













GPT-4「榮升」AI頂會同行評審專家?斯坦福最新研究:ICLR/NeurIPS等竟有16.9%評審是ChatGPT生成
LLM在飛速進步的同時,人類也越來越難以區(qū)分LLM生成的文本與人工編寫的內(nèi)容,甚至分辨能力與隨機器不相上下。
這加大了未經(jīng)證實的生成文本可以偽裝成權(quán)威、基于證據(jù)的寫作的風險。
盡管在個例上難以察覺,但由于LLM的輸出趨于一致性,這種趨勢可能會放大語料庫級別的偏見。
基于這一點,一支來自斯坦福的團隊提出一種方法,以此來對包含不確定量的AI生成文本的真實世界數(shù)據(jù)集進行可比較的評估,并在AI會議的同行評審文本中驗證。

論文地址:https://arxiv.org/abs/2403.07183
AI會議的同行評審可能是AI?
同行評審是一種學(xué)術(shù)論文發(fā)表前的質(zhì)量評估機制。
這些同行評審者通常具有相關(guān)領(lǐng)域的專業(yè)知識,他們會對論文的原創(chuàng)性、方法學(xué)、數(shù)據(jù)分析、結(jié)果解釋等進行評價,以確保論文的科學(xué)性和可信度。
斯坦福團隊研究的AI會議包括ICLR 2024、NeurIPS 2023、CoRL 2023和EMNLP 2023,他們的研究發(fā)生在ChatGPT發(fā)布之后,實驗觀察估計LLM可能會顯著修改或生成的大語料庫中的文本比例。
結(jié)果顯示,有6.5%到16.9%可能是由LLM大幅修改的,即超出了拼寫檢查或微小寫作更新的范圍。
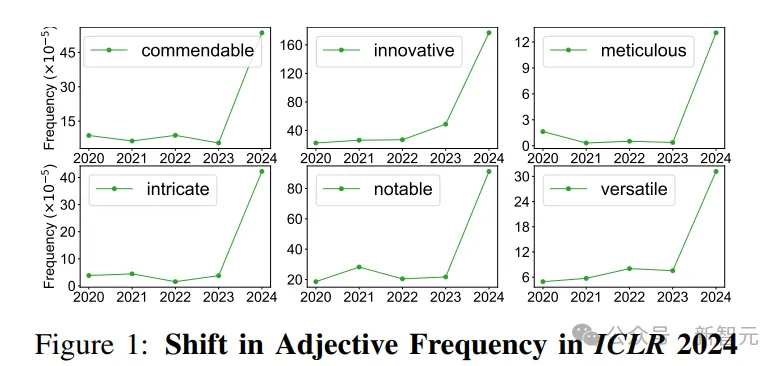
在下圖中,可以看到ICLR 2024同行評審中,某些形容詞的頻率發(fā)生了顯著變化,例如「值得稱贊的」、「細致的」和「復(fù)雜的」,它們在出現(xiàn)在句子中的概率分別增加了9.8倍、34.7倍和11.2倍。而這些詞大概率是由人工智能生成的。
同時研究還發(fā)現(xiàn),在報告較低自信度、接近截稿時間以及不太可能回應(yīng)作者反駁的評論中,LLM生成文本的估計比例較高。
最大似然讓LLM現(xiàn)形
