Java中的String,這一篇就夠了
今天我們一起看一下Java基礎類:String
定義
- String表示字符串類型,屬于引用數據類型,不屬于基本數據類型。
- 在java中隨便使用 雙引號括起來 的都是String對象。例如:"abc","def","hello world!",這是3個String對象。
- java中規定,雙引號括起來的字符串,是 不可變 的,也就是說"abc"自出生到最終死亡,不可變,不能變成"abcd",也不能變成"ab"
源碼解讀
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/**用來存儲字符串 */
private final char value[];
/** 緩存字符串的哈希碼 */
private int hash; // Default to 0
/** 實現序列化的標識 */
private static final long serialVersionUID = -6849794470754667710L;
}這是一個用 final 聲明的常量類,不能被任何類所繼承,而且一旦一個String對象被創建, 包含在這個對象中的字符序列是不可改變的, 包括該類后續的所有方法都是不能修改該對象的,直至該對象被銷毀,這是我們需要特別注意的(該類的一些方法看似改變了字符串,其實內部都是創建一個新的字符串,下面講解方法時會介紹)。
通過上述代碼可以發現,一個 String 字符串實際上是一個 char 數組。
聲明方式
//注意這種字面量聲明的區別
String str1 = "abc";
String str2 = new String("abc");JDK1.6
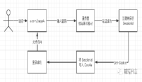
那么這兩種聲明方式有什么區別呢?在講解之前,我們先介紹 JDK1.7(不包括1.7)以前的 JVM 的內存分布:
 圖片
圖片
- 程序計數器:也稱為 PC 寄存器,保存的是程序當前執行的指令的地址(也可以說保存下一條指令的所在存儲單元的地址),當CPU需要執行指令時,需要從程序計數器中得到當前需要執行的指令所在存儲單元的地址,然后根據得到的地址獲取到指令,在得到指令之后,程序計數器便自動加1或者根據轉移指針得到下一條指令的地址,如此循環,直至執行完所有的指令。線程私有。
- 虛擬機棧:基本數據類型、對象的引用都存放在這。線程私有。
- 本地方法棧:虛擬機棧是為執行Java方法服務的,而本地方法棧則是為執行本地方法(Native Method)服務的。在JVM規范中,并沒有對本地方法棧的具體實現方法以及數據結構作強制規定,虛擬機可以自由實現它。在HotSopt虛擬機中直接就把本地方法棧和虛擬機棧合二為一。
- 方法區:存儲了每個類的信息(包括類的名稱、方法信息、字段信息)、靜態變量、常量以及編譯器編譯后的代碼等。注意:在Class文件中除了類的字段、方法、接口等描述信息外,還有一項信息是常量池,用來存儲編譯期間生成的字面量和符號引用。
- 堆:用來存儲對象本身的以及數組(當然,數組引用是存放在Java棧中的)。
JDK1.7及以后
在 JDK1.7 以后,方法區的常量池被移除放到堆中了,如下:
 圖片
圖片
常量池:Java運行時會維護一個String Pool(String池), 也叫“字符串緩沖區”。String池用來存放運行時中產生的各種字符串,并且池中的字符串的內容不重復。
- 字面量創建字符串或者純字符串(常量)拼接字符串會先在字符串池中找,看是否有相等的對象,沒有的話就在字符串池創建該對象;有的話則直接用池中的引用,避免重復創建對象。
- new關鍵字創建時,直接在堆中創建一個新對象,變量所引用的都是這個新對象的地址,但是如果通過new關鍵字創建的字符串內容在常量池中存在了,那么會由堆在指向常量池的對應字符;但是反過來,如果通過new關鍵字創建的字符串對象在常量池中沒有,那么通過new關鍵詞創建的字符串對象是不會額外在常量池中維護的。
- 使用包含變量表達式來創建String對象,則不僅會檢查維護字符串池,還會在堆區創建這個對象,最后是指向堆內存的對象。
內存分析
1. String str = "Hello";
public class stringclass {
public static void main(String[] args) {
String str="Hello";
String str2="Hello";
System.out.println(str==str2);
str="World";
}
}
//輸出結果:true 圖片
圖片
2. String str = new String ("Hello");
public class stringclass {
public static void main(String[] args) {
String str= new String("Hello");
String str2= new String("Hello");
String str3 = "Hello";
System.out.println(str==str2);
System.out.println(str==str3);
}
}
//輸出結果:false false3. String str = "Hello" + "World";
public class stringclass {
public static void main(String[] args) {
//當一個字符串由多個字符串常量連接而成時,它自己肯定也是字符串常量。
//該字符串是在編譯期就能確定。先是在池里生成“a”和“b”,再通過拼接的方式在池里生成"ab"。
String str="Hello" + "World";
}
} 圖片
圖片
4. String str = new String ("Hello") + new String("World");
當使用了變量字符串的拼接(+, sb.append)都只會在堆區創建該字符串對象, 并不會在常量池創建新生成的字符串
public class stringclass {
public static void main(String[] args) {
String str=new String("Hello") + new String("World");
}
} 圖片
圖片
常見操作
1. equals(Object anObject)
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}String 類重寫了 equals 方法,比較的是組成字符串的每一個字符是否相同,如果都相同則返回true,否則返回false。
2. hashCode()
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}String 類的 hashCode 算法很簡單,主要就是中間的 for 循環,計算公式如下:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
