













如何實現對 3000+ 軟件包的全鏈路自主研發與維護?
作者 | 趙振
Linux 發行版的自主維護工作一直面臨著巨大的挑戰,軟件包規模巨大,涉及多個領域,要進行有效的自主維護,對人力、能力都有極高的要求。本文根據騰訊工程師、OpenCloudOS 社區技術專家趙振在 2024 年第十一屆開源操作系統年度會議(OS2ATC)上的分享整理,重點探討為打造全鏈路自研操作系統,如何實現對 3000+ 大規模軟件包的全鏈路自主研發與自主維護。

一、整體介紹
一個 Linux 發行版標準鏡像包含 3000 余個軟件包,具體涉及庫、工具、服務、語言運行時、圖形、音視頻等各個方面,再加上各種場景應用,比如云原生、數據庫、AI 等,涉及軟件包數以萬計,如何維護如此大規模的軟件包,對團隊的人力、人員能力都是巨大的挑戰。
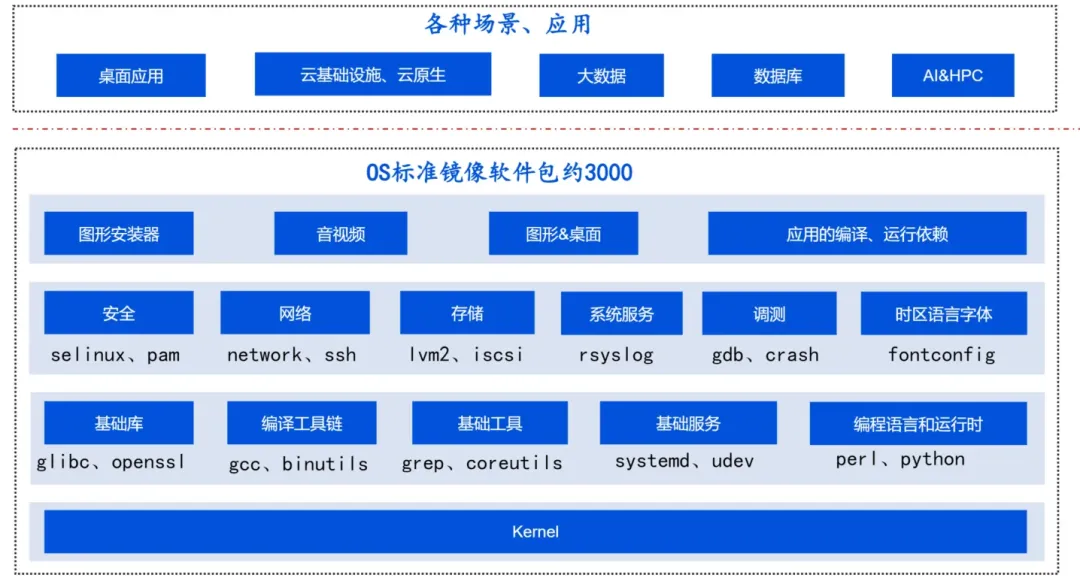
操作系統團隊在對軟件包分類、分層,按照領域分類、重要性等進行差異化維護之外,更構建了一套全流程自動化的基礎設施和工具平臺,以提升維護效率和質量,讓軟件包的維護者有更多的精力投入到重要包的掌握和能力建設中。
該工具平臺從上游跟蹤到代碼同步,各個流程環節盡可能自動化,主要包括以下 5 個部分及對應的工具。

第一個工具 rpm-upgrade 用來跟蹤上游社區的發布情況,包括獲取新版本的 changelog 了解社區的動態。第二個工具 rpm-tracker 用來跟蹤重要包的 commits,扒取 bugfix、cve 相關的 patch。通過這兩個工具可以及時獲取上游最新的動態、修復,按需同步到自主維護的版本,軟件包維護者就不用人肉跟蹤上游社區;獲取到上游的更新、修復后,會嘗試自動提交 PR。
