DDIA:消息系統(tǒng)—生產(chǎn)者和消費者的游戲?
在第十章的時候,我們討論了批處理——它總是讀取一些文件作為輸入,產(chǎn)生一些新文件作為輸出。這里的輸出就是一種“衍生數(shù)據(jù)”:即,如果有需要,我們可以通過再跑一遍批處理任務獲取相同的結(jié)果集。從之前章節(jié)的討論我們可以看出,這種思想簡單卻強大:像搜索引擎、推薦系統(tǒng)、分析系統(tǒng)等很多現(xiàn)代常見的數(shù)據(jù)系統(tǒng)都是基于這種思想構(gòu)建的。
然而,在第十章進行討論時我們有一個很強的假設(shè):輸入數(shù)據(jù)集是有界的——即事先知道輸入尺寸——因此批處理的程序知道輸入何時結(jié)束。舉個例子,MapReduce 中非常重要的排序操作,就必須讀入所有待排序的輸入數(shù)據(jù)后才能開始排序并輸出。這是因為,最后一條數(shù)據(jù),沒準可能是被需要排在最前面(具有最小的 key),因此不可能過早對數(shù)據(jù)排序。
但在現(xiàn)實中,很多數(shù)據(jù)都是無界的且隨著時間持續(xù)到來的:我們的(各種服務的)用戶昨天會產(chǎn)生數(shù)據(jù)、今天會產(chǎn)生數(shù)據(jù),明天也將以同樣的方式繼續(xù)產(chǎn)生數(shù)據(jù)。除非你關(guān)門大吉,否則這些程序?qū)罒o休止地工作,因此我們的數(shù)據(jù)庫永遠也不會到達一個“終態(tài)”(complete state)。因此,如果使用批處理的思想來處理這種持續(xù)來到的數(shù)據(jù)流,就會引出一個數(shù)據(jù)集切分的問題:例如,在一天結(jié)束時處理這一整天的數(shù)據(jù)、在每小時結(jié)束時處理這一小時的數(shù)據(jù)等等。
但上述切分+批處理的方式有個問題:太慢了,用戶可能等不及。比如按天處理時,則其處理結(jié)果只有當這一天結(jié)束后,再花些時間去批處理,才能最終看到結(jié)果。為了降低這個延遲,我們確實可以用更小的粒度進行處理——比如,每秒進行一次處理。甚而,干脆拋棄時間分片的概念,任意數(shù)據(jù)到來的時候就觸發(fā)數(shù)據(jù)處理邏輯。這就是流式處理(steam processing)背后的基本思想。
通常來說,一個“流”(steam)指的是隨時間推移而增量產(chǎn)生的數(shù)據(jù)。這個概念其實很多地方都有:Unix 中標準輸入輸出中(stdin、stdout),編程語言中(迭代器),文件系統(tǒng)相關(guān)的 API 中(如 Java 的 FileInputStream),TCP 連接中,網(wǎng)絡中傳輸?shù)囊粢曨l等等。
在本章中,我們會將事件流(event stream)當做一種數(shù)據(jù)管理機制:即將我們上一章討論的批量數(shù)據(jù)無界化、增量化。我們首先會討論如何表示、存儲和傳輸數(shù)據(jù)流。在“數(shù)據(jù)庫和數(shù)據(jù)流”一節(jié)中,我們會探索數(shù)據(jù)流和數(shù)據(jù)庫的管理。最后,在“處理數(shù)據(jù)流”一節(jié)中,我們將會討論對這些不間斷的數(shù)據(jù)流進行處理的方法和工具,以及基于其構(gòu)建應用的一些方法。
事件流的傳輸
在批處理系統(tǒng)中,任務的輸入和輸出都是文件(可能是單機文件系統(tǒng)中的、也可能是分布式文件系統(tǒng)中的),那么在流式系統(tǒng)中,承載輸入和輸出的是什么呢?
