













全面綜述!大模型到底微調個啥?或者說技術含量到底有多大?
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
大型模型代表了多個應用領域的突破性進展,能夠在各種任務中取得顯著成就。然而,它們前所未有的規模帶來了巨大的計算成本。這些模型通常由數十億個參數組成,需要大量的計算資源才能執行。特別是,當為特定的下游任務定制它們時,特別是在受計算能力限制的硬件平臺上,擴展的規模和計算需求帶來了相當大的挑戰。
參數有效微調(PEFT)通過在各種下游任務中有效地調整大型模型,提供了一種實用的解決方案。特別是,PEFT是指調整預先訓練的大型模型的參數,使其適應特定任務或領域,同時最小化引入的額外參數或所需計算資源的數量的過程。當處理具有高參數計數的大型語言模型時,這種方法尤其重要,因為從頭開始微調這些模型可能計算成本高昂且資源密集,在支持系統平臺設計中提出了相當大的挑戰。
在這項調查中,我們對各種PEFT算法進行了全面的研究,檢查了它們的性能和計算開銷。此外,我們還概述了使用不同PEFT算法開發的應用程序,并討論了用于降低PEFT計算成本的常用技術。除了算法角度之外,我們還概述了各種現實世界中的系統設計,以研究與不同PEFT算法相關的實施成本。這項調查是研究人員了解PEFT算法及其系統實現的不可或缺的資源,為最新進展和實際應用提供了詳細的見解。
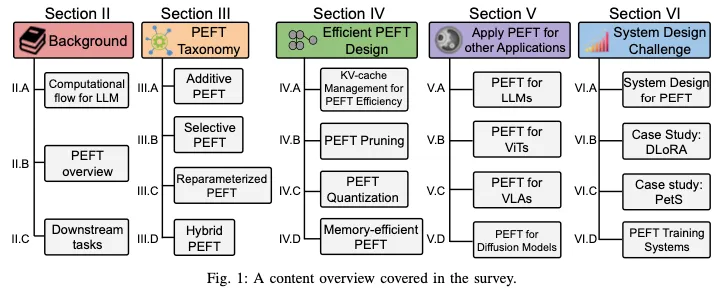
PEFT分類
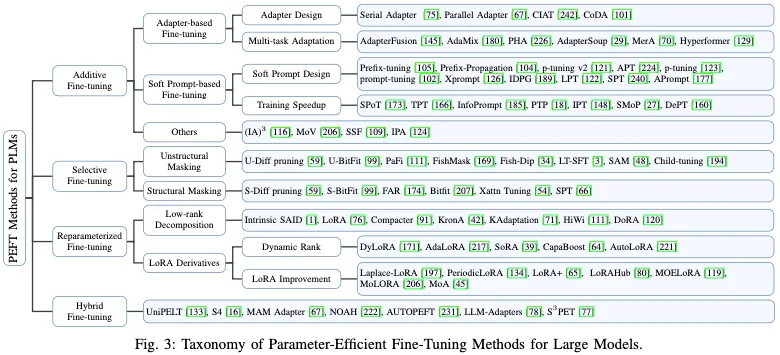
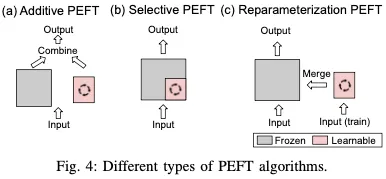
PEFT策略可大致分為四類:附加PEFT(第III-A節),通過注入新的可訓練模塊或參數來修改模型架構;選擇性PEFT(第III-B節),使參數子集在微調期間可訓練;重新參數化PEFT(第III-C節),它構建了用于訓練的原始模型參數的(低維)重新參數化,然后等效地將其轉換回用于推理;以及混合PEFT(第III-D節),它結合了不同PEFT方法的優勢,建立了統一的PEFT模型。不同類型的PEFT算法概述如圖4所示。
A. Additive PEFT
標準的完全微調需要大量的計算費用,也可能損害模型的泛化能力。為了緩解這個問題,一種廣泛采用的方法是保持預先訓練的主干不變,并且只引入在模型架構中戰略性定位的最小數量的可訓練參數。在針對特定下游任務進行微調時,僅更新這些附加模塊或參數的權重,這導致存儲、內存和計算資源需求的顯著減少。如圖4(a)所示,由于這些技術具有添加參數的特性,因此可以將其稱為加性調整。接下來,我們將討論幾種流行的加法PEFT算法。
1)適配器:適配器方法包括在Transformer塊中插入小型適配器層。
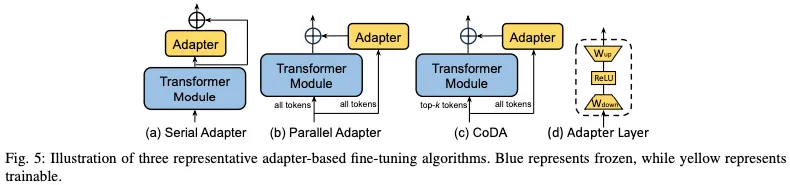
2)軟提示:提示調整提供了一種額外的方法來細化模型,以通過微調提高性能。
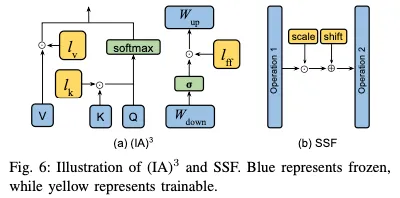
3)其他加法方法:除了上述方法外,還出現了其他方法,在微調過程中戰略性地加入了額外的參數。
B. Selective PEFT
如圖4(b)所示,選擇性PEFT不是通過添加更多參數來增加模型復雜性的附加PEFT,而是對現有參數的子集進行微調,以提高模型在下游任務中的性能。
差分修剪是在微調期間將可學習的二進制掩碼應用于模型權重的代表性工作。為了實現參數效率,通過L0范數懲罰的可微近似來正則化掩模。PaFi只需選擇具有最小絕對幅度的模型參數作為可訓練參數。