因為LLM檢測器的性能不穩(wěn)定,所以比起嘗試對語料庫中的每個文檔進行分類并計算總數(shù),研究人員采用了最大似然的方法。
研究方法主要分成四個步驟:
1. 收集(人類)作者的寫作指導(dǎo)——在這個情況下是同行評審指導(dǎo)。將這些指導(dǎo)作為提示輸入到一個LLM中,生成相應(yīng)的AI生成文檔的語料庫。
2. 使用人類和AI文檔語料庫,估算參考標記使用分布P和Q。
3. 在已知正確比例的AI生成文檔的合成目標語料庫上驗證方法的性能。
4. 基于對P和Q的這些估計,使用最大似然法估算目標語料庫中AI生成或修改文檔的比例α。
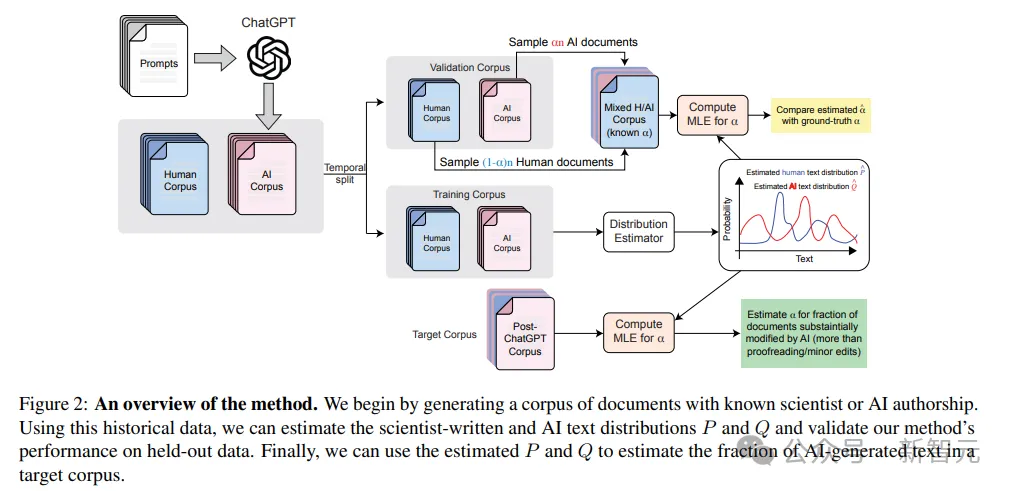
上圖對方法進行了流程可視化。
研究人員首先生成一個具有已知科學(xué)家或AI作者身份的文檔語料庫。利用這些歷史數(shù)據(jù),我們可以估算科學(xué)家撰寫的文本和AI文本的分布P和Q,并驗證我們方法在留存數(shù)據(jù)上的性能。最后,使用估算的P和Q來估算目標語料庫中 AI 生成文本的比例。
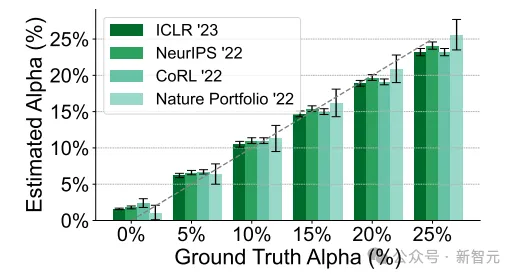
在驗證集中,該方法在LLM生成反饋比例方面表現(xiàn)出高精度,預(yù)測誤差不到2.4%。同時,團隊對魯棒性也進行了驗證。
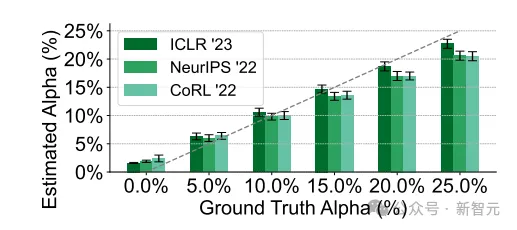
另外,一位審稿人可能會分兩個不同階段起草他們的審稿意見:首先,在閱讀論文時創(chuàng)建審稿的簡要大綱,然后使用LLM擴展這個大綱以形成詳細、全面的審稿意見。
在這種場景的驗證中,算法仍舊表現(xiàn)出色,能夠檢測到LLM用于大幅擴展由人提供的審稿大綱的情況。
實驗結(jié)果中還發(fā)現(xiàn)了什么
首先,團隊將AI會議的同行評審和Nature Portfolio期刊的α進行了比較。
與AI會議相反,Nature Portfolio期刊在ChatGPT發(fā)布后沒有顯示出估計α值的顯著增加,ChatGPT發(fā)布前后的α估計值仍在α = 0驗證實驗的誤差范圍內(nèi)。