在批處理系統(tǒng)中,雖然輸入是文件,但第一步也通常是解析成一系列的數(shù)據(jù)記錄(records)。在流式處理的上下中,對應數(shù)據(jù)記錄的實體通常被稱為事件(event)。但他們本質(zhì)上都是一個東西:一段小的、自包含的(self-contained、不引用其他數(shù)據(jù))、不可變的某個時間點發(fā)生的信息數(shù)據(jù)。流式系統(tǒng)中的一個事件通常會包含一個時間戳,來標志該事件在某個時鐘系統(tǒng)(time-of-day clock)中發(fā)生的時間點。
下面舉幾個事件的例子。事件可以是由用戶活動產(chǎn)生的,如瀏覽網(wǎng)頁、網(wǎng)上購物;也可以由機器產(chǎn)生,如周期性的溫度傳感器、CPU 利用率指標;在使用Unix工具進行批處理一節(jié)的例子中,我們提到的 web 服務器中的每一行日志,也是一個事件。
我們在第四章中討論過數(shù)據(jù)編碼的事情。事件本質(zhì)上也是數(shù)據(jù),因此可以被編碼為字符串、JSON 或者二進制形式。只有編碼之后,事件才能被存儲,如:
- 追加到文件末尾
- 插入到關(guān)系表中
- 寫到文檔數(shù)據(jù)庫里
也只有在編碼之后,事件才能夠在網(wǎng)絡中進行傳輸,以發(fā)送到其他工作節(jié)點進行處理。
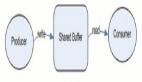
在批處理系統(tǒng)中,一個文件通常是一次寫多次讀的。類似的,在流式處理系統(tǒng)中,一個事件在被生產(chǎn)者(producer,在不同系統(tǒng)中,也可以稱為 publisher 或者 sender)生成之后,可能會被多個感興趣的消費者(consumer,對應的,也可以稱為 subscribers 和 recipients)處理。在文件系統(tǒng)中,文件名可以標識一組數(shù)據(jù)記錄;在流式系統(tǒng)中,相關(guān)的事件通常會聚攏到主題(topic)下或者流(stream)中。換句話說,命名后的流類似于文件,但不同的是,流中的是無界數(shù)據(jù)。
原則上,使用文件或者數(shù)據(jù)庫也足夠用以溝通生產(chǎn)者和消費者:
- 生產(chǎn)者將每個產(chǎn)生的事件寫入數(shù)據(jù)存儲(date store)中(文件系統(tǒng)或者數(shù)據(jù)庫)
- 消費者定期的去從數(shù)據(jù)系統(tǒng)中拉取,并和上次拉取比對,看是否有新事件到來
批處理系統(tǒng)在以天為粒度處理數(shù)據(jù)時,正是用的這種辦法。
但是,在放到低延遲的持續(xù)數(shù)據(jù)流的上下文中時,如果存儲系統(tǒng)不是專門為此定制的,定時去拉取(polling)數(shù)據(jù)的代價會變得很高。且,在數(shù)據(jù)量一定的情況下,你拉取的頻次越高,單次拉到新數(shù)據(jù)的概率就越低,則無效負載也會隨之升高。因此,在流式系統(tǒng)中,當有新事件產(chǎn)生時,按需通知消費者會比頻發(fā)拉取更高效(即推比拉高效)。
傳統(tǒng)上,數(shù)據(jù)庫對于這種通知機制支持的并不是很好:雖然關(guān)系型數(shù)據(jù)中的確有觸發(fā)器(triggers),且可以對數(shù)據(jù)表中的一些事件(如,新插入一行)做出響應,但響應邏輯中能做的很有限(比如做一致性檢查),且通常局限在數(shù)據(jù)庫內(nèi)部(而不能通知到客戶端)。為此,一些專用的工具被開發(fā)出來以進行專門的事件通知。
消息系統(tǒng)
通知消費者有新事件產(chǎn)生的一個常見方法是消息系統(tǒng)(messaging system):生產(chǎn)者將事件以消息的形式發(fā)送到消息系統(tǒng),消息系統(tǒng)將其推送給消費者。我們在經(jīng)由消息傳遞的數(shù)據(jù)流一節(jié)簡單提過消息系統(tǒng),本節(jié)我們將會討論更多細節(jié)。
實現(xiàn)消息系統(tǒng)最簡單的方式,就是使用 Unix 管道或者 TCP連接來溝通生產(chǎn)者和消費者。但大部分消息系統(tǒng)不會如此簡單。比如,Unix 管道和 TCP 連接都是一對一的發(fā)送者和接受者,但成熟的消息系統(tǒng)通常要支持多對多的生產(chǎn)消費——即多個生產(chǎn)者可以將數(shù)據(jù)發(fā)送到一個主題( topic )下,多個消費者可以共通消費這個 topic。
但在這種發(fā)布/訂閱(publish/subscribe)模式之下,不同具體的系統(tǒng)實現(xiàn)方式千差萬別。沒有一種方案能滿足所有需求。為了理解不同系統(tǒng)的實現(xiàn),我們可以帶著兩個問題去考察各個系統(tǒng):
- 如果生產(chǎn)者的生產(chǎn)速度快于消費者的消費速度會發(fā)生什么?通常來說,有三種選擇:丟掉部分消息、緩存多余消息、背壓阻止新消息(backpressure,也被稱為流控,即在消費者處理完之前,阻止生產(chǎn)者產(chǎn)生更多數(shù)據(jù))。具體來說,Unix 管道和 TCP 都使用背壓的方式:他們都有一個很小的緩沖區(qū)(Buffer),如果緩沖區(qū)被填滿,則發(fā)送方阻塞直到接收方消費掉緩沖區(qū)中一些消息,以空出新的位置。如果使用隊列緩沖消息,則需要了解當數(shù)據(jù)量增大到一定地步之后該怎么辦?當內(nèi)存裝不下數(shù)據(jù)之后是宕機還是刷到硬盤上?如果刷到硬盤上,硬盤的訪問將如何影響消息系統(tǒng)的性能?