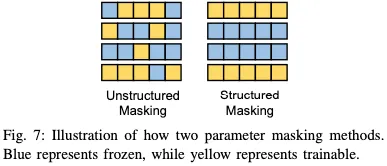
然而,當實現PEFT時,上述非結構化參數掩蔽導致非零掩蔽的不均勻分布和硬件效率的降低。如圖7所示,與隨機應用的非結構化掩碼不同,結構化掩碼以規則模式組織參數掩碼,因此可以提高訓練過程中的計算和硬件效率。因此,對各種結構選擇性PEFT技術進行了廣泛的研究。Diff修剪提出了一種結構化的修剪策略,將權重參數劃分為局部組,并戰略性地將它們一起消除。類似地,FAR通過將Transformer塊中的FFN的權重分組為節點來微調BERT模型,然后使用L1范數對學習器節點進行排序和選擇。為了進一步降低存儲器訪問頻率,他們還通過將學習器節點分組在一起來重新配置FFN。
C. Reparameterized PEFT
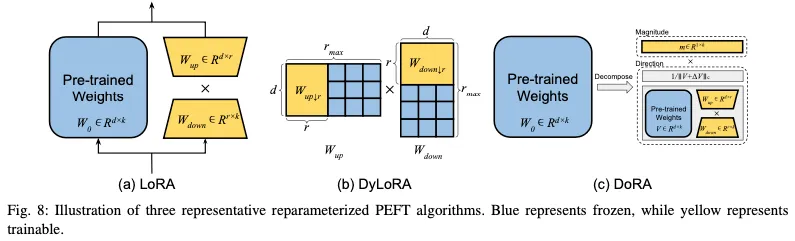
重新參數化表示通過轉換模型的參數將模型的體系結構從一個等效地轉換到另一個。在PEFT的背景下,這通常意味著在訓練過程中構建一個低階參數化來實現參數效率的目標。對于推理,可以將模型轉換為其原始的權重參數化,確保推理速度不變。該程序如圖4(c)所示。
早期的研究表明,常見的預訓練模型表現出異常低的內在維度。換言之,可以找到對整個參數空間的微調有效的低維重新參數化。內在SAID是研究LLM微調過程中內在維度特征的主要工作。然而,最廣泛認可的重新參數化技術是LoRA(低秩自適應),如圖8(a)所示。
D. Hybrid PEFT
各種PEFT方法的療效在不同的任務中可能存在顯著差異。因此,許多研究旨在結合不同PEFT方法的優勢,或通過分析這些方法之間的相似性來尋求建立統一的視角。例如,UniPELT將LoRA、前綴調整和適配器集成到每個Transformer塊中。為了控制應激活哪些PEFT子模塊,他們還引入了門控機制。該機制由三個小的FFN組成,每個FFN產生一個標量值,然后將其分別應用于LoRA、前綴和適配器矩陣。
EFFICIENT PEFT DESIGN

從計算的角度來看,處理延遲和峰值內存開銷是需要考慮的關鍵因素。本節介紹LLM的一個關鍵特性,旨在平衡延遲和內存使用(第IV-a節)。在此之后,我們探索了開發高效PEFT方法以應對計算挑戰的策略,包括PEFT修剪(第IV-B節)、PEFT量化(第IV-C節)和記憶高效PEFT技術(第IV-D節),每種技術都旨在提高模型性能,同時最大限度地減少資源消耗。值得注意的是,量化本質上解決了存儲器開銷問題。然而,鑒于其獨特的特性,我們單獨討論了這些量化方法,而不是將它們納入記憶有效PEFT部分。
A. KV-cache Management for PEFT Efficiency
LLM模型的核心是一個自回歸Transformer模型,如圖2所示。當我們觀察自回歸特性時,它成為設計推理系統的一個主要挑戰,因為每次生成新的令牌時,整個LLM模型都必須將所有權重從不同的內存轉移到圖形處理器的內存中,這對單用戶任務調度或多用戶工作負載平衡非常不友好。服務于自回歸范式的挑戰性部分是,所有先前的序列都必須被緩存并保存以供下一次迭代,從先前序列生成的緩存激活被存儲為鍵值緩存(KV緩存)。
KV緩存的存儲將同時消耗內存空間和IO性能,導致工作負載內存受限且系統計算能力利用不足。以前的工作提出了一系列解決方案,如KV緩存控制管理或KV緩存壓縮,以提高吞吐量或減少延遲。在設計PEFT方法時,考慮KV緩存的特性以補充其特性是至關重要的。例如,當在推理階段應用軟提示時,通過確保與提示相關的數據易于訪問,有效地利用KV緩存進行這些額外的輸入可以幫助加快響應時間。