對于提交成功的PR,會通過第三個工具 rpm-check 進行變更識別和兼容性檢查,如果發現兼容性變化,會自動通過第四個工具 rpm-dep 來查找受影響的軟件包來進行重編、執行受影響的包的用例,最后通過第五個工具 rpm-sync 來同步到其他分支。
以上是軟件包維護全過程,通過 CI 串聯起來實現全流程自動化。
二、具體實現
1.rpm-upgrade:上游新 Release 跟蹤查詢
問題:軟件包的上游社區形式多樣,有 Git、svn、hg 等不同的協議,github/gitlab、pypi、metacpan、Sourceforge 等不同接口,且軟件包最新的 Release 發布時間不定,有的發布頻繁,有的長期無新 Release,不同系列的軟件包選型的間隔也存在差異,如果無差異地對所有包執行升級查詢,浪費資源和人力。
解決方案:團隊設計的 rpm-upgrade 工具,可通過多種查詢接口,覆蓋不同類型的上游平臺;通過綜合發布時間、頻率、選型時間、選型間隔內的版本數等,多維度評估該版本是否需要自動升級。
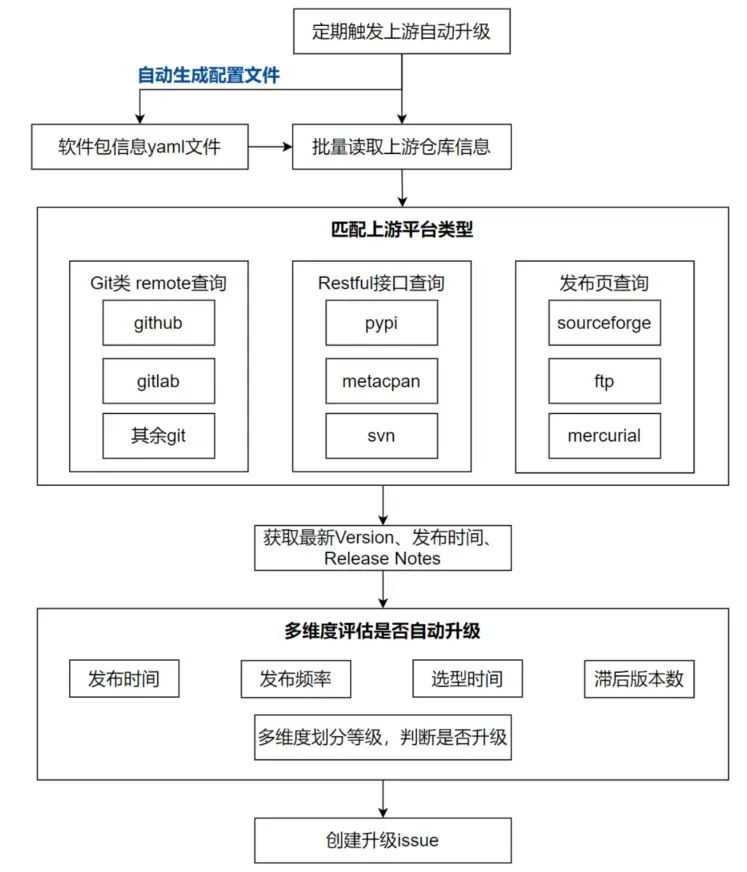
效果:當前主流平臺 Git/svn/pypi/perl 等都已覆蓋,3200+ 軟件包中的 98.5% 都能實現自動化查詢升級,基本不再需要人工跟蹤上游。
2.rpm-upgrade:上游新 Release 自動升級
問題:上游新 Release 查詢到后,符合條件的軟件包就可以進行自動升級。但在升級過程中,還存在多 source 源,tarball 需自行生成、上游未提供完整 tarball,補丁沖突等復雜情況導致自動化困難。
