













在軟件項目中,開發人員往往會盡力搜尋各種數據庫優化技術,尤其是那些能夠提高大型數據庫查詢效率的技術。在傳統的SQL數據庫中,我們通常只能使用“B樹索引”或簡單的“索引”等關鍵詞,來查找各種博客或文章信息。不過,這種基于關鍵字的方法可能會忽略掉那些使用了諸如:“SQL調整”或“索引策略”等不同、但屬于相關短語的重要內容。
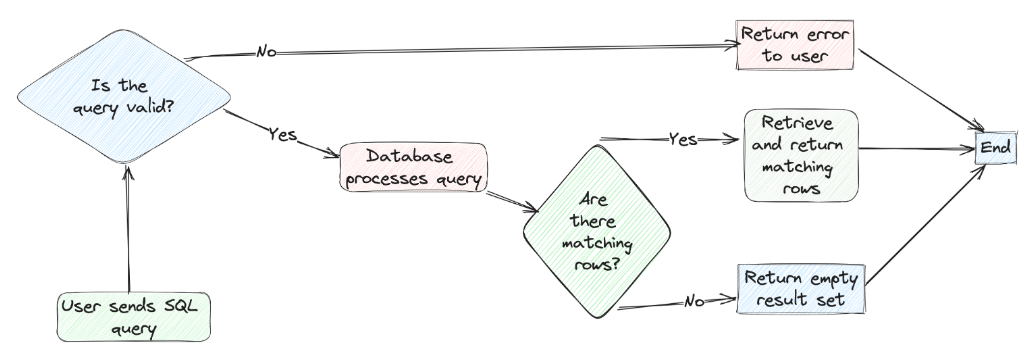
另一種情況是,應用可能知道上下文,但不知道特定技術的確切名稱。因此,對于依賴精確的關鍵詞匹配的傳統數據庫而言,應用是無法僅根據上下文來進行查詢的。
對此,我們需要一種超越簡單關鍵詞匹配查詢的技術,能夠根據語義相似性,以提供查詢結果。這便是向量查詢(Vector Search)能夠發揮作用的地方。與傳統的關鍵字匹配技術不同,向量查詢會將待查詢的語義與數據庫條目進行比較,從而返回更為相關、更加準確的結果。下面,我們將從基本概念開始,討論與向量查詢相關的技術與使用案例。
向量查詢概述
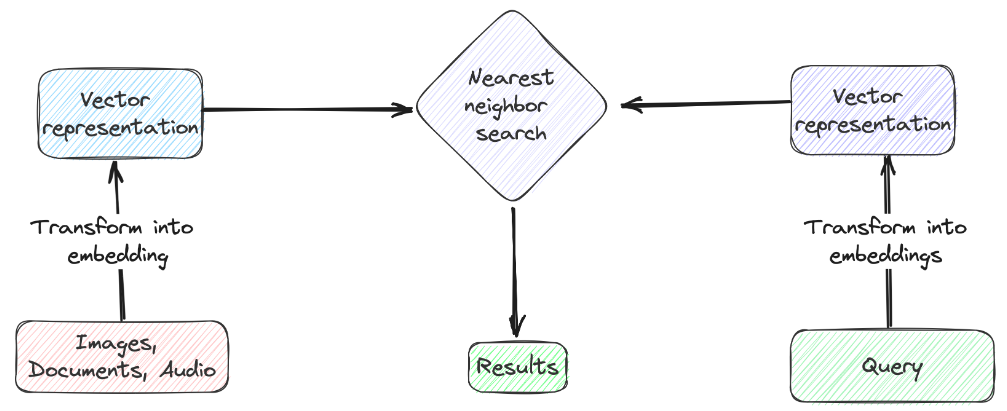
向量查詢是一種復雜的數據檢索技術,它側重于查詢與數據條目相關的上下文含義,而并非簡單的文本匹配。要實現這種技術,我們必須首先將查詢和數據集的特定列轉換為數字的表示,即向量嵌入(Vector Embeddings)。據此,我們可以計算查詢向量與數據庫中的向量嵌入之間的距離(即:余弦相似度或歐氏距離)。接下來,我們根據計算出的距離,找出最接近或最相似的條目。最終,我們能夠返回與查詢向量距離最小的前k個結果。下圖展示了整個流程:
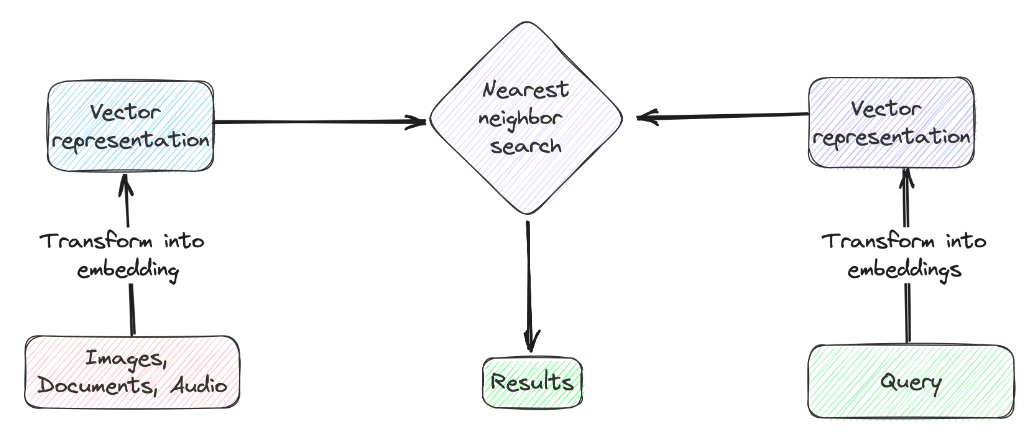
向量查詢的典型場景
- 似性查詢:被用于在特征空間中查找與給定向量相似的其他向量,常被廣泛地應用于圖像、音頻和文本的分析等領域。
- 推薦系統:通過分析用戶和項目的向量表示,來實現針對電影、產品或音樂等領域的個性化的推薦。
- 自然語言處理:通過查詢文本數據中的語義相似性,來支持語義查詢和相關性分析。
- 問答(Question-Answering,QA)系統:查詢各種向量表示與輸入問題最相似的相關段落。其最終答案可以根據問題和檢索到的段落,通過大語言模型(LLM)來生成。
當數據集較小且查詢簡單時,暴力向量(Brute-force Vector)式查詢在語義查詢方面的效果非常好。不過,隨著數據集的擴大、以及查詢變得越來越復雜,其性能可能會下降,進而產生各種偏差。
實施向量查詢的挑戰
讓我們來討論一下與使用簡單向量查詢相關的一些問題,特別是當數據集規模持續增大時:
