













面試官:聽說你很懂線程池?
什么是線程池
就是一種池化技術,類似的還有jdbc連接池,對象池。所謂線程池,就是提前創建一堆線程,放到內存(池子)中,需要的時候取一個出來用。
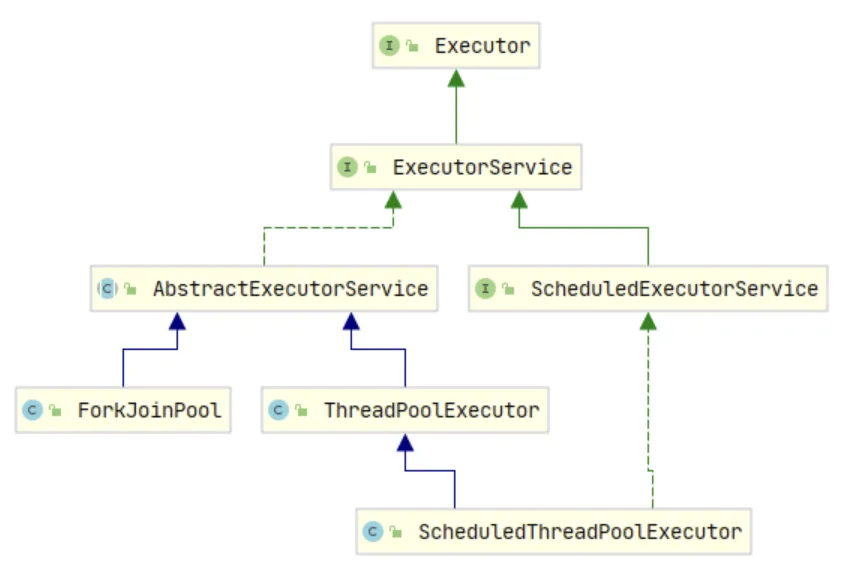
如上圖,最頂層的接口就是Executor,實現ExecutorService接口的類,就是對應的線程池類。
如何創建線程池
用Executors工具類,可以很方便地創建各種線程池。(但是實際開發我們不推薦,阿里巴巴的開發手冊嚴令禁止使用Executors,應該用ThreadPoolExecutor)Executors 類可以創建多種類型的線程池,每種線程池都有不同的特點和適用場景。
(1) FixedThreadPool(固定大小線程池):
- 使用 Executors.newFixedThreadPool(int nThreads) 方法創建。
- 具有固定大小的線程池,即線程數量固定不變。
- 適用于需要控制線程數量的場景,例如服務器端處理請求。
(2) CachedThreadPool(緩存線程池):
- 使用 Executors.newCachedThreadPool() 方法創建。
- 具有自動調整線程數量的線程池,根據需要創建新線程,空閑線程會被回收。
- 適用于執行大量短期異步任務的場景,例如異步IO操作。
(3) SingleThreadPool(單線程線程池):
- 使用 Executors.newSingleThreadExecutor() 方法創建。
- 只有一個工作線程的線程池,所有任務按順序執行。
- 適用于需要保證順序執行的任務場景,例如日志處理。
(4) ScheduledThreadPool(定時任務線程池):
- 使用 Executors.newScheduledThreadPool(int corePoolSize) 方法創建。
- 具有定時執行任務的功能,可以按固定的頻率執行任務。
- 適用于需要定時執行任務的場景,例如定時任務調度。
(5) WorkStealingPool(工作竊取線程池):
- 使用 Executors.newWorkStealingPool(int parallelism) 方法創建。
- 基于ForkJoinPool實現的線程池,每個線程都有自己的任務隊列,可以竊取其他線程的任務來執行。
- 適用于需要處理大量并行任務的場景,例如并行計算任務。
為什么不推薦用Executors創建?

線程池底層原理
我們以ThreadPoolExecutor為例,它是ExecutorService的一種實現。
一般我們根據一個類的構造器,可以看出里面的大致思路:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}參數很多,但是我們每一個都必須要記住。 這個 ThreadPoolExecutor 的構造函數接受以下參數:一個線程池就好比一家公司,甲方員工干不完需求的時候,就要招一些外包人員駐場開發,如果活干完了,就讓外包撤場,只留下自己的員工。
- corePoolSize(核心線程數):線程池中保持活躍的線程數量,即使它們處于空閑狀態。當提交任務時,線程池會嘗試保持至少這么多數量的線程處于活躍狀態。 就是公司正式員工的數量。
- maximumPoolSize(最大線程數):線程池中允許的最大線程數量。當任務隊列已滿且核心線程都處于活躍狀態時,線程池會創建新的線程,直到達到這個最大線程數。 就是公司甲方員工+外包員工的總數,不能超過這個數量。
- keepAliveTime(線程空閑時間):非核心線程在空閑狀態下的最長存活時間。超過這個時間,多余的非核心線程將被終止,直到線程數量不超過核心線程數。 如果外包員工長時間沒需求,就通知乙方撤人,裁掉這個非核心人員。當然,甲方爸爸是不會裁的。
- unit(時間單位):用于指定 keepAliveTime 參數的時間單位,通常是秒、毫秒、微秒等。
- workQueue(工作隊列):用于保存等待執行的任務的阻塞隊列。當所有線程都處于忙碌狀態時,新提交的任務會被放入這個隊列中等待執行。 當需求多到加上外包員工都做不完了,就只能往后排期了。
- threadFactory(線程工廠):用于創建新線程的工廠。每個新創建的線程都是通過這個工廠創建的。** 就是定義員工的屬性,即工牌,這個員工屬于哪個公司的。**
- handler(拒絕策略):當任務無法被執行時(通常是由于線程池已關閉或者任務隊列已滿),用于處理被拒絕的任務的策略。常見的拒絕策略包括拋出異常、丟棄任務或者在調用者線程中執行任務。 默認是不處理。
這些參數可以用于配置 ThreadPoolExecutor 對象,以滿足不同的線程管理需求。
線程池本質就是一個HashSet,所以是無序的。有新的任務提交進來,如果池子還有線程,就直接拿去處理,池子滿了就放入阻塞隊列,等待有線程空閑。
線程數怎么設置比較合理?
這個是沒有銀彈的,我們一般認為CPU密集型的應用,設置為CPU核數N+1。所謂CPU密集型,就是這個程序計算量比較多,還比較頻繁,計算時間長,也就是所謂的比較吃配置,比如是一個專門做算法的服務(組托,配載運算之類的)。
對于IO密集型的應用,設置為2N+1,什么是IO密集型的應用呢,就是提供數據服務比較多,吞吐量比較大,等待時間長的應用,大部分業務系統都屬于此類。
除此之外,線程數還跟jvm,機器cpu是否可以超線程(云服務器一般沒法超線程),我們看到的cpu核數一般不是真實的,所以我們推薦先根據常規設置一個線程數量,上線后根據具體情況再調整就行了。





