B.Pruning Strategies for PEFT
修剪的加入可以大大提高PEFT方法的效率。特別是,AdapterDrop探索了在AdapterFusion中從較低的轉換層和多任務適配器中刪除適配器,這表明修剪可以在性能下降最小的情況下提高訓練和推理效率。SparseAdapter研究了不同的修剪方法,發現高稀疏率(80%)可以優于標準適配器。此外,大稀疏配置增加了瓶頸尺寸,同時保持了恒定的參數預算(例如,以50%的稀疏度將尺寸翻倍),大大增強了模型的容量,從而提高了性能。
C. Quantization Strategies for PEFT
量化是提高計算效率和減少內存使用的另一種流行技術。例如,通過研究適配器的損失情況,BI Adapter發現適配器能夠抵抗參數空間中的噪聲。在此基礎上,作者引入了一種基于聚類的量化方法。值得注意的是,它們證明了適配器的1位量化不僅最大限度地減少了存儲需求,而且在所有精度設置中都實現了卓越的性能。PEQA(參數高效和量化感知自適應)使用兩級流水線來實現參數高效和量化器感知微調。QA LoRA解決了QLoRA的另一個局限性,QLoRA在微調后難以保持其量化特性。在QLoRA中,量化的預訓練權重(NF4)必須恢復到FP16,以在權重合并期間匹配LoRA權重精度(FP16)。相反,QA LoRA使用INT4量化,并引入分組運算符以在推理階段實現量化,因此與QLoRA相比提高了效率和準確性。
D. Memory-efficient PEFT Methods
QA LoRA解決了QLoRA的另一個局限性,即在微調后難以保持其量化特性。在QLoRA中,量化的預訓練權重(NF4)必須恢復到FP16,以在權重合并期間匹配LoRA權重精度(FP16)。相反,QA LoRA使用INT4量化,并引入分組運算符以在推理階段實現量化,因此與QLoRA相比提高了效率和準確性。
為了提高內存效率,已經開發了各種技術來最小化在微調期間對整個LLM的緩存梯度的需要,從而減少內存使用。例如,Side-Tuning和LST(Ladder-Side Tuning)都引入了與主干模型并行的可學習網絡分支。通過專門通過這個并行分支引導反向傳播,它避免了存儲主模型權重的梯度信息的需要,從而顯著降低了訓練期間的內存需求。類似地,Res Tuning將PEFT調諧器(例如,即時調諧、適配器)與主干模型分離。在分解的基礎上,提出了一個名為Res-Mtuning Bypass的高效內存微調框架,該框架通過去除從解耦的調諧器到主干的數據流,生成與主干模型并行的旁路網絡。
PEFT FOR DNNS OF OTHER APPLICATIONS
在第三節中,我們概述了四類PEFT方法及其改進。盡管如此,我們的討論并沒有完全擴展到傳統架構(如LLM)或標準基準(如GLUE數據集)之外的PEFT技術的利用或適應,其中大多數討論的PEFT方法都是應用的。因此,在本節中,我們將重點介紹和討論利用PEFT策略執行各種下游任務的幾項最具代表性的工作。我們并不打算在本節中涵蓋所有PEFT應用場景。我們的目標是展示產品環境足跡在各個研究領域的重大影響,并展示如何優化和定制通用產品環境足跡方法,以提高特定模型或任務的性能。
通常,在將預先訓練的主干模型適應專門的下游任務時會進行微調。為此,本節圍繞各種模型架構組織討論,這些架構包括:LLM、視覺Transformer(ViT)、視覺語言對齊模型(VLA)和擴散模型。在每個體系結構類別中,討論是基于不同的下游任務進行進一步分類的。
A. PEFT for LLMs – Beyond the Basics