- 性能:如前所述,暴力向量查詢會計算查詢向量與數據庫中所有向量之間的距離。對于較小的數據集來說,這種方法效果很好,但是當向量的數量增加到上百萬個條目時,查詢的時間和查找數百萬個條目之間距離的計算成本,就會增加。
- 可擴展性:目前,數據正在呈指數級增長,因此在查詢海量數據集時,暴力向量查詢很難達到同樣的速度和準確性。這就需要通過創新的方法來管理海量數據,同時保持同樣的速度和準確性。
- 與結構化數據相結合:在簡單的應用中,我們要么使用SQL來查詢結構化數據,要么使用向量查詢來查找非結構化數據。而在處理不同的系統時,我們需要整合這兩種技術。也就是說,當我們既使用向量查詢,又應用SQL的Where子句進行過濾時,處理查詢的時間會因數據種類和大小的增多而增加。
常見的向量索引技術
為了應對大規模向量數據的挑戰,我們可以采用如下索引技術,來組織和促進高效的近似向量查詢。
HNSW(Hierarchical Navigable Small World)
HNSW算法利用多層次的圖形結構,來實現高效的向量查詢和存儲。在每一層上,向量不僅與同層的其他向量相連,還與下面各層的向量相連。這種結構既能夠有效地探索到附近的向量,又可以保持查詢空間的可管理性。通常,頂層包含了少量節點,隨著層級的下降,節點數量呈指數增長。而在最底層處包含了數據庫中的所有數據點。如下圖所示,這種分層設計定義了HNSW算法的獨特架構。
具體的查詢過程會從一個選定的向量開始,并由此計算與當前層和之前層的連接向量的距離。這種方法屬于貪婪型(Greedy),即:不斷向距離當前位置最近的向量前進,直到在所有連接向量中找到最接近的向量為止。雖然HNSW索引通常在直接向量查詢中表現出色,但它需要相當多的資源和大量時間來進行構建。此外,在大多數條件下,由于圖形的連通性降低,其過濾查詢的準確性和效率也會大幅下降。
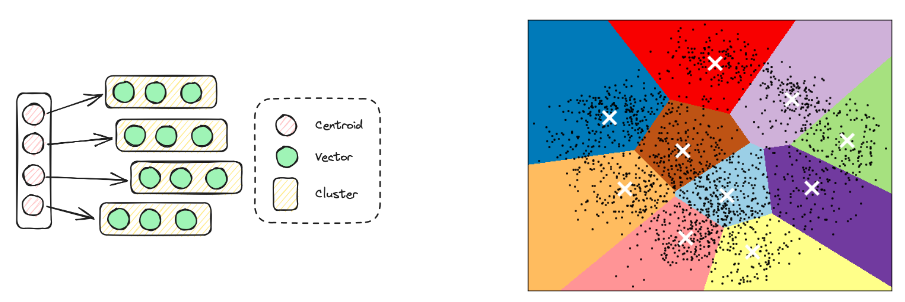
反向向量文件(Inverted Vector File,IVF)索引
IVF索引會使用簇中心點作為其反轉索引,從而有效地管理各種高維數據的查詢。通常,它會根據幾何鄰近性,將向量劃分為若干簇(Cluster),并將每個簇的中心點作為簡化表示。在查詢那些與查詢向量最相似的項目時,該算法首先會識別與查詢最接近的中心點。然后,它只在相關的向量列表中查詢這些中心點,而不是整個數據集。與HSNW相比,IVF的構建時間更短,但查詢過程中的準確率和速度則更低。
MyScale解決方案及其實際應用