解決方案:工具先修改version、Release、chaneglog,再根據修改后的內容獲取源碼包。如果是多源碼包情況,則根據宏解析自動下載;如果是 tarball 無法直接獲取等情況,則支持維護者自定義腳本處理。
對于升級過程中的補丁沖突,則根據補丁來源和補丁編號規則處理。上游補丁沖突時,視為上游已合入,移除該補丁并記錄; 發行版補丁沖突時,報警提示并記錄,由 maintainer 介入分析。
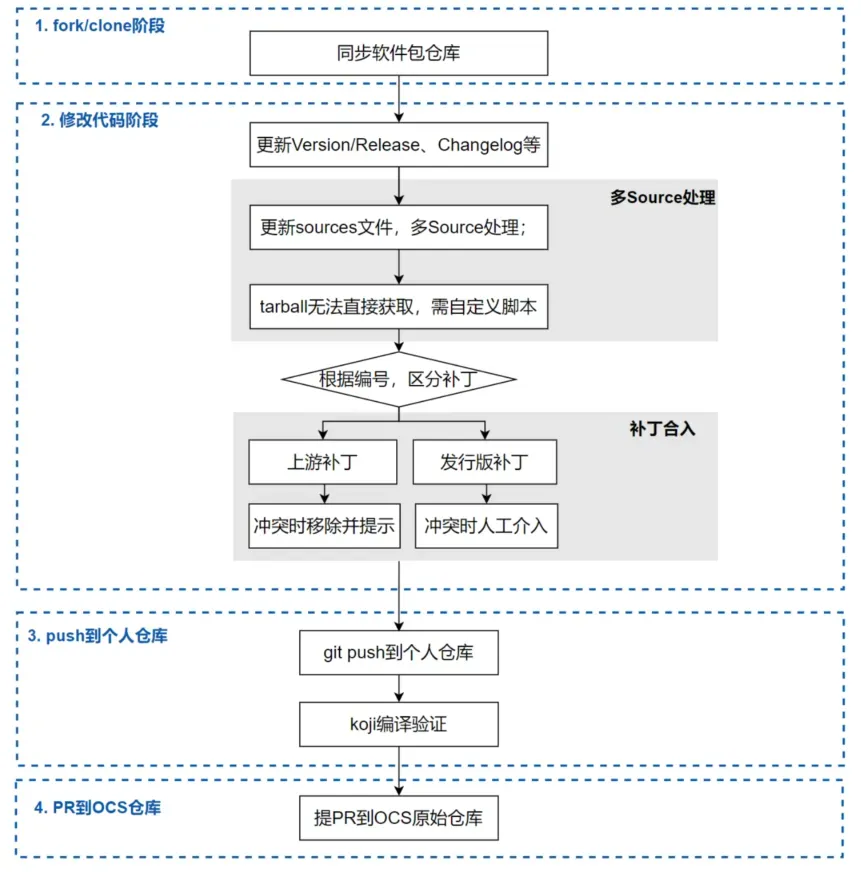
效果:升級軟件包平均節省 10 分鐘以上,并且自動解決補丁沖突可達 85% 以上,軟件包升級效率提升 80%+。
3.rpm-tracker:上游 commits 跟蹤扒取
問題:軟件分支、commit 信息多,傳統 git clone 方式耗時長;主要關注 bugfix、cve,需要對 commtis 進行分類,人工費力、關鍵詞匹配方式不準確。
解決方案:rpm-tracker工具通過 Python 的 GraphQL API 爬取上游 commits 信息,支持 GitHub、GitLab 等主流平臺;并且選擇專門基于代碼訓練的大模型,結合微調,對 commits 進行分類,把 bug 修復、cve 修復等類型的 commits 識別出來,backport 到代碼中。爬取后自動提交 PR。
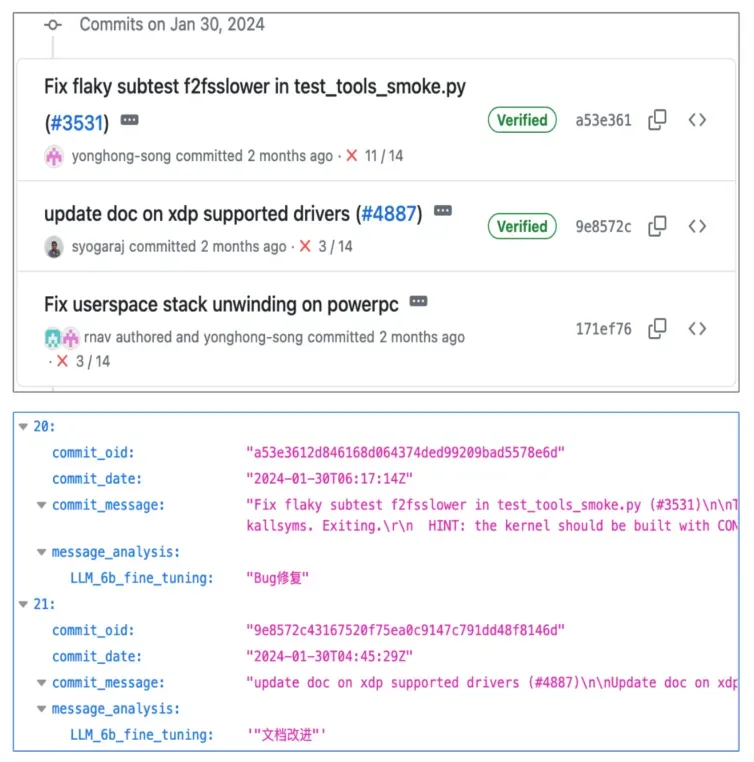
效果:當前工具可以一次性查詢上百個軟件,模型在普通臺式機上無量化的情況下可以穩定運行,輸出結果準確率 80% 以上,大大減少人工分析、回合的工作量。
