單服務(wù)器高性能模式:PPC與TPC
高性能是每位程序員的追求。無論我們設(shè)計系統(tǒng)還是編寫代碼,都渴望達(dá)到最佳性能。但實現(xiàn)高性能是極為復(fù)雜的,因為諸如磁盤、操作系統(tǒng)、CPU、內(nèi)存、緩存、網(wǎng)絡(luò)、編程語言和架構(gòu)等因素都可能影響系統(tǒng)性能。一個不當(dāng)?shù)?debug 日志,甚至可能將服務(wù)器的性能從每秒處理 30000 個事務(wù)降低到 8000 個;一個 tcp_nodelay 參數(shù)的設(shè)置,可能將響應(yīng)時間從 2 毫秒延長到 40 毫秒。因此,實現(xiàn)高性能是一項極具挑戰(zhàn)性的任務(wù)。軟件系統(tǒng)開發(fā)的不同階段都會對最終的性能產(chǎn)生影響。
站在架構(gòu)師的角度,特別關(guān)注高性能架構(gòu)的設(shè)計是至關(guān)重要的。高性能架構(gòu)設(shè)計主要集中在兩個方面:
- 盡量提升單個服務(wù)器的性能,將其性能發(fā)揮到極致。
- 如果單服務(wù)器無法滿足性能需求,則設(shè)計服務(wù)器集群方案。
除了上述兩點,系統(tǒng)最終能否實現(xiàn)高性能還與具體的實現(xiàn)和編碼有關(guān)。但架構(gòu)設(shè)計是實現(xiàn)高性能的基礎(chǔ)。如果架構(gòu)設(shè)計不能達(dá)到高性能要求,那么后續(xù)的實現(xiàn)和編碼優(yōu)化也只能在有限的空間內(nèi)發(fā)揮作用。可以形象地說,架構(gòu)設(shè)計決定了系統(tǒng)性能的上限,而實現(xiàn)細(xì)節(jié)則決定了系統(tǒng)性能的下限。
實現(xiàn)單服務(wù)器高性能的關(guān)鍵之一是選擇合適的并發(fā)模型。并發(fā)模型涉及以下兩個關(guān)鍵設(shè)計點:
- 服務(wù)器如何管理連接。
- 服務(wù)器如何處理請求。
這兩個設(shè)計點最終都與操作系統(tǒng)的 I/O 模型和進(jìn)程模型相關(guān)。常見的 I/O 模型包括阻塞、非阻塞、同步和異步;而進(jìn)程模型可以是單進(jìn)程、多進(jìn)程或多線程。
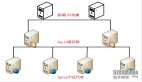
PPC
PPC,即 Process Per Connection,意味著每次有新連接時就會創(chuàng)建一個新的進(jìn)程來專門處理該連接的請求。這是傳統(tǒng) UNIX 網(wǎng)絡(luò)服務(wù)器常采用的模型。
 圖片
圖片
在這種模式下,父進(jìn)程負(fù)責(zé)接受連接,并在接受到連接后通過“fork”創(chuàng)建一個子進(jìn)程來處理連接的讀寫請求。子進(jìn)程處理完請求后關(guān)閉連接。需要注意的是,在“fork”創(chuàng)建子進(jìn)程后,父進(jìn)程直接調(diào)用 close,看起來好像是關(guān)閉了連接,但實際上只是減少了連接的文件描述符引用計數(shù)。真正的關(guān)閉連接是在子進(jìn)程調(diào)用 close 后,連接的文件描述符引用計數(shù)變?yōu)?0,操作系統(tǒng)才會真正關(guān)閉連接。
PPC 模式實現(xiàn)簡單,適用于連接數(shù)不多的情況,比如數(shù)據(jù)庫服務(wù)器。在互聯(lián)網(wǎng)興起之前,對于普通的業(yè)務(wù)服務(wù)器,由于訪問量和并發(fā)量相對較低,這種模式運作良好。世界上第一個 web 服務(wù)器 CERN httpd 就采用了這種模式。
然而,隨著互聯(lián)網(wǎng)的發(fā)展,服務(wù)器的并發(fā)和訪問量激增,PPC 模式的弊端也顯現(xiàn)出來:
fork 代價高:創(chuàng)建一個進(jìn)程的代價很高,需要分配大量內(nèi)核資源,將內(nèi)存映像從父進(jìn)程復(fù)制到子進(jìn)程。即使現(xiàn)在的操作系統(tǒng)采用了 Copy on Write 技術(shù),總體上創(chuàng)建進(jìn)程的代價仍然較高。
