













用Pyjanitor消除數據清洗(Data Cleaning)中的煩惱
從數據分析到EDA(探索性數據分析/exploratory data analysis)再到機器學習模型,數據集的質量和完整性都是確保分析和建模過程有效的關鍵因素。高質量、完整的數據集能夠提供更可靠、更準確的分析結果,有助于制定基于數據的決策。
數據清洗(Data Cleaning)通常被視為數據驅動決策的關鍵準備步驟,其目的在于查找并糾正數據中的錯誤和不一致,以提高數據質量。隨著數據集的增長,確保數據的清潔度和完整性變得越發具有挑戰性。了解數據清洗的重要性以及如何進行數據清洗變得至關重要。
關于數據清洗的重要性參見《一文帶您了解數據清洗的重要:數據驅動決策的關鍵步驟》或參考《數據科學/機器學習項目中處理缺失值:策略與實踐》
今天我們將介紹并示范一款優秀的數據清洗工具包,能夠加速并簡化數據清洗的過程:pyjanitor。
pyjanitor 是什么?
Pyjanitor是一個功能強大的Python庫,旨在簡化數據清洗的過程。作為流行的Pandas庫的擴展,Pyjanitor為數據科學家和分析師提供了額外的功能,使數據清洗變得更加高效和便捷。該庫不僅易于使用,而且高度可定制,可以滿足各種數據清洗任務的需求。通過Pyjanitor,用戶可以輕松添加和刪除列,重命名列,處理缺失值,過濾數據,進行數據分組,數據重塑,以及處理字符串和文本數據等。這些功能使Pyjanitor成為處理數據預處理挑戰的理想選擇,無論是在數據科學項目中還是日常數據分析任務中。
Pyjanitor的一些關鍵特性包括:
- 添加和刪除列
- 重命名列
- 處理缺失值
- 數據過濾
- 數據分組
- 數據重塑
- 處理字符串和文本數據
使用Pyjanitor進行數據清洗的一些關鍵優勢包括:
- 簡化了數據清洗的流程
- 節省時間和精力
- 提供了豐富的數據清洗和準備功能
- 高度可定制和靈活
- 與Pandas和其他流行的Python庫兼容
安裝pyjanitor
pipinstall pyjanitor
pyjanitor簡單示例
import pandas as pd
import janitor
# Read the dataset
df = pd.read_csv('heart_disease_uci.csv')
# Clean the column names
df = df.clean_names()
# Droping the unnecessary columns
df = df.remove_columns(['ca', 'thal'])
# Convert the trestbps to a float
df['trestbps'] = df['trestbps'].astype(float)
# Sort the dataframe by the trestbps column in descending order
df = df.sort_values(by='trestbps', ascending=False)
# Save the cleaned dataframe to a new CSV file
df.to_csv('cleaned_heart_disease_uci.csv', index=False)
在這個示例中,首先導入了必要的庫,包括Pyjanitor。然后使用Pandas的read_csv函數讀取數據集。接著,使用Pyjanitor的clean_names函數來標準化列名。然后使用remove_columns函數刪除任何不必要的列。使用astype方法將工資列轉換為浮點數。最后,使用sort_values方法按照工資列的降序對數據框進行排序,并使用to_csv方法將清理后的數據框保存到新的CSV文件中。
API 方式
有三種使用API的方法。第一種,也是最強烈推薦的方法,是將pyjanitor的函數用作Pandas的本地函數。
import pandas as pd
import numpy as np
company_sales = {
'SalesMonth': ['Jan', 'Feb', 'Mar', 'April'],
'Company1': [150.0, 200.0, 300.0, 400.0],
'Company2': [180.0, 250.0, np.nan, 500.0],
'Company3': [400.0, 500.0, 600.0, 675.0]
}
import janitor # upon import, functions are registered as part of pandas.