作為一種SQL向量數據庫,MyScale旨在處理復雜的查詢,實現快速的數據檢索,并有效地存儲大量數據。不同于其他專業向量數據庫,它能夠將快速的SQL執行引擎(基于ClickHouse)與專有的多尺度樹圖(Multi-scale Tree Graph,MSTG)算法相結合。由于MSTG結合了基于樹和圖的算法優勢,因此MyScale能夠快速構建和查詢,并在不同的過濾查詢比例下,既能保持速度和準確性,又能保持資源和成本效率。
下面,讓我們來看看MyScale可以在哪些實際應用中發揮巨大的作用:
- 基于知識的QA應用:在開發問答(QA)系統時,作為一個理想的向量數據庫,MyScale具有自查詢功能和靈活的過濾功能,可以從文件中獲取高度相關的結果。此外,MyScale還具有出色的可擴展性,可以同時管理多個用戶。若您想了解更多信息,可以從其相關文檔中獲得幫助。此外,您還可以利用其帶有高級算法的自查詢,來提高查詢結果的準確性和速度。
- 大型AI聊天機器人:開發大型聊天機器人是一項極具挑戰性的任務,尤其是當您必須同時管理眾多用戶,并需要對他們區別對待時。鑒于聊天機器人需要提供準確的答案,MyScale可以通過與SQL兼容的、基于角色的訪問控制,來簡化聊天機器人的構建,并通過數據分區和過濾查詢,來實現對大規模租戶的管理。
- 圖像查詢:如果您正在創建一個可執行語義查詢或類似圖像查詢的系統,MyScale可以在保持高性能和資源效率的同時,輕松滿足不斷增長的圖像數據需求。此外,您也可以編寫更為復雜的SQL和向量連接查詢,來根據元數據或視覺內容去匹配圖像。更多詳細信息,請參閱與圖像查詢相關的項目文檔。
除了上述實際應用之外,通過結合MyScale的SQL和向量功能,您還可以開發出高級的推薦系統、以及對象檢測應用等。
小結
綜上所述,向量查詢可以通過解釋嵌入中向量中的語義,超越傳統的術語匹配。這種方法不僅對文本有效,也可以擴展到圖像、音頻、以及各種多模態的非結構化數據中。其中,最典型的莫過于ImageBind (https://ai.meta.com/blog/imagebind-six-modalities-binding-ai/)等模型。當然,這項技術也面臨著計算、存儲需求、以及高維向量語義模糊性等挑戰。
而MyScale可以通過將SQL和向量查詢創新式地融合到一個統一、高性能、高性價比的系統中,從而滿足了從問答系統到AI聊天機器人、以及圖像查詢等廣泛應用的多功能性和高效性。
作者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。
原文標題:What Is Vector Search?,作者:Usama Jamil
原文鏈接:https://dzone.com/articles/what-is-vector-search
