與NLP中的常見任務(如NLU和NLG)不同,PEFT技術在不同的場景中具有廣泛的應用。PEFT已成功應用于常識性問答、多層次隱含話語關系識別、分布外檢測、隱私保護、聯合學習和社會偏見緩解等領域。在本節中,我們將更多地關注三個具有代表性的下游任務:視覺教學跟隨、持續學習和上下文窗口擴展。
1)視覺指導:包括VL-BART、MiniGPT-4和LLaVA在內的幾項研究成功地擴展了LLM的能力,LLM最初是為純文本設計的,可以理解和生成對視覺輸入的響應。這些增強的模型,即視覺指令跟隨LLM,可以處理圖像和文本以產生文本響應,這些文本響應可以在圖像字幕和視覺問答(VQA)等任務上進行基準測試。然而,這些方法對整個LLM進行微調以學習視覺表示,這在時間和內存方面都是低效的。因此,將PEFT技術應用于LLM后視覺教學的微調是很自然的。
2)持續學習(CL):CL旨在在一個模型中學習一系列新任務,在對話系統、信息提取系統和問答系統等場景中有廣泛應用。CL的主要挑戰是災難性遺忘。一種流行的做法,稱為基于體系結構的方法,通過在模型中為每個新任務維護特定于任務的參數來處理CL。因此,將PEFT方法用于CL任務是很自然的。
3)上下文窗口擴展:LLM通常使用預定義的上下文大小進行訓練。例如,LLaMA和LLaMA2分別具有2048和4096個令牌的預定義上下文大小。位置編碼RoPE具有弱的外推特性,這意味著在輸入長度超過預定義上下文長度的情況下,性能明顯下降。為了解決這個問題,一個簡單的解決方案是將預先訓練的LLM微調到更長的上下文。然而,這會隨著上下文大小的二次方增加計算成本,從而使內存和處理資源緊張。
B. PEFT for ViTs
在最近的計算機視覺社區中,ViT已經成為一種強大的骨干模型。在ViT模型中,圖像被視為固定大小的補丁序列,類似于LLM如何使用離散標記。這些補丁經過線性嵌入,然后接收位置編碼。隨后,它們通過標準的Transformer編碼器進行處理。ViT的訓練可以是監督的或自監督的,并且當使用更多數據和更大的模型大小進行訓練時,ViT可以實現卓越的性能。然而,這種規模的擴大不可避免地會增加培訓和存儲成本。因此,與LLM類似,PEFT廣泛應用于各種下游任務,如密集預測、連續學習、深度度量學習。在這里,我們重點關注兩個典型的任務來展示PEFT的參與:圖像分類和視頻復原。
1)圖像分類:在目標視覺數據集上進行圖像分類是一種非常普遍的需求,具有廣泛的應用,而預訓練-微調范式是一種廣泛的策略。多種方法利用PEFT技術實現有效的模型調整。
2)視頻識別:一些工作考慮了更具挑戰性的適應問題,即將ViT轉移到具有更大領域差距的下游任務。例如,ST適配器(時空適配器)和AIM都將適配器層插入到預訓練的ViT塊中。他們的主要目標是對時空信息進行建模,從而使ViT能夠有效地從圖像模型適應視頻任務。值得注意的是,這兩種方法的性能都超過了傳統的全模型微調方法。
C. PEFT for VLAs
視覺語言對齊模型(VLA),如CLIP、ALIGN、DeCLIP和FLAVA,旨在學習可以在統一表示空間內對齊的良好圖像和文本特征。每個VLA通常由提取各自特征的獨立圖像和文本編碼器組成。在這些模型中,對比學習被用來有效地對齊圖像和文本特征。微調被用來提高VLA在特定數據集或任務中的性能,但對整個模型的微調是計算密集型的。
1) 開放式詞匯圖像分類:在開放式詞匯的圖像分類中,早期的作品為每個類別設計特定類別的提示,例如class的照片,并根據圖像與這些文本描述的相似性對圖像進行排名。CoOp(上下文優化)用可學習向量替換手工制作的文本提示,同時在訓練期間保留整個VLA修復。CoCoOp(條件上下文優化)通過解決CoOp在推廣到看不見的類方面的局限性,建立在這一基礎上。
