MongoDB索引使用總結
作者 | mingkai
MongoDB 是目前最流行的文檔型數據庫。MongoDB 的采用類 json 的存儲格式對開發者來說非常友好。本文梳理了 MongoDB 索引的底層結構以及使用經驗,不足之處歡迎大家指正。

一、背景
MongoDB 提供范圍廣泛的索引類型和功能以及特定于語言的排序順序,以支持對數據的復雜訪問模式。 MongoDB 索引可以按需創建和刪除來適應不斷變化的應用程序需求和查詢模式,并且可以在文檔中的任何字段上聲明,包括嵌套在數組中的字段。本文介紹一下 MongoDB 中的索引底層結構、索引遍歷過程、建索引以及如何使用。
二、基本使用
1.分類
MongoDB 中的索引與其他數據庫系統中的索引類似。 MongoDB 在集合級別定義索引,并支持 MongoDB 集合中文檔的任何字段或子字段的索引。 常見的有以下類型: 鍵索引、復合索引、多鍵索引、地理空間索引、全文本索引和哈希索引。
2.創建/刪除/隱藏
(1) MongoDB 使用 createIndex() 方法來創建索引:
`db.collection.createIndex(keys, options)`語法中 Key 值為你要創建的索引字段,1 為指定按升序創建索引,如果你想按降序來創建索引指定為 -1 即可。
`db.col.createIndex({"a":1})`createIndex() 方法中你也可以設置使用多個字段創建索引(關系型數據庫中稱作復合索引)。
db.col.createIndex({"a":1,"b":-1})(2) 刪除索引:
db.collection.dropIndex刪除索引在底層直接刪除文件,然后修改元數據。
(3) 從 4.4 開始支持隱藏索引
db.collection.hideIndex(<index>)在刪除索引前,可以先隱藏索引,查看集群是否異常后,才真正刪除索引, 可有效幫助業務判斷索引是否可以刪除。
三、數據結構
1.底層文件存儲
MongoDB 底層是如何存儲數據的,一個 collection 一個文件嗎?索引在底層是如何組織的? 一個 collection 對應到底層存儲引擎就是一個文件,另外每個索引也是單獨的文件,每個數據和索引文件的默認結構是 b 樹,用戶建表的時候也可以指定 lsm 結構,不過絕大多數用戶基本都是使用 b 樹結構,本文的討論主要圍繞 b 樹這種結構來進行。
比如用戶建一個普通的表,默認會帶一個_id 索引,會產生倆個文件,一個文件存放數據,一個存放_id 索引,這倆個文件通過 RecordId 來連接,用戶每插入一條數據,mongo 會生成一條與之對應的自增的 RecordId, 不過用戶不感知,RecordId 是與 mysql 中的自增主鍵類似。數據文件是 RecordId 到數據的映射, _id 索引文件是_id 到 RecordId 的映射,如果通過指定_id 查詢,會現在_id 索引文件中找到 RecordId, 然后再到數據文件中查詢數據,如果用戶再新建索引,那么在 wt 就會再新建一個文件,同樣按 b 樹組織,該文件記錄了索引到 RecordId 的映射,用戶使用索引查詢時,同樣的如同_id 索引,先找到 RecordId, 然后再到數據文件中查詢數據。
可以通過以下方式查找數據對應的RecordId
PRIMARY> db.coll.find().showRecordId()
{ "_id" : ObjectId("647861f72b531acaacf4afb2"), "a" : 1, "b" : 1, "$recordId" : NumberLong(1) }
{ "_id" : ObjectId("647861fa2b531acaacf4afb3"), "a" : 1, "b" : 2, "$recordId" : NumberLong(2) }2.底層格式存儲
在 MongoDB 的 Schema-free 架構下,索引字段可以存儲不同類型的值,在索引 b 樹中,有個基本的問題,實現不同類型的比較呢? MongoDB 通過 BSON 結構來存儲數據,具體結構的解析可見BSON 結構解析 ,并且規定了不同類型之間的大小關系。
1. MinKey (internal type)
2. Null
3. Numbers (ints, longs, doubles, decimals)
4. Symbol, String
5. Object
6. Array
7. BinData
8. ObjectId
9. Boolean
10. Date
11. Timestamp
12. Regular Expression
13. MaxKey (internal type)在這個限制下, 就只需要對比同種類型的大小了,BSON 的基本比較流程如下:先比較類型,如果類型一樣才使用 BSONElement::compareElements 比較值。
但是對于索引如果直接使用上述方法去做大小比較,具有以下的倆個缺點:
- BSONElement::compareElements 的性能低,主要是 BSON 結構的序列化和反序列化;
- BSON 結構是 MongoDB 定義的,對于 wt 引擎層是無法識別。
3.高效的二進制比較方式-keystring
(1) 簡介
在 MongoDB 中設計了 KeyString 結構,將所有類型可以歸一化為 string, 然后使用 memcmp 進行二進制比較。 KeyString 的組成方式為:
`字段1類型 + 字段1二進制 + 字段2類型 + 字段2二進制 + ... + <discriminator> + 結尾標識符(0x04) + <recordId>`那 KeyString 是怎么轉的呢?類型之間有大小關系,那么 keystring 的前幾個字節必定與類型相關,實際上使用第一個字節來存儲類型, 相關類型定義如下:
const uint8_t kMinKey = 10;