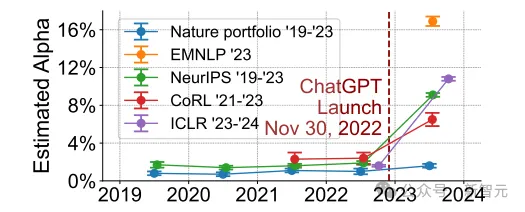
這種一致性表明,在與機器學(xué)習(xí)專業(yè)領(lǐng)域相比,廣泛的科學(xué)學(xué)科對AI工具的反應(yīng)有明顯的不同。
除了發(fā)現(xiàn)同行評審文本中,有6.5%到16.9%來自于LLM的手筆之外,該研究還發(fā)現(xiàn)了一些有意思的用戶行為,在四個AI會議里保持一致:
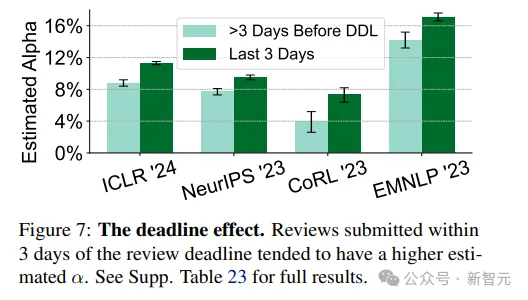
1. 截至日期效應(yīng):在審稿截止日期前3天內(nèi)提交的評審?fù)鼉A向于用GPT
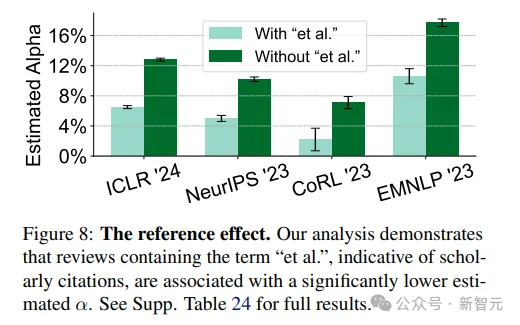
2. 參考文獻效應(yīng):包含「et al.」一詞的評審,即有學(xué)術(shù)引用的評審,更不會用GPT
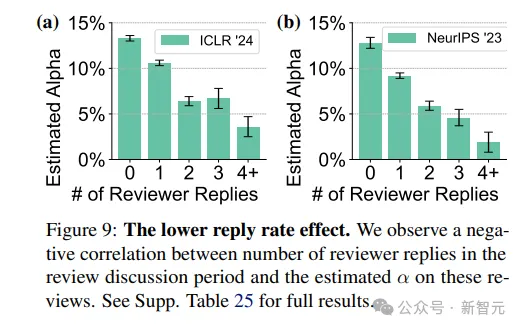
3. 回復(fù)率降低效應(yīng):審稿討論期間,審稿人回復(fù)數(shù)量越多,評審更不會用GPT
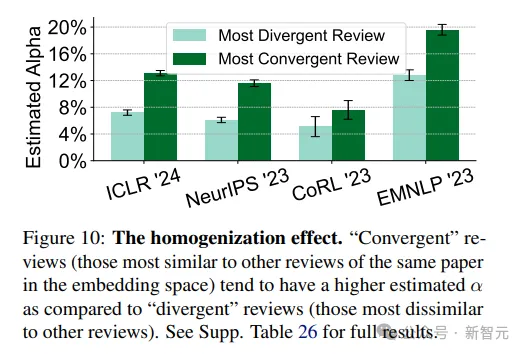
4. 同質(zhì)化效應(yīng):與同論文其他審稿意見越相似的評審,越可能用GPT
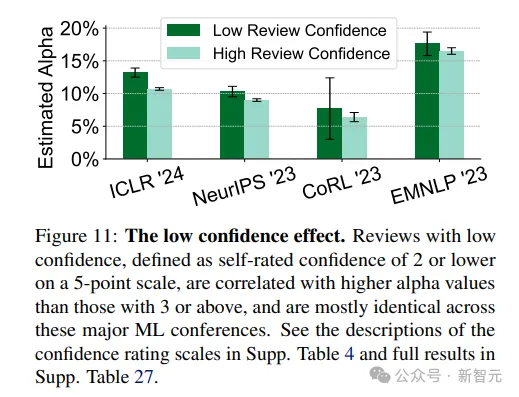
5. 低置信度效應(yīng):自評置信度在5分制度中為2分或以下的評審與較高置信度(3分或以上)的評審相比,更可能用了GPT
盡管這項研究存在一定的局限性,比如只涉及了四個會議、僅使用了GPT-4來生成AI文本,并且可能存在其他誤差來源,比如由于主題和審稿人的變化而導(dǎo)致的模型時間分布的偏差。
但是,研究的結(jié)論啟示了LLM可能對科學(xué)界產(chǎn)生的潛在影響,這有助于激發(fā)進一步的社會分析和思考。希望這些研究結(jié)果能夠促進對于LLM在未來信息生態(tài)系統(tǒng)中應(yīng)該如何使用以及可能帶來的影響的深入探討,從而推動出臺更加明智的政策決策。





