在另一個方向上,一些研究探討了適配器在VLA中的使用。例如,CLIP適配器在CLIP的文本和視覺編碼器之后集成了殘余樣式適配器。因此,與CoOp和CoCoOp不同,CLIP Adapter避免了通過CLIP編碼器的梯度反向傳播,從而降低了訓練內存和時間方面的計算要求。尖端適配器采用與CLIP適配器相同的設計。與CLIP適配器不同的是,適配器的權重是以無訓練的方式從查詢密鑰緩存模型中獲得的,該模型是以非參數方式從最少監督構建的。因此,與CLIP-Adapter的SGD訓練過程相比,Tip-Adapter表現出了極大的效率。
D. PEFT for Diffusion Models
擴散模型是一類生成模型,通過漸進去噪過程將隨機噪聲轉換為結構化輸出,學習生成數據。在訓練過程中,擴散模型學習使用去噪網絡來反轉添加到訓練數據中的噪聲,而在推理中,它們從噪聲開始,使用去噪網迭代創建與訓練示例相同分布的數據。擴散模型有各種應用,而最值得注意的是穩定擴散,它以其直接從文本描述生成連貫和上下文相關圖像的強大能力彌合了文本和圖像之間的差距。許多研究利用PEFT技術將預先訓練的擴散模型用于下游任務,包括加速采樣速度、文本到視頻的自適應、文本到3D的自適應等。本節主要關注兩種場景:在僅基于文本的條件之外集成額外的輸入模式,以及基于預先訓練的傳播模型定制內容生成。
1)附加輸入控制:為了在保留預先訓練的模型中的廣泛知識的同時納入附加輸入模式(如布局、關鍵點),GLIGEN引入了一種新的方法,該方法保持原始模型的權重不變,并集成新的、可訓練的門控Transformer,以接受新的接地輸入。所得到的模型不僅可以準確地表示接地條件,而且可以生成高質量的圖像。值得注意的是,該模型在推理過程中也能很好地推廣到看不見的物體。
2)自定義生成:文本到圖像擴散模型的有效性受到用戶通過文本描述闡明所需目標的能力的限制。例如,很難描述一輛創新玩具車的精確特征,而這在大型模型訓練中是不會遇到的。因此,定制生成的目標是使模型能夠從用戶提供的圖像的最小集合中掌握新概念。
SYSTEM DESIGN CHALLENGE FOR PEFT
A. System design for PEFT
在本節中,我們首先簡要介紹基于云的PEFT系統。接下來,我們介紹了用于評估系統性能的相應指標。此外,我們還提出了三種潛在的利用場景,以說明系統設計中的挑戰。
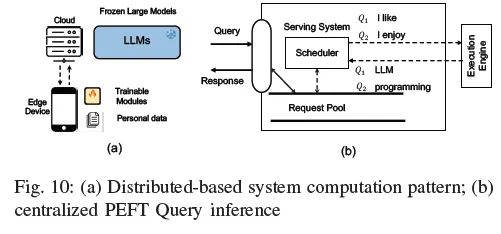
1) 集中式PEFT查詢服務:云提供商最近推出了一系列LLM服務,旨在通過應用程序編程接口(API)提供用戶應用程序。這些API有助于將許多ML功能無縫集成到應用程序中。在通過API接收到針對一個特定下游任務的一個查詢之后,基于云的服務器使用一個特色LLM模型來處理該查詢。在這種情況下,所提出的用于處理多個PEFT查詢的云解決方案涉及僅存儲LLM的單個副本和多個PETT模塊。此單個副本維護多個PEFT模塊分支,每個分支與不同的PEFT查詢相關聯。最先進系統的案例研究可在第VI-C節中找到。圖10(b)說明了多查詢PEFT推理的計算模式,其中打包PEFT查詢根據其截止日期和當前系統條件進行調度和執行。
2) 服務指標:為了評估集中式PEFT查詢服務的系統性能,我們提出了一組評估指標。
- 系統吞吐量:將PEFT查詢視為內部任務和內部任務,我們使用每秒令牌來測量系統吞吐量。
- 內存占用:查詢服務期間的運行時內存消耗,內存利用率來自模型參數和KV緩存,如第IV-A節所述。
