉措不僅彰顯了研究者的開放精神,也為未來該領域的研究和發展奠定了堅實的基礎。
有理由相信,StarCoder2-15B-Instruct-v0.1的成功實踐將激發更多研究者投入到代碼模型自我調優領域的研究中,推動該領域的技術進步和應用拓展。同時,也期待這一領域的更多創新成果能夠不斷涌現,為人類社會的智能化發展注入新的動力。
作者簡介
UIUC的張令明老師是一位在軟件工程、程序語言和機器學習交叉領域具有深厚造詣的學者。他領導的課題組長期致力于基于AI大模型的自動軟件合成、修復和驗證研究,以及機器學習系統的可靠性提升。
近期,團隊發布了多個創新性的代碼大模型和測試基準數據集,并率先提出了一系列基于大模型的軟件測試和修復技術。同時,在多個真實軟件系統中成功挖掘出上千個新缺陷和漏洞,為提升軟件質量做出了顯著貢獻。

























