













CMU朱俊彥、Adobe新作:512x512圖像推理,A100只用0.11秒
簡(jiǎn)筆素描一鍵變身多風(fēng)格畫(huà)作,還能添加額外的描述,這在 CMU、Adobe 聯(lián)合推出的一項(xiàng)研究中實(shí)現(xiàn)了。
作者之一為 CMU 助理教授朱俊彥,其團(tuán)隊(duì)在 ICCV 2021 會(huì)議上發(fā)表過(guò)一項(xiàng)類似的研究:僅僅使用一個(gè)或數(shù)個(gè)手繪草圖,即可以自定義一個(gè)現(xiàn)成的 GAN 模型,進(jìn)而輸出與草圖匹配的圖像。

- 論文地址:https://arxiv.org/pdf/2403.12036.pdf
- GitHub 地址:https://github.com/GaParmar/img2img-turbo
- 試玩地址:https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
- 論文標(biāo)題:One-Step Image Translation with Text-to-Image Models
效果如何?我們上手試玩了一番,得出的結(jié)論是:可玩性非常強(qiáng)。其中輸出的圖像風(fēng)格多樣化,包括電影風(fēng)、3D 模型、動(dòng)畫(huà)、數(shù)字藝術(shù)、攝影風(fēng)、像素藝術(shù)、奇幻畫(huà)派、霓虹朋克和漫畫(huà)。