4.rpm-check:兼容性檢查,軟件包變更的守門人
問題:上游新 Release、commits 扒取回合,提交 PR、完成編譯后,進行兼容性檢查。當前業界已有的兼容性檢查開源工具主要是對 C/C++ 程序、Java 程序進行檢查,同時存在需要人工指定包以及庫、無法處理庫中部分特殊字符、無法判斷符號是否對外、結果可讀性差、速度較慢等情況。
解決方案:rpm-check 在 abicc 社區工具的基礎上解決了上述幾個問題,同時基于Python AST 模塊自研了 Python 兼容性檢查工具。
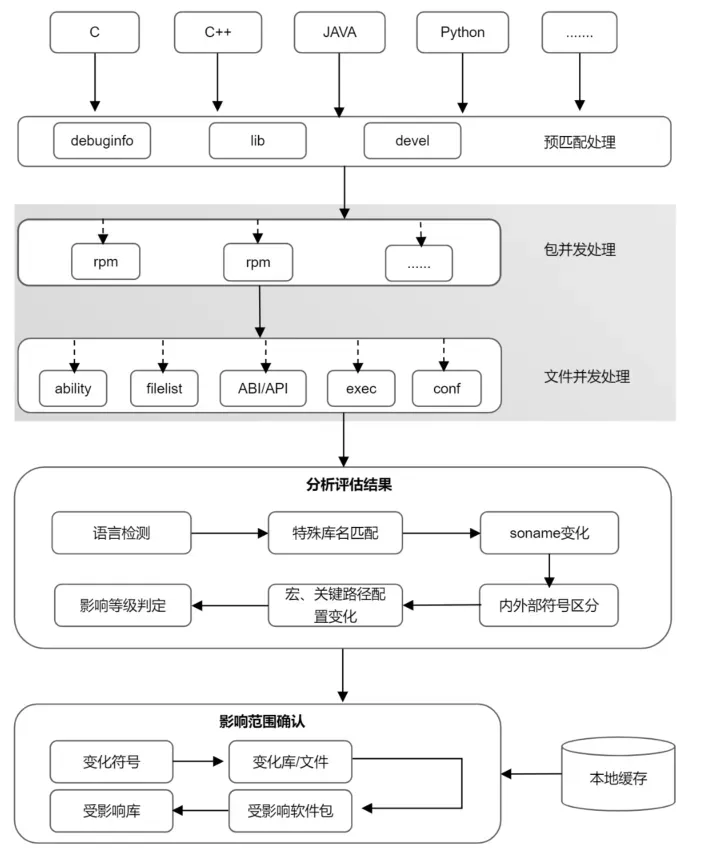
工具掃描目錄下所有 rpm 包及其 debuginfo 包、devel 包進行匹配成對后以篩選出需要檢查的 rpm 包,然后通過多進程方式對每對包進行處理,同時會在文件粒度上也進行并發操作,最大限度縮短檢查時間。
檢查項包括幾個方面:
- 子包列表:檢查子包是否有增刪
- rpm 的能力:(requires/provides/..),判斷是否有能力發生變化
- 文件列表:檢查重點位置的文件是否有增刪,同時排除無關信息(如版本號)以及無影響文件
- 動態庫的 ABI/API:根據代碼變化定位影響的結構體、函數等
- 二進制可執行程序比較:比較軟件包中存在的可執行文件(工具、腳本等)的選項、參數是否發生變化
- 配置文件:支持多種配置文件格式,精確找到具體的變化項
多進程檢查結束后,會對檢查結果進行分析評估:比如 ABI/API 的變化,會先經過內外部符號判定,判斷該變化為內部變化還是外部變化,然后經過評估算法確定其影響等級,影響等級用來判斷該次變化的嚴重程度以及是否需要進一步判斷其影響范圍。
