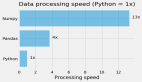
時間序列數據處理,不再使用Pandas
本文中,云朵君和大家一起學習了五個Python時間序列庫,包括Darts和Gluonts庫的數據結構,以及如何在這些庫中轉換pandas數據框,并將其轉換回pandas。
Pandas DataFrame通常用于處理時間序列數據。對于單變量時間序列,可以使用帶有時間索引的 Pandas 序列。而對于多變量時間序列,則可以使用帶有多列的二維 Pandas DataFrame。然而,對于帶有概率預測的時間序列,在每個周期都有多個值的情況下,情況又如何呢?圖(1)展示了銷售額和溫度變量的多變量情況。每個時段的銷售額預測都有低、中、高三種可能值。盡管 Pandas 仍能存儲此數據集,但有專門的數據格式可以處理具有多個協變量、多個周期以及每個周期具有多個樣本的復雜情況。
 圖片
圖片
在時間序列建模項目中,充分了解數據格式可以提高工作效率。本文的目標是介紹 DarTS、GluonTS、Sktime、pmdarima 和 Prophet/NeuralProphet 庫的數據格式。由于 Sktime、pmdarima 和 Prophet/NeuralProphet 都與 pandas 兼容,因此只需花更多時間學習。
- DarTS
- GluonTS
Pandas DataFrame是許多數據科學家的基礎。學習的簡單方法是將其轉換為其他數據格式,然后再轉換回來。本文還將介紹長格式和寬格式數據,并討論庫之間的轉換。
請用 pip 安裝以下庫:
!pip install pandas numpy matplotlib darts gluonts
!pip install sktime pmdarima neuralprophet獲取長式數據集
加載一個長式數據集。
這里我們將使用Kaggle.com上的沃爾瑪數據集,其中包含了45家商店的多元時間序列數據。我們選擇這個數據集是因為它是一個長式數據集,所有組的數據都是垂直堆疊的。該數據集以Pandas數據幀的形式加載。
data = pd.read_csv('/walmart.csv', delimiter=",")
# 數據獲取:公眾號:數據STUDIO 后臺回復 云朵君
data['ds'] = pd.to_datetime(data['Date'], format='%d-%m-%Y')
data.index = data['ds']
data = data.drop('Date', axis=1)
data.head()將字符串列 "Date" 轉換為 Pandas 中的日期格式是十分關鍵的,因為其他庫通常需要日期字段采用 Pandas 數據時間格式。圖(2)展示了最初的幾條記錄。
 圖(2):沃爾瑪數據
圖(2):沃爾瑪數據
該數據集包含
- Date - 日期 - 銷售周
- Store - 商店 - 商店編號
- Weekly sales - 周銷售額 - 商店的銷售額
- Holiday flag - 假日標志 - 本周是否為特殊假日周 1 - 假日周 0 - 非假日周
- Temperature - 溫度 - 銷售當天的溫度
- Fuel price - 燃料價格 - 該地區的燃料成本
兩個宏觀經濟指標,即消費者價格指數和失業率,對零售額有影響。沃爾瑪數據集堆疊了 45 家商店的多個序列,每家店有 143 周的數據。
使數據集成為寬格式
寬格式數據結構是指各組多元時間序列數據按照相同的時間索引橫向附加,接著我們將按商店和時間來透視每周的商店銷售額。
# 將數據透視成正確的形狀
storewide = data.pivot(index='ds', columns='Store', values='Weekly_Sales')
storewide = storewide.loc[:,1:10] # Plot only Store 1 - 10
# 繪制數據透視表
storewide.plot(figsize=(12, 4))
plt.legend(loc='upper left')
plt.title("Walmart Weekly Sales of Store 1 - 10") 圖(3): 沃爾瑪商店的銷售額
圖(3): 沃爾瑪商店的銷售額
10 家商店的每周銷售額如圖(3)所示:
: 商店銷售額曲線圖") (4): 商店銷售額曲線圖
(4): 商店銷售額曲線圖
檢查一下時間索引,它是一個 Pandas DateTimeIndex。
print(storewide.index) 圖片
圖片
除了每周商店銷售額外,還可以對其他任何列進行同樣的長格式到寬格式的轉換。
Darts
Darts 庫是如何處理長表和寬表數據集的?
