線程使用越多程序越快?別瞎整
當運行 CPU 密集型的并行程序時,通常希望將線程或進程池的大小設置為計算機上的 CPU 核數(shù)量,但有沒有考慮過是否真的是核數(shù)用的越多并行程序越快?
理論上線程過少,無法充分利用所有核心,線程過多,程序會因為多個線程爭奪同一核心而變得運行緩慢。
事實上,確定要運行多少個線程沒那么容易:
- Python 標準庫提供了多個獲取此信息的 API,但沒有一個是恰當?shù)模ㄉ院髸e例)
- 由于 CPU 具有指令級并行性和同時多線程等功能(在英特爾 CPU 上稱為超線程),可以有效使用的核心數(shù)量取決于編寫的代碼

從 Python 獲取 CPU 內核數(shù)
前述提到在Python中獲取內核數(shù)的API是不準確的,為啥這么說,我們看個例子
Python提供 os.cpu_count() 函數(shù),可以返回 "系統(tǒng)中邏輯 CPU 的數(shù)量",文檔說明 "len(os.sched_getaffinity(0))可以獲取當前進程調用線程受限的邏輯 CPU 數(shù)量",調度器親和性是一種限制進程使用特定內核的方法。
遺憾的是,這個 API 也不夠恰當,例如使用Docker在創(chuàng)建容器時人為限制CPU數(shù)量,比如將 CPU 限制為2.25 個內核:
$ docker run -i -t --cpus=2.25 python:3.12-slim
Python 3.12.1 (main, Dec 9 2023, 00:21:37) [GCC 12.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import os
>>> os.cpu_count()
20
>>> len(os.sched_getaffinity(0))
20在Docker中只提供了2.25個內核資源,但顯然調用Python API時返回的數(shù)量仍不對。
說完這個問題,還需要先了解物理和邏輯 CPU 內核是什么再進入正題。
物理與邏輯 CPU內核
以英特爾 i7-12700K 處理器為例,它具有:
- 12 個物理內核(8 個高性能內核和 4 個性能較弱的內核)
- 20 個邏輯內核
現(xiàn)代 CPU 內核可以并行執(zhí)行多條指令,但如果 CPU 在等待從 RAM 中加載某些數(shù)據時卡住了,會發(fā)生什么情況?在此之前,它可能無法執(zhí)行任何工作。
為了充分利用這些可能被浪費的資源,CPU 物理內核的計算資源可以作為多個內核向操作系統(tǒng)公開。在這臺電腦上,8 個高性能內核中的每一個都可以作為兩個內核公開,總共有 16 個邏輯內核。成對的邏輯內核將共享單個物理內核的計算資源,例如,如果一個邏輯內核沒有充分利用所有內部算術邏輯單元,比如因為它在等待內存加載,那么通過配對邏輯內核運行的代碼仍然可以使用這些閑置資源。
這種技術被稱為同步多線程技術,英特爾稱之為超線程技術。如果你有一臺電腦,通常可以在 BIOS 中禁用它。
這種解釋非常不準確,而且不同型號的 CPU,即使是同一制造商生產的 CPU,實際執(zhí)行情況也不盡相同。不過,邏輯內核與物理內核并不完全相同的一般意義足以滿足這篇文章要表達的目的。
現(xiàn)在又有了一個新問題,拋開調度器親和性等因素不談,我們應該使用物理內核數(shù)還是邏輯內核數(shù)作為線程池大小?