最后根據評估結果等級確認影響范圍,這一步通過在依賴包中進行符號搜索來完成,同時,搜索也會通過本地緩存進行加速。經過以上檢查和精確查找,得到此次的變化影響的符號、軟件包以及受到影響的庫。
效果:支持 C、C++、Python、Java 等主流語言,特殊場景基本覆蓋;從符號粒度確認影響范圍,精確度 90% 以上;包及文件粒度并發,本地緩存縮短檢查以及符號搜索耗時 50% 以上。

5.rpm-dep: 查詢包依賴與排序
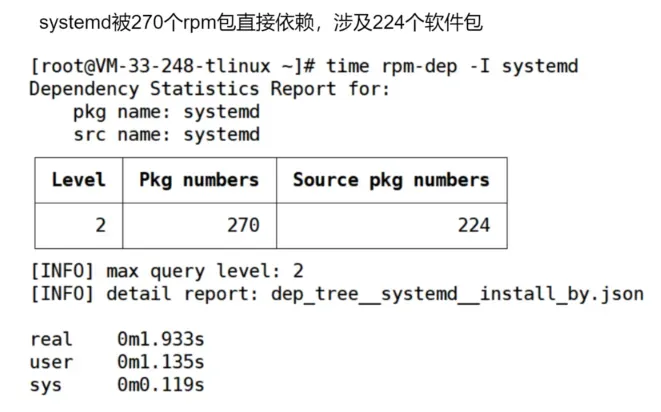
問題:受兼容性變化影響的包,通過 rpm-dep 工具獲取。當前 DNF 工具無法快速獲取發生變化的包所影響到的包,包括依賴當前變化的包進行編譯的包,依賴當前變化的包進行安裝的包,即反向依賴。
同時,獲取到反向依賴包列表后,列表中的包之間也存在層級關系,進行構建時,需要先構建底層的,后處理高層級的,這就需要排序。
解決方案:rpm-dep 工具初始化時,解析 repo 源的 repodata 文件,構造出依賴關系表,將依賴關系表存入 Redis,提高查詢速度。
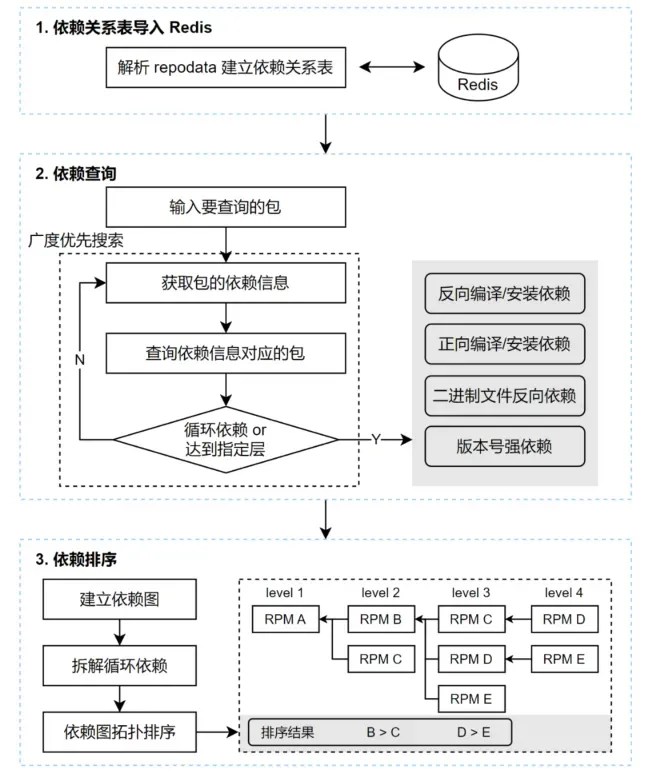
- 依賴查詢時,通過 key - value 查詢,以及 bfs 多層的檢索,即可獲取指定層數的依賴關系樹。
- 依賴排序時,首先建立包的依賴圖,對于存在循環依賴的情況,會統計循環鏈上的所有包的被引用情況,從被引用最少的節點拆開循環鏈條。
然后得到一個有向無環圖,接下來使用拓撲排序的思想,每一輪循環都取出無前向依賴的節點,即可對同層的 RPM 包排出優先級。
