PostgreSQL索引優化:加速查詢性能的利器!

當涉及到處理大量數據的查詢時,使用索引是提高 PostgreSQL 查詢性能的關鍵因素之一。索引是一種數據結構,它可以幫助數據庫系統快速定位和訪問特定數據,而不必掃描整個表。
讓我們從頭開始學習如何使用索引來加快查詢性能。首先,我們需要了解如何創建索引。
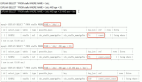
創建索引 在 PostgreSQL 中,可以使用 CREATE INDEX 語句來創建索引。以下是創建索引的基本語法:
CREATE INDEX index_name ON table_name (column_name);其中,index_name 是索引的名稱,table_name 是要創建索引的表名,column_name 是要在該列上創建索引的列名。
現在,讓我們通過一個具體的示例來說明如何創建索引。假設我們有一個名為 employees 的表,其中包含 id、name 和 salary 列。
CREATE INDEX idx_employees_name ON employees (name);上面的語句將在 employees 表的 name 列上創建一個名為 idx_employees_name 的索引。
選擇正確的列創建索引 選擇正確的列來創建索引非常重要。通常,我們應該選擇那些經常在查詢條件中使用的列。例如,在經常使用 WHERE 子句中的列上創建索引可以提高查詢性能。
讓我們考慮以下示例。假設我們有一個名為 orders 的表,其中包含 order_id、customer_id 和 order_date 列。我們經常根據 customer_id 進行查詢。
CREATE INDEX idx_orders_customer_id ON orders (customer_id);上面的語句將在 orders 表的 customer_id 列上創建一個名為 idx_orders_customer_id 的索引。
考慮索引選擇性 索引的選擇性是指索引中不同值的數量與表中總行數之間的比率。選擇性較高的索引將更有效地過濾數據,從而提高查詢性能。
考慮以下示例,假設我們有一個名為 products 的表,其中包含 product_id、category_id 和 price 列。我們經常根據 category_id 列進行查詢。
CREATE INDEX idx_products_category_id ON products (category_id);上面的語句將在 products 表的 category_id 列上創建一個名為 idx_products_category_id 的索引。
避免過多索引 雖然索引可以提高查詢性能,但過多的索引可能會導致性能下降。每個索引都需要占用存儲空間,并在插入、更新和刪除操作時需要維護。因此,僅在需要時創建索引,并確保它們對查詢有實際的影響。
考慮以下示例,假設我們有一個名為 customers 的表,其中包含 customer_id、name 和 email 列。我們經常根據 email 列進行查詢。
CREATE INDEX idx_customers_email ON customers (email);上面的語句將在 customers 表的 email 列上創建一個名為 idx_customers_email 的索引。請注意,如果我們不經常根據 name 列進行查詢,那么在該列上創建索引可能并不是必需的。
這是關于使用索引來加快查詢性能的一些基本原則和示例。要成為 PostgreSQL 的專家,你需要深入了解索引的各種類型、索引的使用場景以及其他高級索引優化技術。但是,這個指南會為你提供一個良好的起點,讓你在理解和使用索引方面更加熟練。