Python的時間序列庫darts以投擲飛鏢的隱喻為名,旨在幫助數據分析中的準確預測和命中特定目標。它為處理各種時間序列預測模型提供了一個統一的界面,包括單變量和多變量時間序列。這個庫被廣泛應用于時間序列數據科學。
Darts的核心數據類是其名為TimeSeries的類。它以數組形式(時間、維度、樣本)存儲數值。
- 時間:時間索引,如上例中的 143 周。
- 維度:多元序列的 "列"。
- 樣本:列和時間的值。在圖(A)中,第一周期的值為 [10,15,18]。這不是一個單一的值,而是一個值列表。例如,未來一周的概率預測值可以是 5%、50% 和 95% 量級的三個值。習慣上稱為 "樣本"。
Darts--來自長表格式 Pandas 數據框
轉換長表格式沃爾瑪數據為darts格式只需使用from_group_datafrme()函數,需要提供兩個關鍵輸入:組IDgroup_cols和時間索引time_col。在這個示例中,group_cols是Store列,而time_col是時間索引ds。
from darts import TimeSeries
darts_group_df = TimeSeries.from_group_dataframe(data, group_cols='Store', time_col='ds')
print("The number of groups/stores is: ", len(darts_group_df))
print("The number of time period is: ", len(darts_group_df[0]))商店 1 的數據存儲在 darts_group_df[0] 中,商店 2 的數據存儲在 darts_group_df[1] 中,以此類推。一共有 45 個商店,因此飛鏢數據 darts_group_df 的長度為 45。每個商店有 143 周,因此商店 1 darts_group_df[0] 的長度為 143。
The number of groups/stores is: 45
The number of time period is: 143darts_group_df 圖(5):沃爾瑪商店銷售數據的darts數據格式
圖(5):沃爾瑪商店銷售數據的darts數據格式
圖 (5) 表示(ds: 143,component:6,sample:1)143 周,6 列,每個商店和周有 1 個樣本。商店 1 的數據為 darts_group_df[0]。可以使用 .components 函數列出列名。
darts_group_df[0].componentsIndex([‘Weekly_Sales’, ‘Holiday_Flag’, ‘Temperature’, ‘Fuel_Price’, ‘CPI’,
‘Unemployment’], dtype=’object’, name=’component’)Darts--從寬表格式的pandas數據框轉換
繼續學習如何將寬表格式數據框轉換為darts數據結構。
你只需使用 Darts 中 TimeSeries 類的.from_dataframe()函數:
from darts import TimeSeries
darts_df = TimeSeries.from_dataframe(storewide)
darts_df輸出結果如圖 (F) 所示:
 圖(6):Darts數據數組
圖(6):Darts數據數組
圖(6)表示(ds: 143, component:10, sample:1)143 周、10 列以及每個商店和周的 1 個樣本。可以展開小圖標查看組件,組件指的是列名。
Darts--繪圖
如何使用 Darts 繪制曲線?
繪圖語法與 Pandas 中的一樣簡單。只需執行 .plot():
darts_df.plot() 圖(7):10個序列的曲線圖
圖(7):10個序列的曲線圖
Darts--單變量 Pandas 序列
如果我們只有一個序列呢?如何轉換為 Darts?
列 storewide[1] 是商店 1 的 Pandas 序列。可以使用 .from_series() 將 Pandas 序列方便地轉換為 Darts:
darts_str1 = TimeSeries.from_series(storewide[1])
darts_str1圖 (8) 顯示了輸出結果。如 (ds:143, component:1, sample:1) 所示,每周有 143 周、1 列和 1 個樣本。
 圖(8):序列的數據結構
圖(8):序列的數據結構
繪制過程如圖(9)所示:
darts_str1.plot() 圖(9):單變量的曲線圖
圖(9):單變量的曲線圖
Darts - 轉換回 Pandas
如何將 Darts 數據集轉換回 Pandas 數據框?