效果:多種依賴場景秒級查詢多層依賴樹;包排序指導按依賴層級進行構建。
6.自動 Release+1 重編受影響的包
需求:兼容性變化,需要準確無誤的重編受影響的軟件包,根據影響和風險的不同,分為測試重編和正式重編,測試重編不 Release+1 提交 PR、只用來驗證變化會不會導致問題,如 API 頭文件變化,正式重編是指要 Release+1 提交 PR,如 soname 變化會導致找不到依賴,就要正式重編。測試重編、正式重編,都要保障編譯源依賴的是變化后的包,不能基于老包編譯。
解決:為了避免遺漏或者范圍過廣出現無效重編,我們根據兼容性變化的具體內容和影響范圍,確定重編類型,如表格所示,然后使用 rpm-dep 工具找出受影響的依賴包。
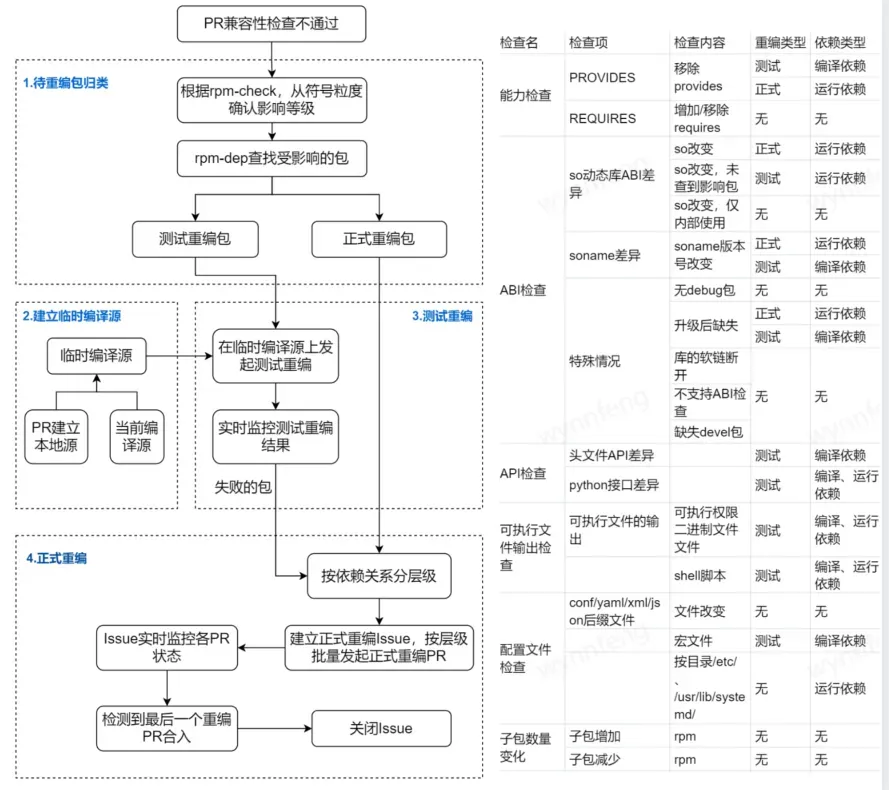
- 對于測試重編,我們將 PR 編譯通過的軟件包結合當前編譯源,制作成臨時編譯源;在這個臨時編譯源的基礎上,我們對受影響的包進行測試重編。
- 對于正式重編,創建 issue 進行跟蹤,按照依賴關系層級排序,自動依次發起正式重編 PR,上一層級的 PR 編譯成功、進入編譯源后,提交下一層級的 PR,直到所有需要 Release+1 重編的包都完成編譯。
效果:重編精準,無遺漏無冗余 Release+1;按依賴層級編譯、構造編譯源,編譯依賴新包;人工只需確認,效率提升 100%。

7.精準全面測試+快速高質量發布
需求:PR 編譯通過后,要對軟件包進行更新發布,既要保證軟件包更新的及時性,也要保證軟件包更新的質量。