- 當系統(tǒng)中一些節(jié)點短時間下線會發(fā)生什么?會有消息因此而丟失嗎?和數(shù)據(jù)庫一樣,要想保證持久性,是需要付出一些代價的:如將數(shù)據(jù)寫到硬盤中、將數(shù)據(jù)冗余到其他節(jié)點上等等。如果你能夠接受偶爾丟一些數(shù)據(jù),那在同樣的硬件配置下,你或許能獲得更高的吞吐和更低的延遲。
是否能夠接受消息丟失取決于應用層。例如,對于一些周期性上報的傳感器讀數(shù)來說,偶爾的一兩個采點的丟失影響不大, 因為后面的數(shù)據(jù)會很快的報上來。然而需要注意,如果消息大面積的丟失,可能也很難立即看出來。另外,如果你的目標是對所有到來的事件進行計數(shù),則每條信息都要可靠的傳輸,因為任何一條信息的丟失都會導致計數(shù)錯誤。
我們在上一章中討論過批處理的一個非常友好的性質(zhì)——提供很好的容錯保證。即,所有失敗的子任務會自動的進行重試、所有失敗任務的部分輸出會被丟棄。這種做法會讓系統(tǒng)看起來像沒有發(fā)生過任何故障一樣,從而可以讓應用層大大簡化編程模型(這些分布式故障如果系統(tǒng)不處理,就要應用層自己來處理)。在本章稍后的部分,我們會探討如何在流式處理的上下文中提供類似的保證。
生產(chǎn)者到消費者的直接消息
很多消息系統(tǒng)并不借助中間系統(tǒng)節(jié)點,而直接使用網(wǎng)絡來溝通生產(chǎn)者和消費者雙方:
- UDP 多播。UDP 多播廣泛用在金融系統(tǒng)的數(shù)據(jù)流中,如對時延要求很高的股票市場中的大盤動態(tài)。盡管 UDP 本身是不可靠的,但是可以在應用層增加可靠性算法(類似在應用層實現(xiàn) TCP 的一些算法),對丟失的信息進行恢復(生產(chǎn)者需要記住所有已發(fā)送的消息,才可以按需進行重傳)。
- 無 broker 的消息隊列。像 ZeroMQ 和 nanomsg 等不使用消息 broker 的以庫形式提供的消息隊列,依賴 TCP 或者 IP 多播等方式實現(xiàn)了支持發(fā)布訂閱的消息隊列。
- StatsD 和 Brubeck。這兩個系統(tǒng)底層依賴 UDP 協(xié)議進行傳遞消息,以監(jiān)控所有機器、并收集相關(guān)數(shù)據(jù)指標。(在 StatsD 協(xié)議中,只有事件都收到,counter 相關(guān)指標才會正確;使用 UDP 就意味著使用一種盡可能正確的保證)。
- Webhooks。如果消費者在網(wǎng)絡上暴露出了一個服務,則生產(chǎn)者可以通過 HTTP 或者 RPC 請求(參見經(jīng)由服務的數(shù)據(jù)流:REST 和 RPC)來將數(shù)據(jù)打到消費者中。這就是 webhooks 背后的思想:一個服務會向另一個服務進行注冊,并在有事件產(chǎn)生時向該服務發(fā)送一個請求。
這種直接消息系統(tǒng)在其目標場景中通常能夠工作的很好,但需要應用層代碼自己承擔、處理消息丟失的可能性。此外,這些系統(tǒng)能夠進行的容錯很有限:雖然這些系統(tǒng)在檢測到丟包后會進行重傳,但它們通常會假設(shè)生產(chǎn)者和消費者都一直在線(這是一個很強的假設(shè))。
如果消費者由于某種原因下線了,它可能會錯過一些消息。有些協(xié)議會允許生產(chǎn)者重發(fā)失敗的消息,但如果生產(chǎn)者也掛了,這種方法也無濟于事——生產(chǎn)者會丟掉保存有需要進行重試的消息緩存。