- 準確性性能:真實世界的查詢通常具有不同的上下文長度,具有變化長度的性能作為性能基準。
- 服務質量:查詢與延遲要求相關,截止日期缺失率被視為另一個基準。
3) PEFT的分布式系統:然而,在當代LLM模型中,預先訓練的模型并不完全支持個性化任務,因此,需要使用前面章節中提到的方法進行額外的微調。然而,當我們考慮將數據集提供給云提供商時,會引起一個很大的擔憂,因為這些數據集是個性化的。
對于這個問題,我們假設我們的計算遵循模型集中式和PEFT分布式范式。骨干LLM存儲在云設備中,而個人PEFT權重以及數據集存儲在用戶自己的設備中。如圖10(a)所示。
4) 分布式度量:為了評估所提出方法的有效性,我們建立了一組評估度量。為了進行此分析,在不失一般性的情況下,我們采用語言模型作為度量定義的基礎。
- 精度性能:微調模型在下游任務中的性能。
- 計算成本:在邊緣設備上進行正向和反向傳播操作期間的計算成本。
- 通信成本:指邊緣設備和云之間傳輸中間數據時所涉及的數據量。
5) 多產品環境足跡培訓:與多個產品環境足跡服務不同,使用多個定制產品環境足跡進行調整總是涉及不同的骨干LLM。當考慮在各種下游任務中使用LLM時,預先訓練的模型通常表現出較差的性能。使LLM適應不同任務的一種流行方法涉及精心調整的PEFT。然而,同時調整多個PEFT可能會帶來相當大的挑戰。如何管理內存梯度和模型權重存儲,以及如何設計用于批處理PEFT訓練的高效內核等挑戰仍未解決。產品環境足跡將根據其產品環境足跡算法和骨干LLM模型進行分類。設計挑戰涉及如何同時將多個具有相同LLM主干和多個不同LLM主干的PEFT合并。
B. Parallel PEFT Training Frameworks
a) 設計挑戰:與旨在適應靈活的多PEFT算法的PetS系統不同,SLoRA和Punica僅專注于促進各種任務的多個LoRA塊。設計多個產品環境足跡培訓系統主要面臨兩個方面的關鍵挑戰 方面:
- 具有相同LLM主干的多個PEFT模型的高效并發執行。
- 設計一個高效的系統,用于不同LLM骨干網的多租戶服務。
b)高效的內核設計:Punica解決了第一個挑戰,將現有的矩陣乘法用于主干計算,并引入了一種新的CUDA內核——分段聚集矩陣矢量乘法(SGMV),用于以批處理的方式將PEFT附加項添加到主干計算中。該內核對批處理中不同請求的特征權重相乘進行并行化,并將對應于同一PEFT模型的請求分組,以增加操作強度并使用GPU張量核心進行加速。
第二個挑戰超出了計算成本,設計一種高效的系統架構是另一個重大挑戰,該架構可以在盡可能小的GPU集上有效地服務于多租戶PEFT模型工作負載,同時占用最少的GPU資源。Punica通過將用戶請求調度到已經服務或訓練PEFT模型的活動GPU來解決這一問題,從而提高GPU利用率。對于較舊的請求,Punica會定期遷移它們以整合工作負載,從而為新請求釋放GPU資源。
c)多租戶PEFT設計:為Punica框架中的多租戶PEVT模型設計一個高效的系統,重點是解決幾個關鍵挑戰,以最大限度地提高硬件利用率并最大限度地減少資源消耗。該系統旨在將多租戶LoRA服務工作負載整合到盡可能小的GPU集上。這種整合是通過對已經在服務或訓練LoRA模型的活動GPU的用戶請求進行戰略調度來實現的,從而提高GPU利用率。對于較舊的請求,Punica會定期遷移它們以進一步整合工作負載,從而為新請求釋放GPU資源。它結合了LoRA模型權重的按需加載,只引入了毫秒級的延遲。該功能為Punica提供了將用戶請求動態合并到一小組GPU的靈活性,而不受已經在這些GPU上運行的特定LoRA模型的約束。除此之外,Punica認為解碼階段是模型服務成本的主要因素,其設計主要側重于優化解碼階段的性能。模型服務的其他方面利用直接的技術,例如按需加載LoRA模型權重,來有效地管理資源利用率。