解決方案:我們通過消息機制保證編譯完成的軟件包能夠及時更新至測試平臺,立即獲取更新后的軟件包到測試 YUM 源,然后進行升級測試、安裝測試、服務啟停測試、功能測試,并根據前面提到的 rpm-dep 工具給出的受影響包列表執行受影響包的測試,以此來做到精準測試,覆蓋全面,同時高效地得到質量反饋。
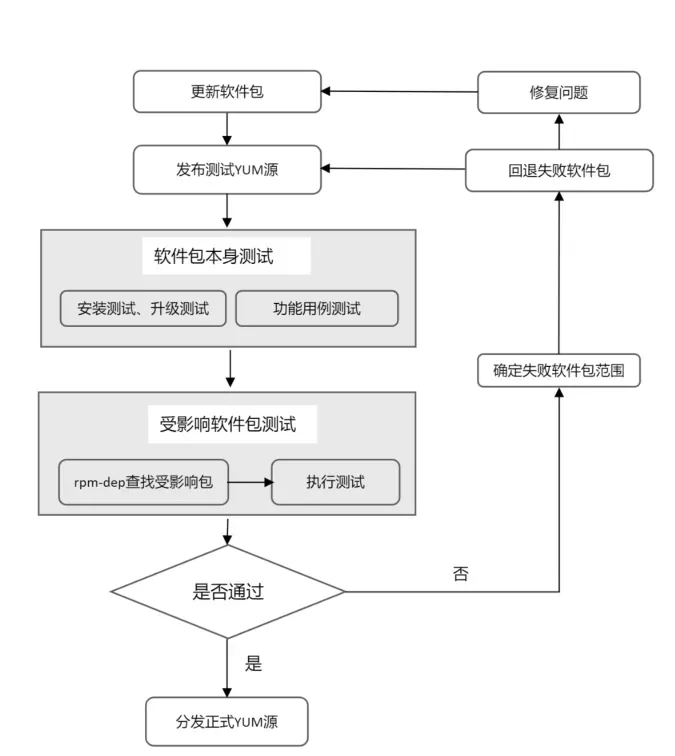
此外,為了防止出錯軟件包阻塞其他通過測試的軟件包的正常發布流程,對于測試未通過的軟件包,會以單個軟件包的粒度回退,清理對應軟件包及其重編包,并發起問題處理流程。然后繼續進行其他保證其他正常軟件包的及時發布。
效果:小時級軟件更新速度(代碼提交到更新發布);軟件升級沖突、功能等問題有效攔截。
8.rpm-sync:分支間高效同步
PR 合入后,后臺會根據 PR 填入的 commit 模板信息,進行分類。識別到是 bugfix, 安全修復,后臺會自動調整相關 commit,向下游分支發起同步。如果同步失敗,會自動創建工單通知相關人員對同步的 PR 進行分析調整。
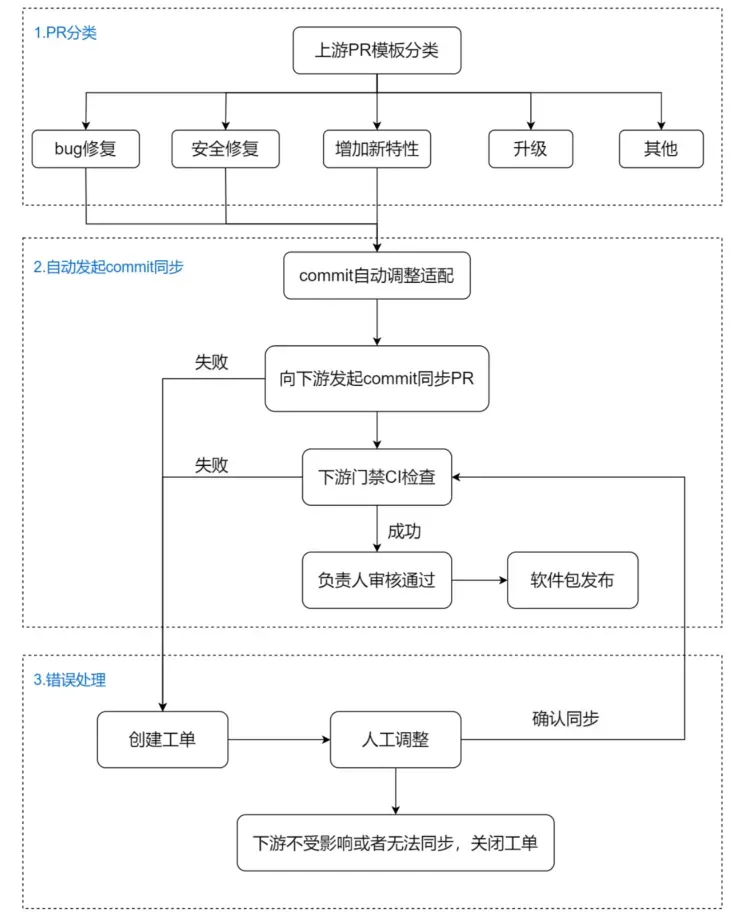
效果:多分支及時保持同步;流程自動化,形成完備的錯誤處理機制;減少人工同步、多分支維護的工作量。
9.整體數據流設計
問題:通過前面的介紹,可以看到,整個自動化流程涉及了上游源碼社區的更新監控,代碼托管平臺的管理、下游編譯平臺、分發平臺以及測試平臺多個流程的不同組件,平臺、流程、環節多,交互復雜,包括事件通知、狀態等待、結果回傳等。
解決方案:基于這個問題,我們設計了一整套消息機制,通過消息隊列解耦不同平臺的數據依賴問題,并通過 CI 平臺的流水線驅動不同任務運行。
比如,當我們監聽到上游社區更新了新版本,這個消息會寫入消息隊列,等待對應的代碼同步流水線處理更新。再將同步完成的消息寫入消息隊列,等待后續的編譯、測試、同步流水線的批次處理。