prompt 為「鴨子」。

prompt 為「一個(gè)草木環(huán)繞的小房子」。

prompt 為「打籃球的中國(guó)男生」。

prompt 為「肌肉男兔子」。



在這項(xiàng)工作中,研究者對(duì)條件擴(kuò)散模型在圖像合成應(yīng)用中存在的問(wèn)題進(jìn)行了針對(duì)性改進(jìn)。這類模型使用戶可以根據(jù)空間條件和文本 prompt 生成圖像,并對(duì)場(chǎng)景布局、用戶草圖和人體姿勢(shì)進(jìn)行精確控制。
但是問(wèn)題在于,擴(kuò)散模型的迭代導(dǎo)致推理速度變慢,限制了實(shí)時(shí)應(yīng)用,比如交互式 Sketch2Photo。此外模型訓(xùn)練通常需要大規(guī)模成對(duì)數(shù)據(jù)集,給很多應(yīng)用帶來(lái)了巨大成本,對(duì)其他一些應(yīng)用也不可行。
為了解決條件擴(kuò)散模型存在的問(wèn)題,研究者引入了一種利用對(duì)抗學(xué)習(xí)目標(biāo)來(lái)使單步擴(kuò)散模型適應(yīng)新任務(wù)和新領(lǐng)域的通用方法。具體來(lái)講,他們將 vanilla 潛在擴(kuò)散模型的各個(gè)模塊整合到擁有小的可訓(xùn)練權(quán)重的單個(gè)端到端生成器網(wǎng)絡(luò),從而增強(qiáng)模型保留輸入圖像結(jié)構(gòu)的能力,同時(shí)減少過(guò)擬合。
研究者推出了 CycleGAN-Turbo 模型,在未成對(duì)設(shè)置下,該模型可以在各種場(chǎng)景轉(zhuǎn)換任務(wù)中優(yōu)于現(xiàn)有基于 GAN 和擴(kuò)散的方法, 比如晝夜轉(zhuǎn)換、添加或移除霧雪雨等天氣效果。
同時(shí),為了驗(yàn)證自身架構(gòu)的通用性,研究者對(duì)成對(duì)設(shè)置進(jìn)行實(shí)驗(yàn)。結(jié)果顯示,他們的模型 pix2pix-Turbo 實(shí)現(xiàn)了與 Edge2Image、Sketch2Photo 不相上下的視覺(jué)效果,并將推理步驟縮減到了 1 步。
總之,這項(xiàng)工作表明了,一步式預(yù)訓(xùn)練文本到圖像模型可以作為很多下游圖像生成任務(wù)的強(qiáng)大、通用主干。
方法介紹
該研究提出了一種通用方法,即通過(guò)對(duì)抗學(xué)習(xí)將單步擴(kuò)散模型(例如 SD-Turbo)適配到新的任務(wù)和領(lǐng)域。這樣做既能利用預(yù)訓(xùn)練擴(kuò)散模型的內(nèi)部知識(shí),同時(shí)還能實(shí)現(xiàn)高效的推理(例如,對(duì)于 512x512 圖像,在 A6000 上為 0.29 秒,在 A100 上為 0.11 秒)。
此外,單步條件模型 CycleGAN-Turbo 和 pix2pix-Turbo 可以執(zhí)行各種圖像到圖像的轉(zhuǎn)換任務(wù),適用于成對(duì)和非成對(duì)設(shè)置。CycleGAN-Turbo 超越了現(xiàn)有的基于 GAN 的方法和基于擴(kuò)散的方法,而 pix2pix-Turbo 與最近的研究(如 ControlNet 用于 Sketch2Photo 和 Edge2Image)不相上下,但具有單步推理的優(yōu)勢(shì)。
添加條件輸入
為了將文本到圖像模型轉(zhuǎn)換為圖像轉(zhuǎn)換模型,首先要做的是找到一種有效的方法將輸入圖像 x 合并到模型中。
將條件輸入合并到 Diffusion 模型中的一種常用策略是引入額外的適配器分支(adapter branch),如圖 3 所示。
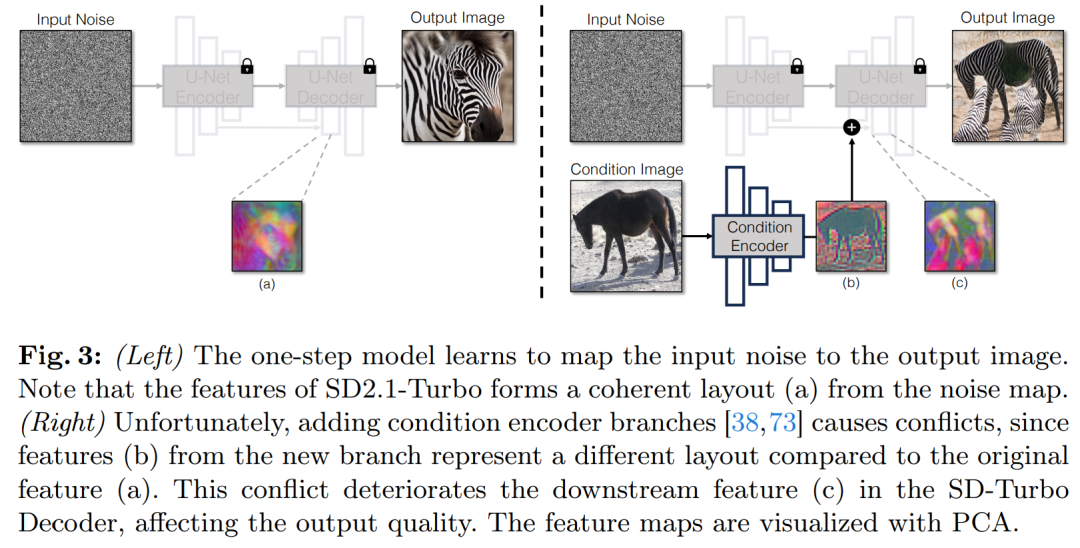
具體來(lái)說(shuō),該研究初始化第二個(gè)編碼器,并標(biāo)記為條件編碼器(Condition Encoder)。控制編碼器(Control Encoder)接受輸入圖像 x,并通過(guò)殘差連接將多個(gè)分辨率的特征映射輸出到預(yù)訓(xùn)練的 Stable Diffusion 模型。該方法在控制擴(kuò)散模型方面取得了顯著成果。
如圖 3 所示,該研究在單步模型中使用兩個(gè)編碼器(U-Net 編碼器和條件編碼器)來(lái)處理噪聲圖像和輸入圖像遇到的挑戰(zhàn)。與多步擴(kuò)散模型不同,單步模型中的噪聲圖直接控制生成圖像的布局和姿態(tài),這往往與輸入圖像的結(jié)構(gòu)相矛盾。因此,解碼器接收到兩組代表不同結(jié)構(gòu)的殘差特征,這使得訓(xùn)練過(guò)程更加具有挑戰(zhàn)性。
直接條件輸入。圖 3 還說(shuō)明了預(yù)訓(xùn)練模型生成的圖像結(jié)構(gòu)受到噪聲圖 z 的顯著影響。基于這一見(jiàn)解,該研究建議將條件輸入直接饋送到網(wǎng)絡(luò)。為了讓主干模型適應(yīng)新的條件,該研究向 U-Net 的各個(gè)層添加了幾個(gè) LoRA 權(quán)重(見(jiàn)圖 2)。
保留輸入細(xì)節(jié)
潛在擴(kuò)散模型 (LDMs) 的圖像編碼器通過(guò)將輸入圖像的空間分辨率壓縮 8 倍同時(shí)將通道數(shù)從 3 增加到 4 來(lái)加速擴(kuò)散模型的訓(xùn)練和推理過(guò)程。這種設(shè)計(jì)雖然能加快訓(xùn)練和推理速度,但對(duì)于需要保留輸入圖像細(xì)節(jié)的圖像轉(zhuǎn)換任務(wù)來(lái)說(shuō),可能并不理想。圖 4 展示了這一問(wèn)題,我們拿一個(gè)白天駕駛的輸入圖像(左)并將其轉(zhuǎn)換為對(duì)應(yīng)的夜間駕駛圖像,采用的架構(gòu)不使用跳躍連接(中)。可以觀察到,如文本、街道標(biāo)志和遠(yuǎn)處的汽車等細(xì)粒度的細(xì)節(jié)沒(méi)有被保留下來(lái)。相比之下,采用了包含跳躍連接的架構(gòu)(右)所得到的轉(zhuǎn)換圖像在保留這些復(fù)雜細(xì)節(jié)方面做得更好。