這本質(zhì)上是因為,這些沒有 broker 的消息系統(tǒng)多表現(xiàn)為庫的形式,本身是沒有狀態(tài)的。如果沒有狀態(tài),就沒有辦法應對消息傳輸過程中生產(chǎn)者、消費者宕機重啟的故障。這也是引入 broker 的初衷,但因此消息系統(tǒng)也會變的更加重。
消息代理
一種廣泛使用的替代方案就是使用消息代理(message broker,也稱為消息隊列)來發(fā)送消息。消息代理本質(zhì)上是一種專門為消息數(shù)據(jù)優(yōu)化過的數(shù)據(jù)庫。它通常以進程的形式跑在服務器上,生產(chǎn)者和消費者作為客戶端與之通信。生產(chǎn)者將消息寫入消息代理,消費者從其中讀取以進行消費。
通過引入一個消息數(shù)據(jù)存儲代理,消息系統(tǒng)可以更加容易的對客戶端(包括生產(chǎn)者和消費者)的來來去去(連接、失聯(lián)和宕機)進行容錯。這樣,數(shù)據(jù)的持久化職責被轉(zhuǎn)移到了消息代理上。有些系統(tǒng)中的消息代理將數(shù)據(jù)保存在內(nèi)存中,那么宕機重啟就仍然有問題;但另一些系統(tǒng)中的消息代理就會把消息持久化到硬盤(通常可配置)中,則就可以容忍宕機問題。如果遇到慢的消費者,就可以使用無限隊列的方式(而不是丟消息或者背壓)對沒來得及消費的數(shù)據(jù)進行緩存,當然通常來說,能夠存多少數(shù)據(jù)通常也會以配置的方式交給用戶去選擇。
使用消息代理的另外一個原因是消費者通常是異步消費的:即當發(fā)送一條消息后,生產(chǎn)者等待消息代理確認收到(緩存或者持久化)就會結(jié)束,而不會去等待這條消息最終被消費者所消費。而消息最終被消費者所消費,會發(fā)生在將來的某個時間點——大多數(shù)很快,比如幾秒內(nèi),但如果出現(xiàn)大量消息積壓時,這個時間也可能會很久。
對比消息代理和數(shù)據(jù)庫
有一些消息代理甚至能夠參與兩階段提交(使用 XA 或者 JTA,參見 實踐中的分布式事務 )。這種功能讓消息代理看起來非常像數(shù)據(jù)庫,盡管在實踐中他們有一些非常重要的區(qū)別:
- 刪除過程:數(shù)據(jù)庫會一直保存數(shù)據(jù),直到其被顯式地刪除。然而,大部分的消息代理會在消息被消費后,隱式的對其自動刪除。這種類型的消息代理并不適合對數(shù)據(jù)的長時間存儲。
- 尺寸假設(shè):由于消息代理會在消息被消費后將其刪除,因此大部分消息代理都會假設(shè)其所存數(shù)據(jù)并不是很多——所有隊列都很短。在這樣的假設(shè)下,如果由于消費者過慢而造成消息在消息代理中堆積(當內(nèi)存中存不下后可能需要放到硬盤中),則可能造成消息代理的性能降級,所有消息都需要更長時間才能被處理。
- 數(shù)據(jù)過濾:數(shù)據(jù)庫通常支持二級索引其他一些對數(shù)據(jù)進行查找的方法,而消息代理也通常會支持對某個 topic 下符合某種條件的數(shù)據(jù)進行訂閱。雖然機制不同,但在本質(zhì)上,兩者都支持客戶端讀取其所關(guān)心數(shù)據(jù)的方法。
- 數(shù)據(jù)隔離:當對數(shù)據(jù)庫進行查詢時,其結(jié)果通常是基于某個時間點的快照;換句話說,如果另外一個客戶端在其發(fā)起查詢之后插入了一些數(shù)據(jù),第一個客戶端通常是看不到這些更新的(這要“歸功于”數(shù)據(jù)庫事務的隔離級別),除非其進行再次查詢。與之相對,消息代理雖然不支持任意條件的查詢,但當數(shù)據(jù)發(fā)生變化時(新的事件到來),系統(tǒng)會將其立即告知消費者。