const uint8_t kUndefined = 15;
const uint8_t kNullish = 20;
const uint8_t kNumeric = 30;
const uint8_t kStringLike = 60;
const uint8_t kObject = 70;
const uint8_t kArray = 80;
const uint8_t kBinData = 90;
const uint8_t kOID = 100;
const uint8_t kBool = 110;
const uint8_t kDate = 120;
const uint8_t kTimestamp = 130;
const uint8_t kRegEx = 140;
const uint8_t kDBRef = 150;
const uint8_t kCode = 160;
const uint8_t kCodeWithScope = 170;
const uint8_t kMaxKey = 240;(2) 字符串和數字轉換
下面通過常用的字符串以及數字類型來舉例說明, 如一條文檔{a:"abcd"} ,索引為{a:1}, 生成的 keystring 為:

各個字段的含義為:
- 類型為 60,表示 string 類型;
- 值為 97 98 99 100 0,對應了“abcd”的 ASCII 碼, 最后的 0x00 表示字符串類型結束;
- 整個 keyString 的結束符 kEnd 等于 4。 方便演示,將類型和值的轉換記作 ks, 結束符為 kEnd,即:
ks("abcd") + kEnd = 60 97 98 99 100 0 4如果一條文檔{a:"abcd", b:"a" } ,索引為{a:1,b:1}, 那么生成的 keystring 為:
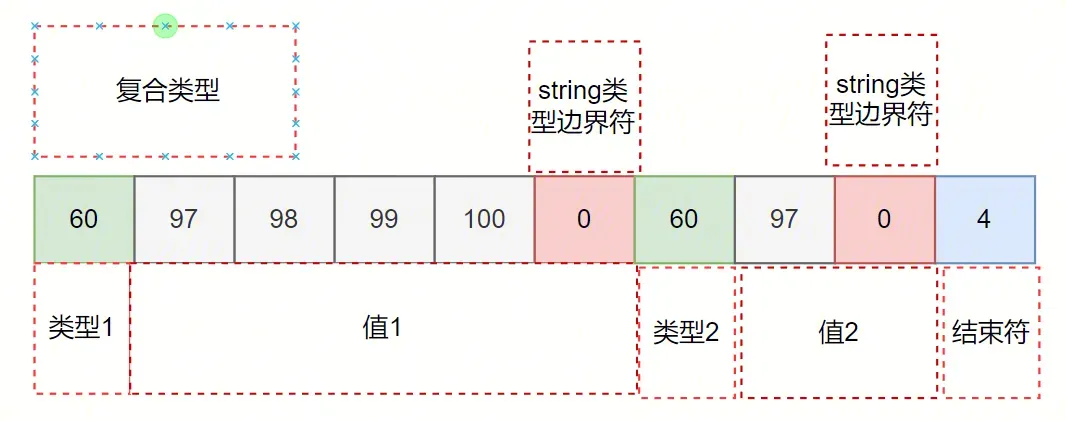
再看下整數類型: {a:"NumberInt(1)}, 對應的 KeyString 為:
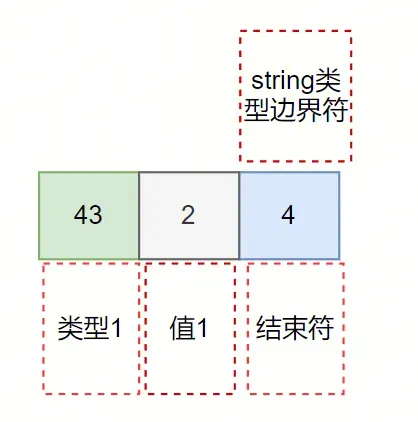
與 string 類型相比 43 要比 60 要小, 所以不同類型可以通過第一個字節快速比較大小。 同樣的 4 表示結束符, 43 表示類型, 2 表示 value, 這里有倆個問題 1) 為什么不使用類型值不是 kNumeric=30 呢? 2) value 為什么不是 1, 而是 2 呢? 帶著以上問題,接下來詳細分析下最復雜的數值類型轉換。
(3) 數值類型轉換
數字類型比較是最復雜的方法,個整性數可以大端存儲然后對比大小,但是涉及到實現整性數和浮點數的比較問題就復雜了。 為了解決上述問題, 按照數字所需要占用字節的大小和正負劃分了 22 種數字類型, 如下:
const uint8_t kNumericNaN = kNumeric + 0;
const uint8_t kNumericNegativeLargeMagnitude = kNumeric + 1; // <= -2**63 including -Inf
const uint8_t kNumericNegative8ByteInt = kNumeric + 2;
const uint8_t kNumericNegative7ByteInt = kNumeric + 3;
const uint8_t kNumericNegative6ByteInt = kNumeric + 4;
const uint8_t kNumericNegative5ByteInt = kNumeric + 5;
const uint8_t kNumericNegative4ByteInt = kNumeric + 6;
const uint8_t kNumericNegative3ByteInt = kNumeric + 7;
const uint8_t kNumericNegative2ByteInt = kNumeric + 8;
const uint8_t kNumericNegative1ByteInt = kNumeric + 9;
const uint8_t kNumericNegativeSmallMagnitude = kNumeric + 10; // between 0 and -1 exclusive
const uint8_t kNumericZero = kNumeric + 11;
const uint8_t kNumericPositiveSmallMagnitude = kNumeric + 12; // between 0 and 1 exclusive
const uint8_t kNumericPositive1ByteInt = kNumeric + 13;
const uint8_t kNumericPositive2ByteInt = kNumeric + 14;
const uint8_t kNumericPositive3ByteInt = kNumeric + 15;
const uint8_t kNumericPositive4ByteInt = kNumeric + 16;
const uint8_t kNumericPositive5ByteInt = kNumeric + 17;
const uint8_t kNumericPositive6ByteInt = kNumeric + 18;
const uint8_t kNumericPositive7ByteInt = kNumeric + 19;
const uint8_t kNumericPositive8ByteInt = kNumeric + 20;
const uint8_t kNumericPositiveLargeMagnitude = kNumeric + 21; // >= 2**63 including +Inf那么劃分類型的依據是哪些呢?