# This cleans the column names as well as removes any duplicate rows
df = pd.DataFrame.from_dict(company_sales).clean_names().remove_empty()
df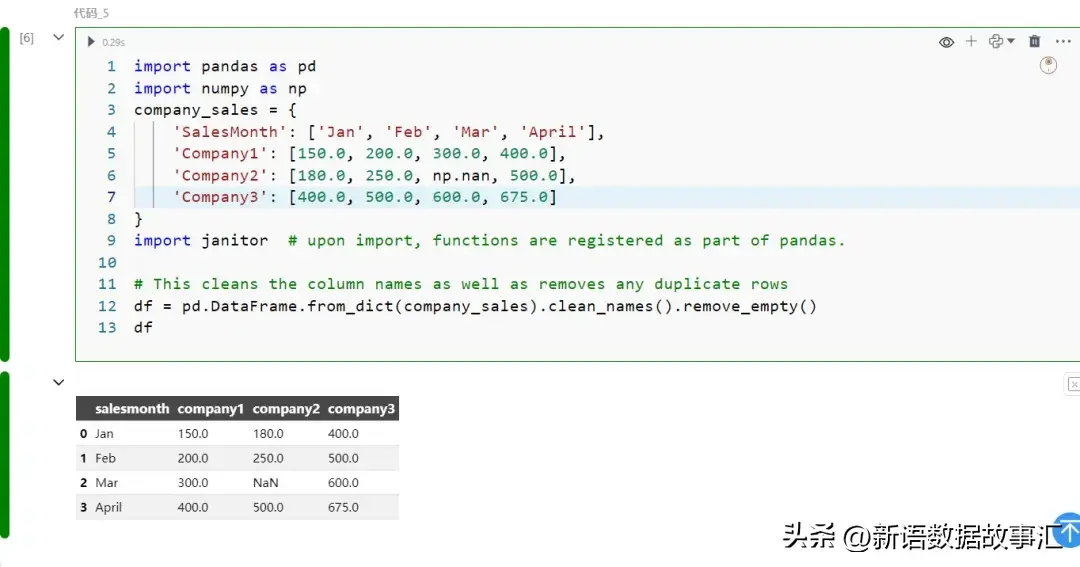
第二種方法是函數式API。
import pandas as pd
import numpy as np
company_sales = {
'SalesMonth': ['Jan', 'Feb', 'Mar', 'April'],
'Company1': [150.0, 200.0, 300.0, 400.0],
'Company2': [180.0, 250.0, np.nan, 500.0],
'Company3': [400.0, 500.0, 600.0, 675.0]
}
from janitor import clean_names, remove_empty
df = pd.DataFrame.from_dict(company_sales)
df = clean_names(df)
df = remove_empty(df)
df
最后一種方法是使用pipe()方法:
import pandas as pd
import numpy as np
company_sales = {
'SalesMonth': ['Jan', 'Feb', 'Mar', 'April'],
'Company1': [150.0, 200.0, 300.0, 400.0],
'Company2': [180.0, 250.0, np.nan, 500.0],
'Company3': [400.0, 500.0, 600.0, 675.0]
}
from janitor import clean_names, remove_empty
df = (
pd.DataFrame.from_dict(company_sales)
.pipe(clean_names)
.pipe(remove_empty)
)
df
填充的函數示例:fill_direction(df, **kwargs)
提供一個可鏈式調用的方法,用于填充所選列中的缺失值。
它是pd.Series.ffill和pd.Series.bfill的包裝器,并將列名與up、down、updown和downup中的一個配對使用。
import pandas as pd
import janitor as jn
df = pd.DataFrame(
{
'col1': [1, 2, 3, 4],
'col2': [None, 5, 6, 7],
'col3': [8, 9, 10, None],
'col4': [None, None, 11, None],
'col5': [None, 12, 13, None]
}
)
print(df)
df1=df.fill_direction(
col2 = 'up',
col3 = 'down',
col4 = 'downup',
col5 = 'updown'
)
print(df1)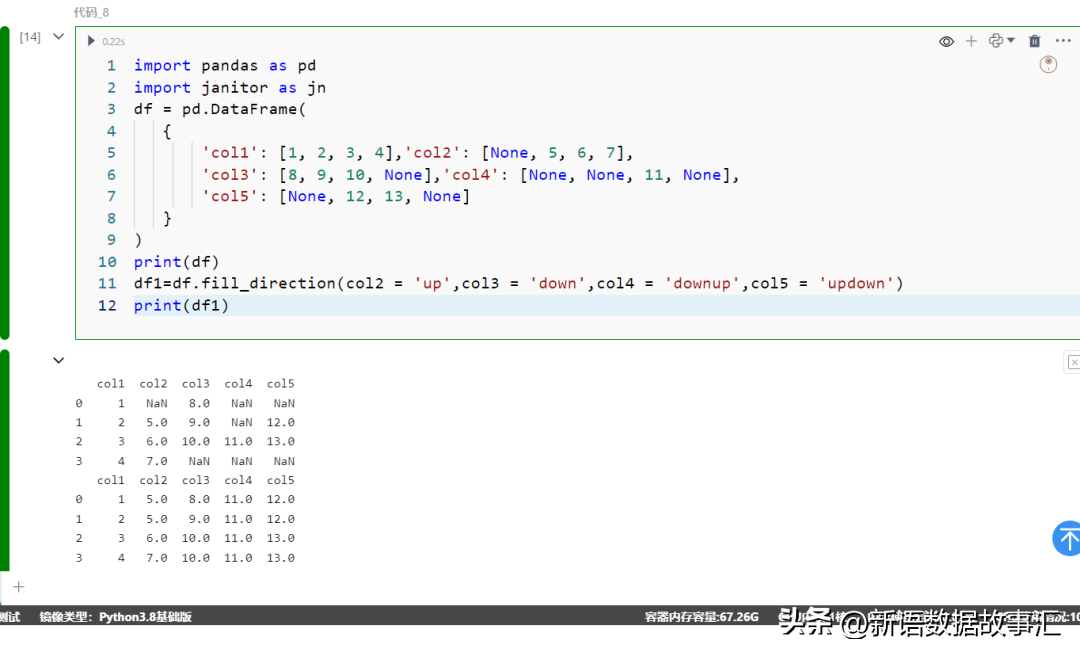
添加新功能(functionality)
需要定義一個函數,該函數表達了數據處理/清理的流程。該函數應接受一個DataFrame作為第一個參數,并返回一個修改過的DataFrame。
import pandas_flavor as pf
@pf.register_dataframe_method
def my_data_cleaning_function(df, arg1, arg2, ...):
# Put data processing function here.
return dfPyjanitor 提供了簡化和自動化數據清洗過程的解決方案,旨在使數據清洗更快速、更高效。作為一個功能強大且多功能的包,Pyjanitor 的集成可以幫助您節省時間,讓您將更多精力投入到數據分析和解釋上。