只需使用 .pd_dataframe():
# 將 darts 數據框轉換為 pandas 數據框
darts_to_pd = TimeSeries.pd_dataframe(darts_df)
darts_to_pd輸出結果是一個二維 Pandas 數據框:

不是所有的Darts數據都可以轉換成二維Pandas數據框。比如一周內商店的概率預測值,無法存儲在二維Pandas數據框中,可以將數據輸出到Numpy數組中。
Darts--轉換為 Numpy 數組
Darts 可以讓你使用 .all_values 輸出數組中的所有值。缺點是會丟棄時間索引。
# 將所有序列導出為包含所有序列值的 numpy 數組。
# https://unit8co.github.io/darts/userguide/timeseries.html#exporting-data-from-a-timeseries
TimeSeries.all_values(darts_df) 圖片
圖片
學習了 Darts 的數據結構后,再學習另一個流行的時間序列庫 - Gluonts 的數據結構。
Gluonts
Gluonts是亞馬遜開發的處理時間序列數據的Python庫,包含多種建模算法,特別是基于神經網絡的算法。這些模型可以處理單變量和多變量序列,以及概率預測。Gluonts數據集是Python字典格式的時間序列列表。可以將長式Pandas數據框轉換為Gluonts。
Gluonts--從長表格式 Pandas 數據框
gluons.dataset.pandas 類有許多處理 Pandas 數據框的便捷函數。要在 Pandas 中加載長表格式數據集,只需使用 .from_long_dataframe():
# Method 1: from a long-form
from gluonts.dataset.pandas import PandasDataset
data_long_gluonts = PandasDataset.from_long_dataframe(
data,
target="Weekly_Sales",
item_id="Store",
timestamp='ds',
freq='W')
data_long_gluonts打印 Gluonts 數據集時,會顯示元數據:
PandasDataset<size=45, freq=W, num_feat_dynamic_real=0,
num_past_feat_dynamic_real=0,
num_feat_static_real=0,
num_feat_static_cat=0,
static_cardinalities=[]>Gluonts--從寬表格式的 Pandas 數據框
PandasDataset() 類需要一個時間序列字典。因此,首先要將寬表 Pandas 數據框轉換為 Python 字典,然后使用 PandasDataset():
# Method 2: from a wide-form
from gluonts.dataset.pandas import PandasDataset
data_wide_gluonts = PandasDataset(dict(storewide))
data_wide_gluonts通常,我們會將 Pandas 數據框分成訓練數據("實時")和測試數據("非實時"),如下圖所示。
len_train = int(storewide.shape[0] * 0.85)
len_test = storewide.shape[0] - len_train
train_data = storewide[0:len_train]
test_data = storewide[len_train:]
[train_data.shape, test_data.shape] # The output is [(121,5), (22,5)如前所述,Gluonts 數據集是 Python 字典格式的數據列表。我們總是可以使用 Gluonts 中的 ListDataset()類。我們使用 ListDataset() 轉換數據:
Gluonts - ListDataset() 進行任何常規轉換
Gluonts 數據集是 Python 字典格式的時間序列列表,可使用 ListDataset() 作為一般轉換工具,該類需要時間序列的基本元素,如起始時間、值和周期頻率。
將圖(3)中的寬格式商店銷售額轉換一下。數據幀中的每一列都是帶有時間索引的 Pandas 序列,并且每個 Pandas 序列將被轉換為 Pandas 字典格式。字典將包含兩個鍵:字段名.START 和字段名.TARGET。因此,Gluonts 數據集是一個由 Python 字典格式組成的時間序列列表。
def convert_to_gluonts_format(dataframe, freq):
start_index = dataframe.index.min()
data = [{
FieldName.START: start_index,
FieldName.TARGET: dataframe[c].values,
}
for c in dataframe.columns]
#print(data[0])
return ListDataset(data, freq=freq)
train_data_lds = convert_to_gluonts_format(train_data, 'W')
test_data_lds = convert_to_gluonts_format(test_data, 'W')
train_data_lds生成的結果是由Python字典列表組成,其中每個字典包含 start 關鍵字代表時間索引,以及 target 關鍵字代表對應的值。
 圖片
圖片
Gluonts - 轉換回 Pandas
如何將 Gluonts 數據集轉換回 Pandas 數據框。
Gluonts數據集是一個Python字典列表。要將其轉換為Python數據框架,首先需使Gluonts字典數據可迭代。然后,枚舉數據集中的鍵,并使用for循環進行輸出。
在沃爾瑪商店的銷售數據中,包含了時間戳、每周銷售額和商店 ID 這三個關鍵信息。因此,我們需要在輸出數據表中創建三列:時間戳、目標值和索引。