- 存儲時,只存絕對值,正負是不同的類型, 可以加速判斷,負數一定比整數小;
- 根據數字整數部分所需要占用字節的大小來區分不同類型;
- 特殊范圍的值 大數大于等于2**63包括+Inf , -小于等于2**63包括-Inf, (0,1.0) ,(-1.0,0)等,
- 特殊值特殊處理,比如:0、NaN 等; 總的來說通過數字的不同范圍區分了不同的類型, 不僅可以節省空間,一定也能加速大小比較判斷,不同字節數的數字只需判斷類型即可。
特殊范圍的值 這些值只能是浮點數類型這些子類型的 Double 的編碼相對容易很多,只需要按照 Double 原有格式稍作處理,然后使用大端模式編碼即可;
問題是如何對比存在交集的值,比如整數 1 和浮點數 1.5, 先看下以上倆個值轉成 keyString:

- 同樣的最后的 4 表示結束符;
- 43 表示了 kNumericPositive1ByteInt 類型,并且需要空出一個 bit 來表示數字是否包含小數部分,如果沒有小數部分就將其設置位 0, 有小數部分就將其設置為 1,所以上述提到的{a:1} 對應的值就為 1 左移 1 位再將最后一個 bit 標識為 0,等于 2;{a:1.5}對應的整數值為 1 左移 1 位再將最后一個 bit 標識為 1, 結果就是 3, kNumericPositive1ByteInt 中的 1Byte 表現在一個數的整數左移一位所需要的 byte 數為 1, 如果浮點數沒有小數部分最后一個 bit 也要標識為 0;
- 128 0 0 0 0 0 0 表示小數部分,表示 0.5,整數部分加小數部分加起來一共 8 位,剩下 7 個 byte 來表示小數部分。
為什么需要用最后一個 1bit 位來表示是否含有小數部分呢?如果沒有這個 bit 位, 倆個數整數部分長一樣的話,Double 的小數部分要和 Int 后面的結束符 0x4 來比較了,避免比較出現的誤差,還能加快比較;double 本身是 8 位, 現在轉成 keyString 還是 8 位。雖然上面提到浪費了一個 bit 來表示是否包含小數部分,現在 8 位只表示絕對值了,正負在類型體現了,不會有精度的丟失。對于小數部分為 0 的浮點數, 生成的 keystring 與與之對應的整數一樣。
(4) keyString 的優點
- 轉換成二進制, 優秀的比較性能;
- 可以實現不同類型的快速比較;
- 針對數值類型進行細化,解決了整數類型和浮點數類型轉換的兼容性問題, 以及節省存儲成本。
(5) 在索引中的使用
MongoDB 中使用索引查詢數據會有 2 個階段:
- 查索引,通過索引字段的 KeyString 找到對應的 RecordId;
- 查數據, 根據 RecordId 找到 BSON 文檔;

(/tencent/api/attachments/s3/url?attachmentid=2948416)
就是說普通索引在底層引擎中索引 b 樹中的 key:
ks(索引field對應的值) + kEnd + RecordId_id 索引在底層引擎中索引 b 樹中的 key:
ks(索引field對應的值) + kEnd① 普通索引的 key 包含 RecordId
非唯一普通索引的 key 包含 RecordId,是因為 WT 引擎中的 Key 是唯一的,但是索引中的 Key 是不唯一的。比如 {a: 1} 索引,很多條 BSON 文檔的 "a" 字段都能等于 1,因此在存儲索引的時候必須通過方法進行區分。 在 MongoDB 中,由于每個文檔都有獨立的 RecordId,這樣將 RecordId 作為后綴就能保證唯一性。
② 唯一索引的 key 也包含 RecordId
普通的唯一索引,上述問題不存在, 但是為什么唯一索引的 key 也包含 RecordId 呢? 主要是為了解決主從同步的時,從節點的 oplog 并發回放的,回放時的亂序可能會臨時打破索引的唯一性質。舉個例子,主上依次進行以下三個操作: insert {_id:1, a:1} remove {_id:1} 和 insert {_id:2, a:1}。a 字段為唯一索引, 從上根據_id 做 hash 然后并發回放時 一個線程回放 insert {_id:1, a:1}和 remove {_id:1},另外一個回放 insert {_id:2, a:1}。 remove {_id:1} 和 insert {_id:2, a:1}的順序得不到保證,最終可能的一種順序為: insert {_id:1, a:1}, insert {_id:2, a:1}以及 remove {_id:1}, 對 a 索引進行重復插入了{a:1}, 所以回放時就得暫時不檢查 a 索引的唯一性,需要按照上述的方式采用 RecordId 作為后綴。
但是使用 RecordId 后綴方式之后,主節點數據寫數據時索引唯一性的檢查邏輯會更復雜。
在數據插入前的檢測邏輯如下:需要在索引中要插入帶 RecordId 的 Key, 格式為: ks1+RecordId。首先會先將 RecordId 后綴去掉,插入 ks1,然后將其 Remove 掉,先插入后刪除 KeyString 的操作利用了 wt 引擎樂觀鎖的特性,構成了寫沖突的條件; 假設此時來了另外一個的插入操作, KeyString 相同但是 RecordId 不同,也得需要先插入 ks1, 但是 wt 引擎檢查到 KeyString 已經被修改,該操作拋出異常;所以先插入后刪除 KeyString 保證了對一個 KeyString 同時只能有一個索引唯一性的檢查; 最后就到了實際的重復 key 檢查邏輯, 找到第一條大于等于 ks1 的數據, 如果該數據的 key 前綴也正好 ks1,那么索引唯一性檢查失敗。