結論和未來方向
在當前由大型模型和大型數據集主導的時代,PEFT是一種非常有吸引力的方法,可以有效地使模型適應下游任務。這項技術通過解決傳統的全模型微調帶來的重大挑戰而獲得吸引力,這種微調通常會給普通用戶帶來難以維持的計算和數據需求。本調查對PEFT的最新進展進行了系統回顧,涵蓋算法開發、計算和效率方面、應用和系統部署。它提供了一個全面的分類和解釋,作為一個很好的指導和知識庫,使不同級別和學科的讀者能夠迅速掌握PEFT的核心概念。
為了進一步研究PEFT,我們從算法和系統的角度提出了一系列可能的方向,希望能激勵更多的研究人員在這些領域進行進一步的研究。
A. Simplify hyperparameter tuning
PEFT的有效性通常對其超參數敏感,如適配器的瓶頸尺寸r、LoRA的等級和不同附加PEFT層的位置。手動調整這些超參數將花費大量精力。因此,未來的工作可以集中在開發不太依賴手動調整這些參數的方法,或者自動找到最佳超參數設置。一些研究已經開始解決這個問題,但需要更簡單有效的解決方案來優化這些超參數。
B. Establish a unified benchmark
盡管存在像HuggingFace的PEFT和AdapterHub這樣的庫,但仍然缺乏一個全面的PEFT基準。這種差距阻礙了公平比較不同PEFT方法的性能和效率的能力。一個被廣泛接受的、類似于物體檢測的MMDetection的最新基準將使研究人員能夠根據一組標準的任務和指標來驗證他們的方法,從而促進社區內的創新和合作。
C. Enhance training efficiency
PEFT的假定參數效率并不總是與訓練期間的計算和內存節省一致。考慮到可訓練參數在預訓練模型的體系結構中相互交織,在微調過程中通常需要計算和存儲整個模型的梯度。這種監督要求重新思考什么是效率。如第四節所述,潛在的解決方案在于模型壓縮技術的集成,如修剪和量化,以及專門為優化PEFT調整期間的內存而設計的創新。進一步研究提高PEFT方法的計算效率勢在必行。
D. Explore scaling laws
最初為較小的Transformer模型開發的PEFT方法的設計和有效性不一定與較大的模型相適應。隨著基礎模型規模的增加,識別和調整保持有效的產品環境足跡戰略至關重要。這一探索將有助于根據大型模型架構的發展趨勢定制PEFT方法。
E. Serve more models and tasks
大型基礎模型在各個領域的興起為PEFT提供了新的機會。設計適合模型獨特特征的PEFT方法,如Sora、Mamba和LVM,可以釋放新的應用場景和機會。
F. Enhancing data privacy
信任集中式系統來服務或微調個性化PEFT模塊是系統開發人員的另一個問題。側通道攻擊者已成功部署,通過劫持中間結果來重建用戶的數據。未來值得信賴的LLM系統設計的一個視角涉及為個人數據以及中間訓練和推理結果開發加密協議。
G. PEFT with model compression
模型壓縮是使LLM在資源有限的設備上可執行的最有效方法之一。然而,模型壓縮技術對在硬件上運行的PEFT算法性能的影響仍然是另一個系統性挑戰。量化和修剪等常見的壓縮技術需要專用的硬件平臺來加快過程,而為壓縮模型構建這樣的硬件平臺是研究人員的另一個方向。




