為了捕捉輸入圖像的細(xì)粒度視覺(jué)細(xì)節(jié),該研究在編碼器和解碼器網(wǎng)絡(luò)之間添加了跳躍連接(見(jiàn)圖 2)。具體來(lái)說(shuō),該研究在編碼器內(nèi)的每個(gè)下采樣塊之后提取四個(gè)中間激活,并通過(guò)一個(gè) 1×1 的零卷積層處理它們,然后將它們輸入到解碼器中對(duì)應(yīng)的上采樣塊。這種方法確保了在圖像轉(zhuǎn)換過(guò)程中復(fù)雜細(xì)節(jié)的保留。

實(shí)驗(yàn)
該研究將 CycleGAN-Turbo 與之前的基于 GAN 的非成對(duì)圖像轉(zhuǎn)換方法進(jìn)行了比較。從定性分析來(lái)看,如圖 5 和圖 6 顯示,無(wú)論是基于 GAN 的方法還是基于擴(kuò)散的方法,都難以在輸出圖像真實(shí)感和保持結(jié)構(gòu)之間達(dá)到平衡。


該研究還將 CycleGAN-Turbo 與 CycleGAN 和 CUT 進(jìn)行了比較。表 1 和表 2 展示了在八個(gè)無(wú)成對(duì)轉(zhuǎn)換任務(wù)上的定量比較結(jié)果。
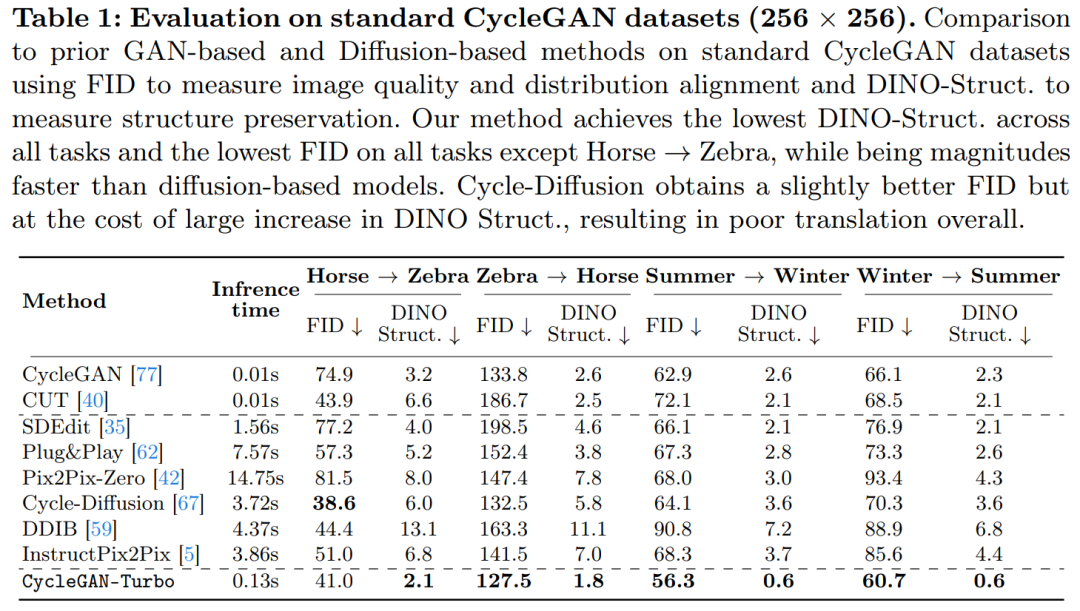

CycleGAN 和 CUT 在較簡(jiǎn)單的、以對(duì)象為中心的數(shù)據(jù)集上,如馬→斑馬(圖 13),展現(xiàn)出有效的性能,實(shí)現(xiàn)了低 FID 和 DINO-Structure 分?jǐn)?shù)。本文方法在 FID 和 DINO-Structure 距離指標(biāo)上略微優(yōu)于這些方法。

如表 1 和圖 14 所示,在以對(duì)象為中心的數(shù)據(jù)集(如馬→斑馬)上,這些方法可以生成逼真的斑馬,但在精確匹配對(duì)象姿勢(shì)上存在困難。
在駕駛數(shù)據(jù)集上,這些編輯方法的表現(xiàn)明顯更差,原因有三:(1)模型難以生成包含多個(gè)對(duì)象的復(fù)雜場(chǎng)景,(2)這些方法(除了 Instruct-pix2pix)需要先將圖像反轉(zhuǎn)為噪聲圖,引入潛在的人為誤差,(3)預(yù)訓(xùn)練模型無(wú)法合成類似于駕駛數(shù)據(jù)集捕獲的街景圖像。表 2 和圖 16 顯示,在所有四個(gè)駕駛轉(zhuǎn)換任務(wù)上,這些方法輸出的圖像質(zhì)量較差,并且不遵循輸入圖像的結(jié)構(gòu)。

