_id 也是(自帶的)唯一索引,為啥就能把 RecordId 放在 Value 部分呢?因為 oplog 回放首先會通過 _id 進行 hash 分桶,然后多個桶之間并發回放。也就是說 _id 不會存在亂序回放的問題,因此將 RecordId 擋在 Value 部分是沒問題的,并且對于唯一索引的插入,沒有索引唯一性的檢查邏輯,性能也就沒有損耗。
四、建立索引
1.簡介
在使用數據庫過程中一般的建議是先建好索引,然后再進行業務的操作, 不過也存在一些場景由于前期設計不合理, 在數據量比較大時需要給表增加索引,以 4.0 為例有以下倆種建索引的方式, 前臺建索引和后臺建索引倆種方式。
2.前后臺建索引
默認情況下,使用前臺建索引,不過因為持有 db 的寫鎖, 將阻塞 db 其他的所有操作。即該 db 上的集合的無法正常讀寫,直到索引創建完畢。 如果不想影響業務的使用,就需要指定參數{background:1}, 使用后臺建索引的方式,但是耗費的時間會更久。
為什么后臺建立索引時間更久呢? 先看看前臺建索引的大致流程,在整個流程中,一直持有 db 的寫鎖,禁止讀寫操作, 直到索引建立完成。
\1) 掃描整個數據文件,按照用戶所要求的字段以及 recordid 生成 keystring; \2) 將以上生成的 keystring 暫時存到內存中, 如果所占用的內存大小達到了 500MB 或者,就排序后落盤存放在臨時文件,如果數據量比較大,磁盤上會有多個 500MB 的文件,文件內 keystring 時有序的; \3) 對以上文件進行歸并,將結果批量寫到索引 b 樹中(索引文件底層也是一顆 b 樹)。
從以上來看前臺建立索引會將數據在文件排好序, 然后批量寫入到索引 b 樹中, 要比后臺索引隨機寫入索引 b 樹性能要更高。 為什么后臺建立索引過程中允許寫入還能保證索引數據的一致性呢? 后臺建索引的是直接掃描整個數據文件,期間允許讀寫操作, 按照用戶所要求的字段以及 recordid 生成 keystring, 然后插入到索引 b 樹中,并且用戶的更新/插入/刪除操作也會對索引 b 樹進行修改。 如何保證一遍全表掃,一邊更新/插入/刪除操作,保證最終數據和索引的一致性呢?可以分成三種情況:
- 情形 1:更新/插入/刪除還沒掃到的數據;情形 2:更新/插入/刪除已經掃到的數據;情形 3: 更新/插入/刪除和掃數據同時發生。
- 對情形 1, 如后續掃到插入時,會產生 DuplicateKey 錯誤,直接忽略;對于情形 2, 如更新/刪除操作,會將之前的建立的索引刪除;
- 情形 3比較難處理,需要依賴 wt 底層的事務寫重入機制
MongoDB引擎層使用樂觀鎖的機制, 多個事務對同一條文檔進行操作時, 其他事務感知到文檔被修改后,就拋出寫沖突異常,MongoDB捕獲的,拋棄當前的引擎層事務, 會重新開啟事務.如用戶一次 update 操作將{a:1}更新為{a:2},對應索引 b 樹的操作為 remove 了{a:1},然后 insert 一條 a=2 的數據, 后臺建索引線程掃描時 剛好掃到了{a:1},也會在索引 b 樹 insert 一條{a:1} 的數據,預期的最后結果是索引了只剩{a:2}, 以上的操作都在各自的 wt 事務內完成。
雖然是同時操作的,但還是有先后順序:
- 后臺建索引線程掃描后先插入了{a:1}, 但是還沒有提交, 等到用戶操作需要 remove 掉{a:1},就會觸發 wt 內部的寫沖突后,等待后臺建索引線程對應的事務提交后,再來重試,重試時會將 a=1 這條 remove 掉,然后 insert 一條 a=2 的數據, 最終結果就是一條{a:2}.
- 用戶先 update 操作后未提交, remove 了{a:1}時通過, 因為索引 b 樹不存在 a=1 這條文檔, 然后插入{a:2}, 等后臺建索引線程掃描后會插入了{a:1}成功, 觸發不了寫沖突的邏輯, 最終會剩下{a:2}以及{a:1}倆條數據,這時就會出現數據不一致的情況.
對于上述問題,其實官方早期版本中也存在, 如何進行修復呢? 其實在 remove 掉{a:1}之前, 可以先插入{a:1}, 在引擎中留下{a:1}被修改的記錄, 等后臺建索引線程掃描后會插入了{a:1}時, 就能救出寫沖突, 拋棄當前的引擎層事務, 等用戶 update 操作對應的 wt 事務提交后, 再重試時就無法掃描到{a:1}這條數據了, 最后只剩下{a:2}.
3.hybrid 建索引
那么是否有方法能夠結合以上倆者的優點呢?速度又快,又不會影響客戶端的操作。 從 4.2 開始,默認使用了第三種方式:hybrid 建索引
建索引的過程中,如前臺建立索引一樣, 也會掃描全表, 然后生成多個內部數據有序的臨時文件,然后歸并排序好批量插入到索引 b 樹中,怎么處理在上述過程中的的 更新/插入/刪除操作呢?hybrid 建索引會將上述變更記錄下來,然后等批量寫入階段結束后進行回放,為了保證數據的一致性,最終會在臨界區再回放一次回放過程中產生的變更,臨界區禁止用戶寫入。 所以 hybrid 建索引即擁有前臺建索引的速度又如后臺建索引不會卡住用戶的操作。
所以 4.0 及以下集群需要使用后臺建立索引需要指定{background:1}, hybrid 建索引在 4.2 是默認開啟的,用戶不需要關心.
