想訓練類Sora模型嗎?尤洋團隊OpenDiT實現80%加速
作為 2024 開年王炸,Sora 的出現樹立了一個全新的追趕目標,每個文生視頻的研究者都想在最短的時間內復現 Sora 的效果。
根據 OpenAI 披露的技術報告,Sora 的核心技術點之一是將視覺數據轉化為 patch 的統一表征形式,并通過 Transformer 和擴散模型結合,展現了卓越的擴展(scale)特性。在報告公布后,Sora 核心研發成員 William Peebles 和紐約大學計算機科學助理教授謝賽寧合著的論文《Scalable Diffusion Models with Transformers》就成了眾多研究者關注的重點。大家希望能以論文中提出的 DiT 架構為突破口,探索復現 Sora 的可行路徑。
最近,新加坡國立大學尤洋團隊開源的一個名為 OpenDiT 的項目為訓練和部署 DiT 模型打開了新思路。
OpenDiT 是一個易于使用、快速且內存高效的系統,專門用于提高 DiT 應用程序的訓練和推理效率,包括文本到視頻生成和文本到圖像生成。

項目地址:https://github.com/NUS-HPC-AI-Lab/OpenDiT

OpenDiT 方法介紹
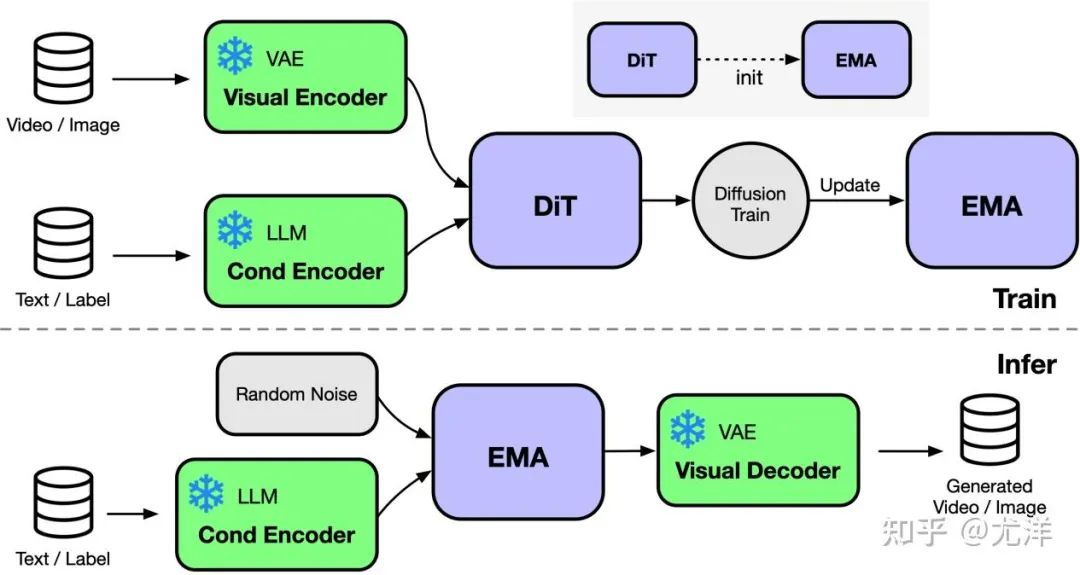
OpenDiT 提供由 Colossal-AI 支持的 Diffusion Transformer (DiT) 的高性能實現。在訓練時,視頻和條件信息分別被輸入到相應的編碼器中,作為DiT模型的輸入。隨后,通過擴散方法進行訓練和參數更新,最終將更新后的參數同步至EMA(Exponential Moving Average)模型。推理階段則直接使用EMA模型,將條件信息作為輸入,從而生成對應的結果。
圖源:https://www.zhihu.com/people/berkeley-you-yang
OpenDiT 利用了 ZeRO 并行策略,將 DiT 模型參數分布到多臺機器上,初步降低了顯存壓力。為了取得更好的性能與精度平衡,OpenDiT 還采用了混合精度的訓練策略。具體而言,模型參數和優化器使用 float32 進行存儲,以確保更新的準確性。在模型計算的過程中,研究團隊為 DiT 模型設計了 float16 和 float32 的混合精度方法,以在維持模型精度的同時加速計算過程。
DiT 模型中使用的 EMA 方法是一種用于平滑模型參數更新的策略,可以有效提高模型的穩定性和泛化能力。但是會額外產生一份參數的拷貝,增加了顯存的負擔。為了進一步降低這部分顯存,研究團隊將 EMA 模型分片,并分別存儲在不同的 GPU 上。在訓練過程中,每個 GPU 只需計算和存儲自己負責的部分 EMA 模型參數,并在每次 step 后等待 ZeRO 完成更新后進行同步更新。
FastSeq
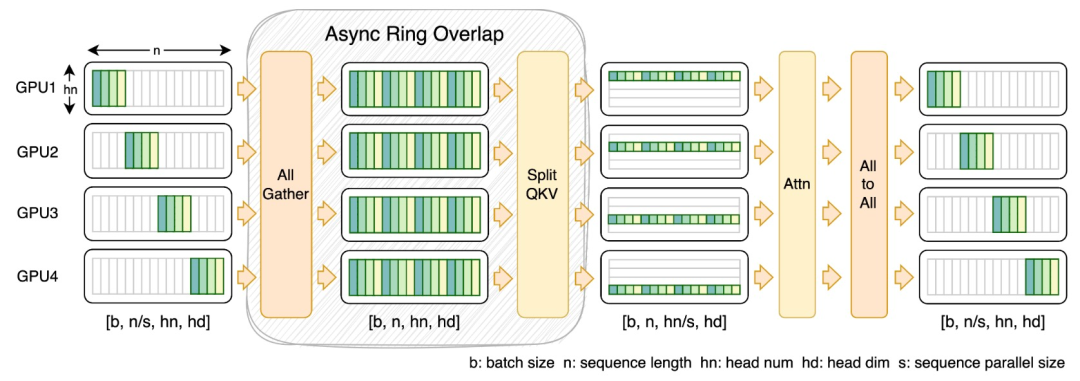
在 DiT 等視覺生成模型領域,序列并行性對于有效的長序列訓練和低延遲推理是必不可少的。
然而,DeepSpeed-Ulysses、Megatron-LM Sequence Parallelism 等現有方法在應用于此類任務時面臨局限性 —— 要么是引入過多的序列通信,要么是在處理小規模序列并行時缺乏效率。
為此,研究團隊提出了 FastSeq,一種適用于大序列和小規模并行的新型序列并行。FastSeq 通過為每個 transformer 層僅使用兩個通信運算符來最小化序列通信,利用 AllGather 來提高通信效率,并策略性地采用異步 ring 將 AllGather 通信與 qkv 計算重疊,進一步優化性能。