示例
在該例中,用 Numba 將兩個函數(shù)編譯成機器代碼,確保釋放 GIL 以實現(xiàn)并行。
這兩個函數(shù)做的事情一毛一樣,但slow_threshold特意寫成比較慢的方式而fast_threshold則更快(感興趣的可以對比學習下為何另一個更快,很簡單)。現(xiàn)在可以在多個線程上并行運行這些函數(shù),在大多數(shù)人眼里,只需并行處理更多圖像,就能線性提高吞吐量,直到內核耗盡,先從單核上進行測試:
from numba import njit
import numpy as np
@njit(nogil=True)
def slow_threshold(img, noise_threshold):
noise_threshold = img.dtype.type(noise_threshold)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
result[i, j] = img[i, j] // 256
for i in range(result.shape[0]):
for j in range(result.shape[1]):
if result[i, j] < noise_threshold // 256:
result[i, j] = 0
return result
@njit(nogil=True)
def fast_threshold(img, noise_threshold):
noise_threshold = np.uint8(noise_threshold // 256)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
value = img[i, j] >> 8
value = (
0 if value < noise_threshold else value
)
result[i, j] = value
return result
rng = np.random.default_rng(12345)
def make_image(size=256):
noise = rng.integers(0, high=1000, size=(size, size), dtype=np.uint16)
signal = rng.integers(0, high=5000, size=(size, size), dtype=np.uint16)
# A noisy, hard to predict image:
return noise | signal
NOISY_IMAGE = make_image()
assert np.array_equal(
slow_threshold(NOISY_IMAGE, 1000),
fast_threshold(NOISY_IMAGE, 1000)
)借助timeit測試單核上運行每個功能的性能,結果如下:
%timeit slow_threshold(NOISY_IMAGE, 1000)
# 90.6 μs ± 77.7 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)%timeit fast_threshold(NOISY_IMAGE, 1000)
# 24.6 μs ± 10.8 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)結果如前所述,確實fast_threshold表現(xiàn)更好。
并行化示例
現(xiàn)在我們使用線程池處理上述函數(shù):
from multiprocessing.dummy import Pool as ThreadPool
def apply_in_thread_pool(
num_threads, function, images
):
with ThreadPool(num_threads) as pool:
result = pool.map(
lambda img: function(img, 1000),
images,
chunksize=10
)
assert len(result) == len(images)借助benchit繪制不同線程數(shù)運行不同函數(shù)所需的時間圖:
import benchit
benchit.setparams(rep=1)
# 4000 images to run through the pool:
IMAGES = [make_image() for _ in range(4000)]
def slow_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, slow_threshold, IMAGES)
def fast_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, fast_threshold, IMAGES)
# Measure the two functions with 1 to 24 threads:
timings = benchit.timings(
[slow_threshold_in_pool, fast_threshold_in_pool],
range(1, 25),
input_name="Number of threads"
)
timings.plot(logy=True, logx=False)繪制的圖片如下:
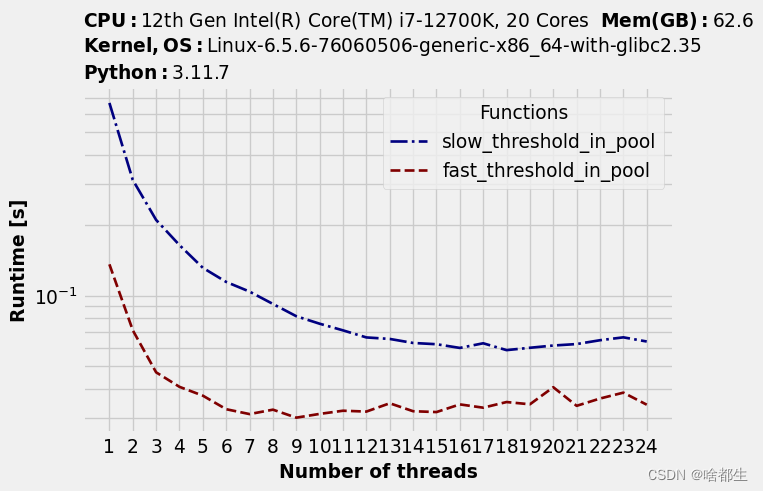
可以注意到隨著線程數(shù)變多,運行時間先是有明顯下降,但到一定程度后無明顯改進,且另一個發(fā)現(xiàn)是每個函數(shù)的最佳線程數(shù)不同:
timings.to_dataframe().idxmin(axis="rows")Functions | Optimal number of threads |
slow_threshold | 19 |
fast_threshold | 9 |
slow_threshold函數(shù)基本上可以利用所有邏輯內核,單線程可能無法充分利用特定物理內核的所有可用處理能力,因此邏輯內核允許更多并行性。
相比之下,fast_threshold函數(shù)使用超過 9 個內核后,速度就開始減慢。可能遇到計算以外的瓶頸,比如內存帶寬。
總結
- 考慮到操作系統(tǒng)限制 CPU 使用的所有不同方式,很難獲得準確的內核數(shù)量
- 最佳并行程度(如線程數(shù))取決于工作量
- 內核數(shù)量并不是唯一的瓶頸
如果有一個長期運行的數(shù)據處理任務,需要在多個線程中運行相同的代碼一段時間,通常也值得這樣做,花一點時間根據經驗測算出最佳線程數(shù)。