五、索引查詢過程
1.IXSCAN 和 FETCH 階段
在使用索引查詢數據時, MongoDB 也使用火山模型, 其實比較常見的倆個階段 IXSCAN 和 FETCH。 IXSCAN 通過掃描索引 b 樹,返回 RecordId; FETCH 得到 RecordId 后從數據 b 樹取出對應的 BSON 文檔,直接提交給上層, 也有可能根據查詢條件的不同,進行過濾后再提交給上層算子。
以用戶使用較多的等值查詢, 范圍查詢(和gt(e)等操作符)為例來介紹 MongoDB 是如何通過索引遍歷數據來查詢的。
2.操作符 以及gt(e)注意點
在此之前看在無索引的情況下使用以及 gt(e)等操作符的注意點。mongo 只會比較相同的類型。如下所示, 表內有倆條數據
restore-test_0:PRIMARY> db.collb.find()
{ "_id" : ObjectId("647f204a2b531acaacf4afbe"), "a" : true }
{ "_id" : ObjectId("647f204d2b531acaacf4afbf"), "a" : 1 }執行以下查詢語句時, 只能找到 a 字段為數字類型的那條
restore-test_0:PRIMARY> db.collb.find({a:{$gte:1}})
{ "_id" : ObjectId("647f204d2b531acaacf4afbf"), "a" : 1 }
restore-test_0:PRIMARY> db.collb.find({a:{$lte:1}})
{ "_id" : ObjectId("647f204d2b531acaacf4afbf"), "a" : 1 }如果業務的字段具有不同類型的值,需要注意這點
3.遍歷之前-區間轉換
MongoDB 會將用戶的查詢語句轉化為區間查詢。 對于等值查詢會將其轉化為 start 和 end 相等的左開右開區間, 比如{a:1}, 那么對應的區間為[1.0, 1.0]。 對于范圍查詢如{a:{$gte:1}},就將其轉換為[1.0, inf.0], 這里的inf.0表示無窮大的正數, 為什么不是MaxKey呢?,按上面的說明可以理解為MaxKey為無窮大,比任意值都要大。前面說過在無索引遍歷的情況下,使用操作符 以及gt(e) 只會比較同類型的數據,同樣的索引會選擇該類型的最大值作為終止條件。比如對于bool類型來說{a:{$gte:false}}就會轉換成[false, true]這個區間。
但是對于一些無最大值的類型,比如 string 類型,{a:{$gte: "1" }}查詢條件如何轉換成區間呢? 既然 keystring 可以在不同類型間比較, 那么我們只要取下個類型的最小值即可, 即對應的區間為["1", {}), {}表示 Object 類型,在類型順序中屬于 string 類型的下個類型。
所以雖然轉換成 keystring 后,能夠實現不同類型的比較, 但是在實際使用范圍操作符遍歷索引時, MongoDB 內部也會自動加上限制條件,保證只能取同類型數據。下面看下具體如何轉換成對應的 KeyString 以及根據轉換后的區間遍歷過程。
(1) 遍歷之前-區間 keyString 轉換
上文中提到如{a:1}在作為普通索引在存儲時, 會轉換成以下格式:
key: ks(1) + kEnd + RecordId
value: typeBits那么對應的區間[1.0, inf.0]是如何轉換的呢? 首先并不知道 RecordId 對應多少, 那么就不能通過 wt 引擎的等值查詢 search 接口直接查到對應的文檔,需要使用 wt 引擎的 search_near 接口定位到第一條大于等于查詢 key 的接口, 對應的查詢 key 為:
key: ks(1) + kEnd如果是左邊是開區間的(1.0, inf.0]區間呢?這個時候如何還是使用 key: ks(1) + kEnd 作為查詢 key, 有可能查到多的數據, 如果需要 MongoDB 上層再過濾下,不是一個很好的選擇。最好的是在編碼的時候搞定, MongoDB 實際才使用時在 ks(1) + kEnd 中間添加一個標記為 kExclusiveAfter, kExclusiveAfter 標識位的值位 254, 查詢 key 為:
key: ks(1) + kExclusiveAfte + kEnd這樣使用引擎的 search_near 接口(大于等于語義)時,就能跳過{a:1}的數據。 區間的開始和結束都轉換成 KeyString 后,并不是直接將開始和結束點的 KeyString 都傳給 wt 引擎,而是只傳開始的 key,然后 wt 引擎開始遍歷,同時 MongoDB 上層對所遍歷的 key 進行判斷是否在區間內。
查詢區間根據所命中的數據在索引 b 樹上是否連續可以分為單區間和多區間, 根據查詢區間的不同, MongoDB 上層判斷是否在區間的方式也不一樣。
(2) 單區間查詢遍歷
如果是單區間比如以{a:1, b:1, c:1}為索引, 指定了等值查詢如{a:10} 或者{a:10, b:20}等等, 或者單個范圍{a: {$lte:10}} 或者{a:10, b: {$lte:10}}等前綴全是等值判斷只有最后一項為范圍的查詢方式,單區間所命中的數據在索引 b 樹上是連續的,就能根據區間結束條件生成 KeyString,在遍歷過程中由 MongoDB 上層來進行 KeyString 二進制對比, 如果對比發現超范圍了,就結束遍歷。
單區間遍歷比較直觀,也比較好理解。如果業務查詢條件比較復雜,非單區間遍歷,那么 MongoDB 是怎么遍歷的呢?