算子優化
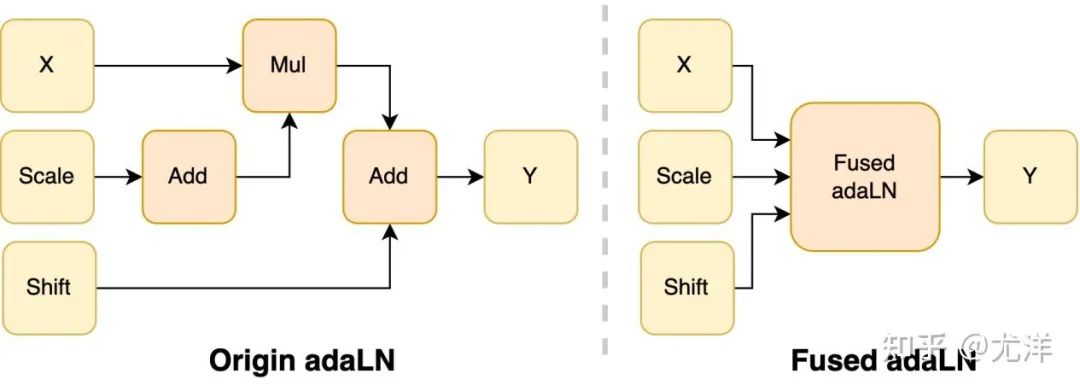
在 DiT 模型中引入 adaLN 模塊將條件信息融入視覺內容,雖然這一操作對模型的性能提升至關重要,但也帶來了大量的逐元素操作,并且在模型中被頻繁調用,降低了整體的計算效率。為了解決這個問題,研究團隊提出了高效的 Fused adaLN Kernel,將多次操作合并成一次,從而增加了計算效率,并且減少了視覺信息的 I/O 消耗。
圖源:https://www.zhihu.com/people/berkeley-you-yang
簡單來說,OpenDiT 具有以下性能優勢:
1、在 GPU 上加速高達 80%,50%的內存節省
- 設計了高效的算子,包括針對DiT設計的 Fused AdaLN,以及 FlashAttention、Fused Layernorm 和HybridAdam。
- 采用混合并行方法,包括 ZeRO、Gemini 和 DDP。對 ema 模型進行分片也進一步降低了內存成本。
2、FastSeq:一種新穎的序列并行方法
- 專為類似 DiT 的工作負載而設計,在這些應用中,序列通常較長,但參數相比于 LLM 較小。
- 節點內序列并行可節省高達 48% 的通信量。
- 打破單個 GPU 的內存限制,減少整體訓練和推理時間。
3、易于使用
- 只需幾行代碼的修改,即可獲得巨大的性能提升。
- 用戶無需了解分布式訓練的實現方式。
4、文本到圖像和文本到視頻生成完整 pipeline
- 研究人員和工程師可以輕松使用 OpenDiT pipeline 并將其應用于實際應用,而無需修改并行部分。
- 研究團隊通過在 ImageNet 上進行文本到圖像訓練來驗證 OpenDiT 的準確性,并發布了檢查點(checkpoint)。
安裝與使用
要使用 OpenDiT,首先要安裝先決條件:
- Python >= 3.10
- PyTorch >= 1.13(建議使用 >2.0 版本)
- CUDA >= 11.6
建議使用 Anaconda 創建一個新環境(Python >= 3.10)來運行示例:
conda create -n opendit pythnotallow=3.10 -y
conda activate opendit安裝 ColossalAI:
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAI
git checkout adae123df3badfb15d044bd416f0cf29f250bc86
pip install -e .安裝 OpenDiT:
git clone https://github.com/oahzxl/OpenDiTcd OpenDiT
pip install -e .(可選但推薦)安裝庫以加快訓練和推理速度:
# Install Triton for fused adaln kernel
pip install triton
# Install FlashAttention
pip install flash-attn
# Install apex for fused layernorm kernel
git clone https://github.com/NVIDIA/apex.gitcd apex
git checkout 741bdf50825a97664db08574981962d66436d16a
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"圖像生成
你可以通過執行以下命令來訓練 DiT 模型:
# Use script
bash train_img.sh# Use command line
torchrun --standalone --nproc_per_node=2 train.py \
--model DiT-XL/2 \