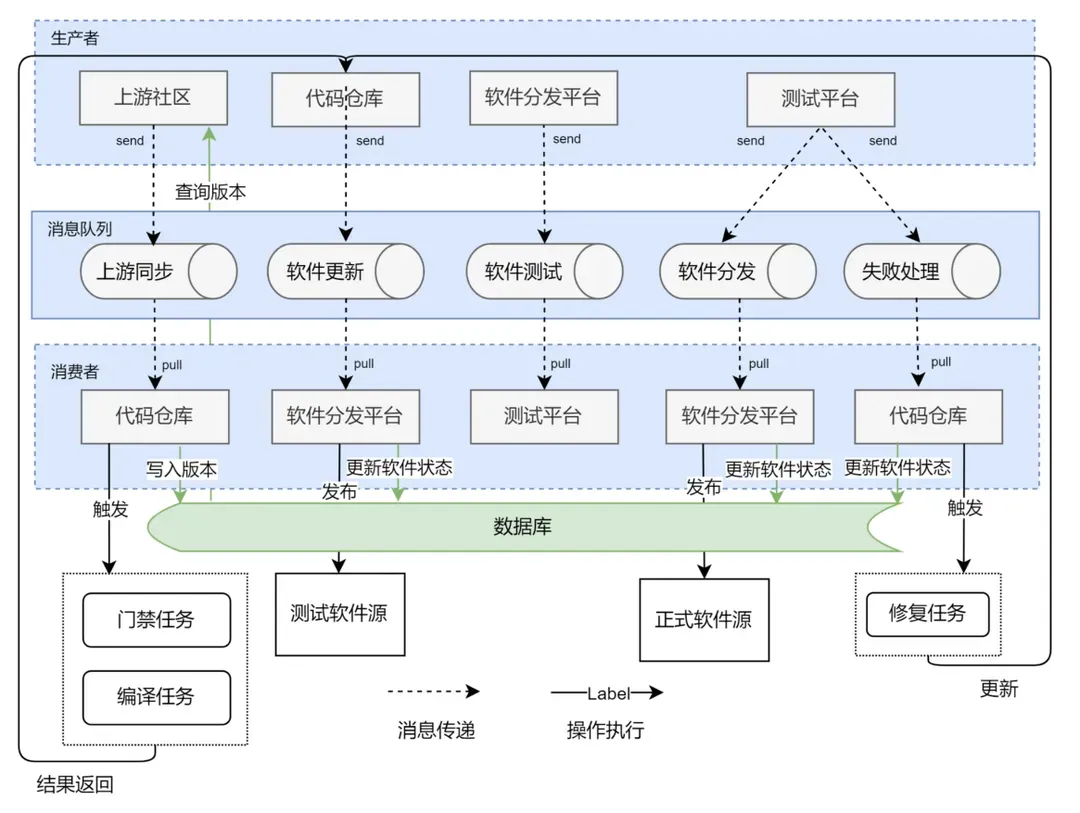
這套消息處理機制,解耦了不同流程間的依賴,僅通過統一的消息來完成整個流程的執行。并且因為消息保存在消息隊列中,下游流程不依賴上游數據的實時更新,對于執行失敗的下游任務,我們可以重新從隊列中取得對應的消息,然后從執行失敗點繼續完成后續工作。
此外,消息隊列可以驅動流程運行,但它沒有持久存儲的能力,沒法記錄并追蹤某個更新的軟件當前狀態(除非我們遍歷消息隊列),因此,我們通過數據庫來記錄某個軟件包當前處在哪個流程中,來保證每個軟件包的可追蹤性。
效果:提升平臺開發和運行效率 50%+。
三、未來展望
以上通過自動化基礎設施、工具平臺的加持,軟件包自主維護效率得到了成倍的提升,質量也得到一定保障,不過距離自主維護能力的成熟還有較大的差距。當前部分重要包已經掌握了代碼架構、重要功能的實現,但還有較多的軟件包需要逐步積累維護能力;自主可控版本的軟硬件生態與業界標桿也有差距,隨著軟硬件生態的推進,版本的兼容、穩定也會面臨一些挑戰。
項目在 systemd、glibc、gcc 等關鍵用戶態軟件包社區已經有一些貢獻,獲得了 numactl 等社區的 maintainer,不過上游社區參與度遠遠不夠,聲量及影響力仍然很弱。
當前 AI、異構等新場景不斷涌現,開發者、管理員、企業等需求日新月異,傳統的 OS 也需要與時俱進、不斷創新,才能保持生命力。千里之行始于足下,自主維護能力建設已經邁出了堅實的一步,剩下的就是腳踏實地,一步一個腳印,把自主可控做實做深。