(3) 多區間查詢遍歷
如{a:{$in:[10, 20, 30]}) 以及使用了{a:1, b:1, c:1},查詢時按照{a:10 , c:{$lte:10}}等等相對較復雜的方式,所命中的數據在索引 b 樹上不是連續的,MongoDB 就不是通過 KeyString 來判斷, 而是每查詢一條,都得根據 KeyString 反解生成對應的 BSON 文檔, 然后再進行 BSON 比較判斷是否在目標區間內, 否則就需要重定位到下一個區間, 當然如果已經在最后一個區間了, 就結束遍歷。
下面用一個常見場景來分析下,假設有以下的數據集, 然后索引為{a:1, b:1, c:1}
數據集:
{a:1, b:1, c:1}
{a:1, b:1, c:2}
{a:1, b:1, c:3}
{a:1, b:1, c:4}
{a:1, b:2, c:5}
{a:1, b:2, c:1}
{a:1, b:2, c:2}
{a:1, b:2, c:3}
{a:1, b:2, c:4}
{a:1, b:2, c:5}對于該語句 db.collection.find({a:"1", c:{$lte:1}}).sort({b:1, c:1})必定走索引遍歷,不會有內存排序,但是索引數據在 b 樹上也不是連續分布的,那么現在的問題是遍歷過程中, 是否會將這十條數據全部遍歷呢?
在遍歷前通過分析,會確定 a、b 和 c 的取值范圍, b 沒有指定范圍,所以時 MinKey 到 MaxKey, c 指定了是比較數字,所以左區間為-inf.0。
"a" : [ "[1.0, 1.0]" ],
"b" : [ "[MinKey, MaxKey]" ],
"c" : [ "[-inf.0, 1.0]" ]按上面的分析,這是一個多區間查詢,遍歷過程中會發生重定位的行為, 我們詳細來看下遍歷的過程: 1) 跳轉(seek)到第一條大于等于 {a:1.0, b:MinKey, c:-inf.0}的數據, 即第一條數據, 判斷在范圍內, 滿足要求; 2) 遍歷到第二條數據時, 發現 c 字段不在范圍內, 不滿足要求, 這里會觸發跳轉的邏輯,不會再判斷第三條, 3) 既然當前 a 和 b 是在范圍內,跳轉的邏輯時找到大于{a:1, b:1}的第一條即可,即跳轉到{a:1, b:2, c:1},滿足要求 4) 然后重復上述的邏輯,判斷{a:1, b:2, c:3}不符合要求后,需要查找大于{a:1, b:2}的數據, 就直接跳轉到最后. 以上查詢過程會跳轉(seek)三次, 并不會掃描全部索引數據,而是掃描到了 4 條索引數據(keysExamined=4),最后判斷有倆條數據時滿足要求的。
所以 MongoDB 針對多區間查詢的場景, 為了提交查詢效率, 中間會穿插跳轉(seek)的情況,減少遍歷的 key 值。 但是以上述查詢為例, **跳轉(seek)的次數跟 b 字段的值范圍多少有關, 在滿足該種查詢的情況下, 建議 b 字段的值是枚舉類型,值空間是固定,避免出現較多的跳轉(seek)**。并且從以上流程可以看到單區間遍歷是通過 KeyString 二進制比較來判斷終止查詢是否終止, 而多區間查詢為了能夠實現跳轉(seek),每次比較需要把 KeyString 反解成 BSON 文檔來比較, 效率比 KeyString 二進制略低。
六、使用建議
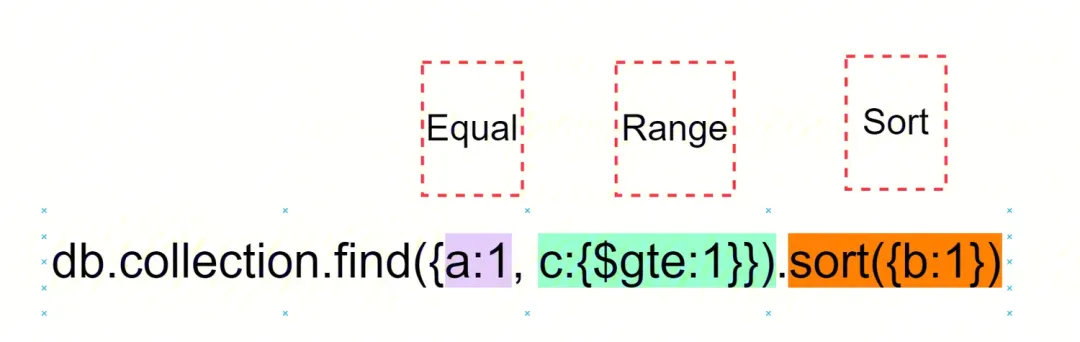
1.遵從 ESR 原則
對于復合索引,此經驗法則有助于確定索引中字段的順序: 首先,添加運行 等值 查詢的那些字段, 下一個要索引的字段應該反映查詢的排序順序, 最后的字段表示要訪問的數據范圍。 如{a:1, b:1, c:1} 索引, 按照以上原則設計, 在查詢時,就能按索引遍歷數據, 避免內存 sort 流程。
2.執行計劃確認
explain 是 MongoDB 的查詢計劃工具,和 MySql 的 explain 功能相同,都是用來分析一條語句的索引使用情況、影響行數、執行時間等。 explain 有三種參數分別對應結果輸出的三部分數據:
- queryPlanner: MongoDB 運行查詢優化器對當前的查詢進行評估并選擇一個最佳的查詢計劃。
- exectionStats:mongoDB 運行查詢優化器對當前的查詢進行評估并選擇一個最佳的查詢計劃進行執行。在執行完畢后返回這個最佳執行計劃執行完成時的相關統計信息。
- allPlansExecution:即按照最佳的執行計劃執行以及列出統計信息,如果有多個查詢計劃,還會列出這些非最佳執行計劃部分的統計信息。
建議在一個數據量較大的庫上開發功能時,使用 explain 分析一下自己的語句和索引是否合理,避免在項目上線之后出現問題。MongoDB 也是采用火山模型來進行查找, 火山模型是數據庫界已經很成熟的解釋計算模型,該計算模型將關系代數中每一種操作抽象為一個 Operator,將整個 SQL 構建成一個 Operator 樹,從根節點到葉子結點自上而下地遞歸調用 next() 函數。