--batch_size 2默認禁用所有加速方法。以下是訓練過程中一些關鍵要素的詳細信息:
- plugin: 支持 ColossalAI、zero2 和 ddp 使用的 booster 插件。默認是 zero2,建議啟用 zero2。
- mixed_ precision:混合精度訓練的數據類型,默認是 fp16。
- grad_checkpoint: 是否啟用梯度檢查點。這節省了訓練過程的內存成本。默認值為 False。建議在內存足夠的情況下禁用它。
- enable_modulate_kernel: 是否啟用 modulate 內核優化,以加快訓練過程。默認值為 False,建議在 GPU < H100 時啟用它。
- enable_layernorm_kernel: 是否啟用 layernorm 內核優化,以加快訓練過程。默認值為 False,建議啟用它。
- enable_flashattn: 是否啟用 FlashAttention,以加快訓練過程。默認值為 False,建議啟用。
- sequence_parallel_size:序列并行度大小。當設置值 > 1 時將啟用序列并行。默認值為 1,如果內存足夠,建議禁用它。
如果你想使用 DiT 模型進行推理,可以運行如下代碼,需要將檢查點路徑替換為你自己訓練的模型。
# Use script
bash sample_img.sh# Use command line
python sample.py --model DiT-XL/2 --image_size 256 --ckpt ./model.pt視頻生成
你可以通過執行以下命令來訓練視頻 DiT 模型:
# train with scipt
bash train_video.sh# train with command line
torchrun --standalone --nproc_per_node=2 train.py \
--model vDiT-XL/222 \
--use_video \
--data_path ./videos/demo.csv \
--batch_size 1 \
--num_frames 16 \
--image_size 256 \
--frame_interval 3
# preprocess
# our code read video from csv as the demo shows
# we provide a code to transfer ucf101 to csv format
python preprocess.py使用 DiT 模型執行視頻推理的代碼如下所示:
# Use script
bash sample_video.sh# Use command line
python sample.py \
--model vDiT-XL/222 \
--use_video \
--ckpt ckpt_path \
--num_frames 16 \
--image_size 256 \
--frame_interval 3DiT 復現結果
為了驗證 OpenDiT 的準確性,研究團隊使用 OpenDiT 的 origin 方法對 DiT 進行了訓練,在 ImageNet 上從頭開始訓練模型,在 8xA100 上執行 80k step。以下是經過訓練的 DiT 生成的一些結果:

損失也與 DiT 論文中列出的結果一致:

要復現上述結果,需要更改 train_img.py 中的數據集并執行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \
--model DiT-XL/2 \
--batch_size 180 \
--enable_layernorm_kernel \
--enable_flashattn \
--mixed_precision fp16感興趣的讀者可以查看項目主頁,了解更多研究內容。