s 數組即源碼中的 val 數組,也就是構成字符串的字符數組。這里有個數字 31 ,為什么選擇31作為乘積因子,而且沒有用一個常量來聲明?主要原因有兩個:
- 31是一個不大不小的質數,是作為 hashCode 乘子的優選質數之一。
- 31可以被 JVM 優化,31 * i = (i << 5) - i。因為移位運算比乘法運行更快更省性能。
3. charAt(int index)
public char charAt(int index) {
//如果傳入的索引大于字符串的長度或者小于0,直接拋出索引越界異常
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];//返回指定索引的單個字符
}我們知道一個字符串是由一個字符數組組成,這個方法是通過傳入的索引(數組下標),返回指定索引的單個字符。
4. compareTo(String anotherString)
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}源碼也很好理解,該方法是按字母順序比較兩個字符串,是基于字符串中每個字符的 Unicode 值。當兩個字符串某個位置的字符不同時,返回的是這一位置的字符 Unicode 值之差,當兩個字符串都相同時,返回兩個字符串長度之差。
compareToIgnoreCase() 方法在 compareTo 方法的基礎上忽略大小寫,我們知道大寫字母是比小寫字母的Unicode值小32的,底層實現是先都轉換成大寫比較,然后都轉換成小寫進行比較。
5. concat(String str)
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}該方法是將指定的字符串連接到此字符串的末尾。
首先判斷要拼接的字符串長度是否為0,如果為0,則直接返回原字符串。如果不為0,則通過 Arrays 工具類的copyOf方法創建一個新的字符數組,長度為原字符串和要拼接的字符串之和,前面填充原字符串,后面為空。接著在通過 getChars 方法將要拼接的字符串放入新字符串后面為空的位置。
注意:返回值是 new String(buf, true),也就是重新通過 new 關鍵字創建了一個新的字符串,原字符串是不變的。這也是前面我們說的一旦一個String對象被創建, 包含在這個對象中的字符序列是不可改變的。
6. indexOf(int ch)
public int indexOf(int ch) {
return indexOf(ch, 0);//從第一個字符開始搜索
}
public int indexOf(int ch, int fromIndex) {
final int max = value.length;//max等于字符的長度
if (fromIndex < 0) {//指定索引的位置如果小于0,默認從 0 開始搜索
fromIndex = 0;
} else if (fromIndex >= max) {
//如果指定索引值大于等于字符的長度(因為是數組,下標最多只能是max-1),直接返回-1
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {//一個char占用兩個字節,如果ch小于2的16次方(65536),絕大多數字符都在此范圍內
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {//for循環依次判斷字符串每個字符是否和指定字符相等
if (value[i] == ch) {
return i;//存在相等的字符,返回第一次出現該字符的索引位置,并終止循環
}
}
return -1;//不存在相等的字符,則返回 -1
}else {//當字符大于 65536時,處理的少數情況,該方法會首先判斷是否是有效字符,然后依次進行比較
return indexOfSupplementary(ch, fromIndex);
}
}indexOf(int ch),參數 ch 其實是字符的 Unicode 值,這里也可以放單個字符(默認轉成int),作用是返回指定字符第一次出現的此字符串中的索引。其內部是調用 indexOf(int ch, int fromIndex),只不過這里的 fromIndex =0 ,因為是從 0 開始搜索;而 indexOf(int ch, int fromIndex) 作用也是返回首次出現的此字符串內的索引,但是從指定索引處開始搜索。
7. substring(int beginIndex)
public String substring(int beginIndex) {
if (beginIndex < 0) {//如果索引小于0,直接拋出異常
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;//subLen等于字符串長度減去索引
if (subLen < 0) {//如果subLen小于0,也是直接拋出異常
throw new StringIndexOutOfBoundsException(subLen);
}
//1、如果索引值beginIdex == 0,直接返回原字符串
//2、如果不等于0,則返回從beginIndex開始,一直到結尾
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}返回一個從索引 beginIndex 開始一直到結尾的子字符串。
String不可變性
String 類為什么要這樣設計成不可變呢?我們可以從性能以及安全方面來考慮:
- 安全
引發安全問題,譬如,數據庫的用戶名、密碼都是以字符串的形式傳入來獲得數據庫的連接,或者在socket編程中,主機名和端口都是以字符串的形式傳入。因為字符串是不可變的,所以它的值是不可改變的,否則黑客們可以鉆到空子,改變字符串指向的對象的值,造成安全漏洞。
保證線程安全,在并發場景下,多個線程同時讀寫資源時,會引競態條件,由于 String 是不可變的,不會引發線程的問題而保證了線程。
HashCode,當 String 被創建出來的時候,hashcode也會隨之被緩存,hashcode的計算與value有關,若 String 可變,那么 hashcode 也會隨之變化,針對于 Map、Set 等容器,他們的鍵值需要保證唯一性和一致性,因此,String 的不可變性使其比其他對象更適合當容器的鍵值。
- 性能
- 當字符串是不可變時,字符串常量池才有意義。字符串常量池的出現,可以減少創建相同字面量的字符串,讓不同的引用指向池中同一個字符串,為運行時節約很多的堆內存。若字符串可變,字符串常量池失去意義,基于常量池的String.intern()方法也失效,每次創建新的 String 將在堆內開辟出新的空間,占據更多的內存。