常用 stage 解析:
- COLLSCAN:全表掃, 該階段會掃描表的全部數據,從數據 b-tree 開始掃描,應當避免該 stage 的出現;
- IXSCAN:根據分析 sql 生成的索引范圍來掃描索引 b-tree,在該 stage 中, 應關注掃描的條數是否合理;
- SORT_KEY_GENERATOR: 根據需要排序的字段生成 keystring,一般與 SORT stage 一起出現;
- SORT: 內存排序階段,占用內存,應當設計合適的索引來避免該階段;
- FETCH:回表操作,獲取到 RecordId 后,在數據 b-tree 中查找對應的文檔;
- PROJECTION: 選擇需要返回給的字段。
3.避免回表
通俗的講就是,如果索引的列在所需獲得的列中(因為索引是根據索引列的值進行排序的,所以索引節點中存在該列中的部分值)或者根據一次索引查詢就能獲得記錄就不需要回表,mongo 默認的查詢過程中, 在索引 b 樹上找到對應的 RecorId 上, 還需在數據 b 樹找對應的文檔,然后進行 bson 解析。 實際上如果用戶所需要的信息在索引 b 樹的 key 內已經包括了,后面的回表操作是多余的,尤其是在大文檔的條件下, BSON 解析比較消耗性能。
那么 MongoDB 如何去避免回表呢?
我們可以在 MongoDB 中可以通過使用 project 來選擇需要返回的字段,保證所需字段在 project 條件內,特別注意 MongoDB 默認_id 字段是需要返回的,如果確定不需要_id 字段,需要顯式的指定_id 為 0,可以通過判斷 explain 內是否包括 FETCH 階段來判斷是否發生了回表行為。 以某業務 cpu 使用率為例:
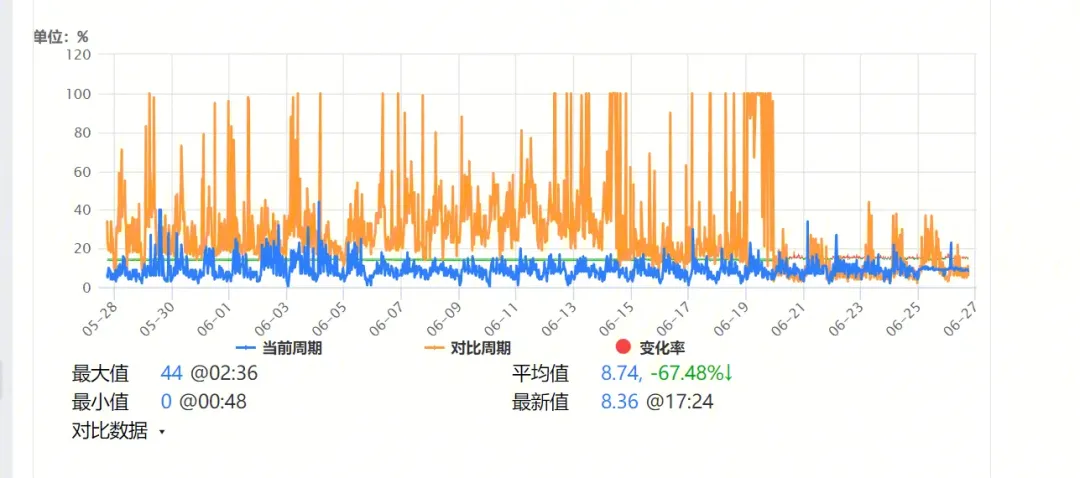
該業務每條文檔都比較大, 業務實際在使用的過程中指定 project 優化后, cpu 性能提升比較明顯。
4.減少索引的使用
在線上的業務中,發現有很多業務存儲使用多余索引的情況,
同個表有相同前綴的索引: 比如{a:1, b:1, c:1} 和 {a:1, b:1} 索引,在這種情況對寫入性能會有影響, 每次插入/修改/刪除都不可避免的對多余的索引進行操作,這種情況應當及時清理多余的索引;
如果業務剛好需要建立一個唯一索引,那么可以考慮使用_id 索引,從上面的分析可知,_id 索引可認為是一個 MongoDB 默認系統自帶的索引, 如果用好, 就能減少一個索引。
5.徹底了解 multiKey
所謂 multikey 是指如果一個字段的值是數組,那么為該字段創建索引時為數組中的每個元素創建一個索引鍵,這些多鍵索引支持對數組字段的有效查詢。 比如文檔{_id:0, a:[1, 2, 3]},對應的 RecordId 為 0 , 對 a 字段建立索引時, 在索引 b 樹上會插入三條數據,它們的 key 為:
ks(1) + RecordId(0)
ks(2) + RecordId(0)
ks(3) + RecordId(0)用戶通過{a:1}, {a:2} 以及{a:3}等查詢時,都能通過索引找到 recordId 為 0 ,然后找到數據, 這種查詢方式比較符合用戶的使用習慣。 當然能范圍查詢如{a:{$lte:3}},也會走索引,但是這會帶來一個問題,在 IXSCAN 階段三條索引數據都滿足要求,那么 IXSCAN 階段是否會返回三條同樣的 RecordId, 接下來的 FETCH 階段是否查詢三次呢? 實際上對于 multiKey 索引在遍歷第一條索引數據時, MongoDB 就有有個 set記錄了已經遍歷了的 recordId, 當遍歷第二條 ks(2) + RecordId(0) 以及第三條數據時就可以判斷 RecordId(0) 這條 bson 文檔已經被遍歷過了,不需要將對應的 RecordId 提交給上層的 FETCH 階段了。
如果對{a:1}字段建唯一索引呢? 如果我們想繼續插入如 {a:[3, 4, 5]} 對應的 RecordId 為 0,是會失敗的,由于已經在索引 b 樹中插入了三條數據 ks(1) + RecordId(0) 、 ks(2) + RecordId(0)和 ks(3) + RecordId(0),新插入的 ks(3) + RecordId(1) 與 已插入的 ks(3) + RecordId(0)不同通過唯一性檢查,所以這里需要注意唯一 multiKey 索引,是要求數組內的值唯一, 而不是整個數組唯一。
再看下面一個例子,表中有個倆條文檔, 以{a:1}建索引:
{_id:0, a:[1, 4]} => RecorId(0)
{_id:1, a:[2, 3]} => RecorId(1)先對 a 字段進行排序查詢:
PRIMARY> db.collection.find().sort({a:1})
{ "_id" : 0, "a" : [ 1, 4 ] }
{ "_id" : 1, "a" : [ 2, 3 ] }然后逆序查詢輸出下:
PRIMARY> db.collection.find().sort({a:-1})
{ "_id" : 0, "a" : [ 1, 4 ] }
{ "_id" : 1, "a" : [ 2, 3 ] }居然順序和逆序查詢結果是一樣的!!!按照我們上述分析的可以仔細分析出來, 這個倆條文檔需要在索引 b 樹中生成 4 個 kv 對,他們的 k 如下:
ks(1) + Record(0)
ks(2) + Record(1)
ks(3) + Record(1)
ks(4) + Record(0)我們執行的查詢語句會走索引,所以不管是順序還是逆序都會先查詢到 RecordId 為 0 的那條。
6.空字段的索引
“我們的表很大,現在需要對一個不存在的字段建索引,速度會不會快很多?”,我們在線上的運營過程中遇到過以上疑問,因為建索引可以簡化成倆個步驟:掃表和往索引 b 樹插入數據。掃表是避免不了的,但是對應的字段為空,是不是就不會往索引 b 樹中插入數據了呢?
首先我們可以看下如果索引字段為空,對應的索引 b 樹中也沒有對應的記錄會有什么后果。用戶常使用 操作符來判斷字段是否存在,如果索引樹中也沒有對應的對的話,那么exists 操作符在查詢是就不能走索引了,只能通過全表掃描的方式,這樣的效率是不能接受的。
索引 b 樹中需要特殊標識下字段為空的情況, 實際上在建立索引時如果字段為空, 就會認為該字段的類型為特殊的 null 類型(前文中已經提到過),db.collection.find({a:{$exists:false}}),對應的查詢區間為[null, null]。所以對于開頭的問題,對一個不存在的字段建索引,速度并不會快。
可以通過稀疏索引(或者稱間隙索引)就是只包含有索引字段的文檔的條目,即使索引字段包含一個空值。也就是說間隙索引可以跳過那些索引鍵不存在的文檔。7.慢日志分析
{
"timestamp": "Thu Apr 2 07:51:50.985" ,
"severityLevel": "I"
"components": "COMMAND"
"namespace": "animal.MongoUser_58"
"operation": "find"
"command": { find: "MongoUser_58", filter: { $and: [ { lld: { $gte: 18351 } }, { fc: { $lt: 120 } }, { _id: { $nin: [1244093274 ] } }, { $or: [ { rc: { $exists: false } }, { rc: { $lte: 1835400100 } } ] }, { lv: { $gte: 69 } }, { lv: { $lte: 99 } }, { cc: { $in: [ 440512, 440513, 440514, 440500, 440515, 440511, 440523, 440507 ] } } ] }, limit: 30 } //具體的操作命令細節
"planSummary": "IXSCAN { lv: -1 }", // 命令執行計劃的簡要說明,當前使用了 lv 這個字段的索引。如果是全表掃描,則是COLLSCAN
"keysExamined": 20856, // 該項表明為了找出最終結果MongoDB搜索了索引中的多少個key
"docsExamined": 20856, // 該項表明為了找出最終結果MongoDB搜索了多少個文檔
"cursorExhausted": 1, // 該項表明本次查詢中游標耗盡的次數
"keyUpdates":0,
"writeConflicts":0, // 寫沖突發生的數量,例如update一個正在被別的update操作的文檔
"numYields":6801, //
"nreturned":0, //
"reslen":110, //
"locks": { // 在
Global: { acquireCount: { r: 13604 } },
Database: { acquireCount: { r: 6802 } },
Collection: { acquireCount: { r: 6802 } }
},
"protocol": "op_command",
"millis" : 69132, // 從 MongoDB 操作開始到結束耗費的時間,單位為ms
}與索引相關的重要字段:
- planSummary: 命令執行計劃的簡要說明,當前使用了 lv 這個字段的索引,如果是全表掃描,則是 COLLSCAN,則需要重點注意了,是否設計不合理;
- keysExamined: 該項表明為了找出最終結果 MongoDB 搜索了索引 b 樹中的多少個 key;
- docsExamined: , 該項表明為了找出最終結果 MongoDB 搜索了多少個文檔, 就是根據 RecordId 往數據 b 樹中查詢了多少次;
- nreturned: 該操作最終返回文檔的數量。