# 將 gluonts 數據集轉換為 pandas 數據幀
# Either long-form or wide-form
the_gluonts_data = data_wide_gluonts # you can also test data_long_gluonts
timestamps = [] # This is the time index
target_values = [] # This is the weekly sales
index = [] # this is the store in our Walmart case
# Iterate through the GluonTS dataset
for i, entry in enumerate(the_gluonts_data):
timestamp = entry["start"]
targets = entry["target"]
# Append timestamp and target values for each observation
for j, target in enumerate(targets):
timestamps.append(timestamp)
target_values.append(target)
index.append(i) # Keep track of the original index for each observation
# Create a pandas DataFrame
df = pd.DataFrame({
"timestamp": timestamps,
"target": target_values,
"original_index": index
})
print(df) 圖片
圖片
Darts和Gluonts支持復雜數據結構的建模算法,可以建立多個時間序列的全局模型和概率預測。當所有時間序列中存在一致的基本模式或關系時,它就會被廣泛使用。沃爾瑪案例中的時間序列數據是全局模型的理想案例。相反,如果對多個時間序列中的每個序列都擬合一個單獨的模型,則該模型被稱為局部模型。在沃爾瑪數據中,我們將建立45個局部模型,因為有45家商店。
在熟悉了Darts和Gluonts的數據結構后,我們將繼續學習Sktime、pmdarima和Prophet/NeuralProphet的數據格式,它們與pandas兼容,因此無需進行數據轉換,這將使學習變得更加容易。
Sktime
Sktime旨在與scikit-learn集成,利用各種scikit-learn時間序列算法。它提供了統一的界面和實現常見的時間序列分析任務,簡化了時間序列數據處理過程。提供了預測、分類和聚類等算法,可用于處理和分析時間序列數據。
import lightgbm as lgb
from sktime.forecasting.compose import make_reduction
lgb_regressor = lgb.LGBMRegressor(num_leaves = 10,
learning_rate = 0.02,
feature_fraction = 0.8,
max_depth = 5,
verbose = 0,
num_boost_round = 15000,
nthread = -1
)
lgb_forecaster = make_reduction(lgb_regressor, window_length=30, strategy="recursive")
lgb_forecaster.fit(train)Pmdarima
Pmdarima是Python封裝程序,基于流行的"statsmodels"庫,將ARIMA和SARIMA模型合并在一起。它能自動選擇最佳ARIMA模型,功能強大且易于使用,接受一維數組或pandas Series作為數據輸入。
import pmdarima as pm
model = pm.auto_arima(train,
d=None,
seasnotallow=False,
stepwise=True,
suppress_warnings=True,
error_actinotallow="ignore",
max_p=None,
max_order=None,
trace=True) 圖片
圖片
Prophet/NeuralProphet
Prophet是Facebook開發的時間序列預測庫,具有自動檢測季節性模式、處理缺失數據以及納入假日效應的能力。它擁有用戶友好的界面和交互式plotly風格的輸出,分析師幾乎不需要人工干預即可生成預測結果。Prophet因其靈活的趨勢建模功能和內置的不確定性估計而深受歡迎。該庫可用于執行單變量時間序列建模,需要使用Pandas數據框架,其中列名為['ds', 'y']。
這里加載了一個 Pandas 數據框 "bike" 來訓練一個 Prophet 模型。
import pandas as pd
from prophet import Prophet
bike.columns = ['ds','y']
m = Prophet()
m.fit(bike)Prophet的圖像很吸引人。
 圖(10):Prophet
圖(10):Prophet
NeuralProphet是基于先知框架的神經網絡架構,加強了先知的加法模型,允許更靈活、更復雜地對時間序列數據進行建模。它集成了Prophet的優勢,包括自動季節性檢測和假日效應處理,并專注于單變量時間序列預測。以下是一個使用Pandas數據幀來訓練NeuralProphet模型的示例。
from neuralprophet import NeuralProphet
df = pd.read_csv(path + '/bike_sharing_daily.csv')
# Create a NeuralProphet model with default parameters
m = NeuralProphet()
# Fit the model
metrics = m.fit(df)它的繪圖能力就像Prophet一樣吸引人。
圖(11): neuralprophet
結論
本文中,云朵君和大家一起學習了五個Python時間序列庫,包括Darts和Gluonts庫的數據結構,以及如何在這些庫中轉換pandas數據框,并將其轉換回pandas。此外,還介紹了Sktime、pmdarima和Prophet/NeuralProphet庫。這些庫都有各自的優勢和特點,選擇使用哪個取決于對速度、與其他Python環境的集成以及模型熟練程度的要求。