以上都是傳統(tǒng)視角下的消息代理,這些語義被抽象成了像 JMS 和 AMQP 之類的協(xié)議,并且為 RabbitMQ、ActiveMQ、HornetQ、Qpid、TIBCO 企業(yè)消息服務、IBM MQ、Azure Service Bus 和 Google Cloud Pub/Sub 等系統(tǒng)實現(xiàn)。
多消費者
當多個消費者同時消費一個 topic 下的數(shù)據(jù)時,有兩種主要的消費方式,
- 負載均衡(Load Balancing,互斥)
每個消息被投遞給其中一個消費者進行消費。即所有的消費者會共同處理一個 topic 下的所有消息。消息代理可能以任意策略將消息分發(fā)給不同消費者。當每條消息消費代價很高,用戶想通過增加消費者的數(shù)量來并行消費某個 topic 時,這種方式很有用。(在 AMQP 中,可以通過多個客戶端消費同一個隊列來實現(xiàn)負載均衡;在 JMS 中,這種方式被稱為共享訂閱) - 扇出(Fan-out,獨立)
每個消息都被發(fā)送到所有消費者。扇出的方式會讓每個消費者獨立的對同樣的數(shù)據(jù)進行消費,而不會互相影響。這種方式有點類似于批處理中對于同一份數(shù)據(jù)進行多次處理。(JMS 中稱為 topic subcription;AMQP 中稱為 exchange bindings)
 負載均衡和扇出模式對比
負載均衡和扇出模式對比
兩種消費模式也可以組合起來:如有兩組用戶都訂閱了某個 topic,組間進行獨立消費(fan-out)、組內(nèi)進行互斥消費(load balancing)。
確認和重傳
消費者可能會在任意時刻宕機,因此可能會出現(xiàn):消息代理將消息發(fā)送給了消費者,但是消費者卻沒有對其進行消費或者僅進行了部分消費,就宕機了。為了保證該消息不丟,消息代理使用了一種確認機制(類似 TCP 中的 ack):每個消費者必須顯式地告訴消息代理它消費完了消息,這樣消息代理才能安全的將消息從隊列中刪除。
如果消息代理和消費者之間的鏈接關(guān)閉或者超時了,消息代理仍然沒有收到確認,則會假設(shè)消息沒有被處理,并且重新給另一個消費者發(fā)送消息。但此時有可能出現(xiàn),在重發(fā)之前消息實際已經(jīng)被處理過了,只是確認消息由于網(wǎng)絡的原因丟失了。在這種情況下,需要消費者進行冪等消費。
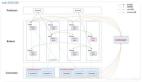
在負載均衡模式下,重傳可能會造成消費者處理消息的亂序。在下圖中,在沒有任何故障時,消費者大體是按照消息的生產(chǎn)順序來消費的。然而,某一時刻,消費者 2 號在處理消息 m3 時宕機了,此時消費者 1 號正在處理消息 m4。由于遲遲沒有等到 m3 的消費確認,消息代理將其重新發(fā)送給了消費者 1 號,從而導致消費者 1 號以 m4,m3,m5 的順序來處理的消息。即,發(fā)生了亂序處理。
 負載均衡導致的消息亂序
負載均衡導致的消息亂序
即使消息代理試圖以順序的方式給消費者發(fā)送消息(JMS 和 AMQP 都有此類規(guī)定),但由于負載均衡和重傳機制的組合,亂序消費難以避免。為了避免這個問題,你可以讓每個消費者使用單獨的隊列(即,不用負載均衡功能,也可以理解,畢竟并行總是有代價的)。在每條消息都是互相獨立時,亂序消費不是問題;但如果消息間有前后因果依賴,則消息的保序消費非常重要。
參考資料
[1]DDIA 讀書分享會: https://ddia.qtmuniao.com/