父子進(jìn)程通信復(fù)雜:父進(jìn)程“fork”子進(jìn)程后,父子進(jìn)程之間通信復(fù)雜,需要采用 IPC 進(jìn)程通信方案。例如,子進(jìn)程需要在關(guān)閉連接之前告知父進(jìn)程處理了多少個請求,以支持父進(jìn)程進(jìn)行全局統(tǒng)計。
并發(fā)連接數(shù)量有限:如果每個連接存活時間較長且新連接不斷進(jìn)來,進(jìn)程數(shù)量會不斷增加,導(dǎo)致操作系統(tǒng)進(jìn)程調(diào)度和切換頻繁,系統(tǒng)壓力增大。因此,一般情況下,PPC 方案最多能處理的并發(fā)連接數(shù)量只有幾百個。
TPC
TPC,即 Thread Per Connection,意味著每次有新連接時都會創(chuàng)建一個新線程專門處理該連接的請求。相比進(jìn)程,線程更輕量級,創(chuàng)建線程的開銷更小;同時,線程共享進(jìn)程內(nèi)存空間,線程間通信相對簡單。因此,TPC 實際上是解決了或者減輕了 PPC 中 fork 代價高和父子進(jìn)程通信復(fù)雜的問題。
 圖片
圖片
在TPC模式下,父進(jìn)程負(fù)責(zé)接受連接,然后創(chuàng)建子線程來處理連接的讀寫請求,最后子線程關(guān)閉連接。與 PPC 不同的是,主進(jìn)程無需手動關(guān)閉連接,因為子線程共享主進(jìn)程的進(jìn)程空間,連接的文件描述符沒有被復(fù)制,只需一次 close 即可。
盡管TPC解決了 fork 代價高和進(jìn)程通信復(fù)雜的問題,但也帶來了新的挑戰(zhàn):
創(chuàng)建線程雖然比創(chuàng)建進(jìn)程代價低,但在高并發(fā)情況下(如每秒上萬連接),仍存在性能問題。
雖然無需進(jìn)程間通信,但線程間的互斥和共享帶來了復(fù)雜性,容易導(dǎo)致死鎖問題。
多線程會出現(xiàn)互相影響的情況,某個線程異常可能導(dǎo)致整個進(jìn)程退出(如內(nèi)存越界)。
除了引入新的問題,TPC 仍然面臨 CPU 線程調(diào)度和切換的代價。因此,在并發(fā)連接幾百個的場景下,更傾向于使用 PPC,因為它沒有死鎖風(fēng)險,也不會受多進(jìn)程相互影響,具有更高的穩(wěn)定性。
prethread
TPC模式中,只有在連接進(jìn)來時才創(chuàng)建新的線程來處理連接請求。盡管創(chuàng)建線程比創(chuàng)建進(jìn)程更輕量級,但仍然存在一定的代價。為了解決這個問題,出現(xiàn)了prethread模式。
 圖片
圖片
類似于prefork,prethread模式會預(yù)先創(chuàng)建線程,然后開始接受用戶請求。這樣,當(dāng)新連接進(jìn)來時,就無需再創(chuàng)建線程,從而提升用戶感知的速度和體驗。
由于多線程之間數(shù)據(jù)共享和通信更方便,prethread的實現(xiàn)方式比prefork更靈活。常見的實現(xiàn)方式包括:
主進(jìn)程accept連接,然后將連接交給某個線程處理。
多個子線程嘗試accept連接,只有一個線程accept成功。
Apache服務(wù)器的MPM worker模式本質(zhì)上就是一種prethread方案,但進(jìn)行了改進(jìn)。Apache首先創(chuàng)建多個進(jìn)程,每個進(jìn)程再創(chuàng)建多個線程。這樣做的主要考慮是為了提高穩(wěn)定性,即使某個子進(jìn)程的某個線程異常退出,仍會有其他子進(jìn)程繼續(xù)提供服務(wù),不會導(dǎo)致整個服務(wù)器崩潰。
prethread理論上可以支持比prefork更多的并發(fā)連接。例如,Apache服務(wù)器的MPM worker模式默認(rèn)支持400個并發(fā)處理線程(16個進(jìn)程 × 25個線程)。