13個優秀開源語音識別引擎
語音識別(ASR)在人機交互方面發揮著重要的作用,可用于:轉錄、翻譯、聽寫、語音合成、關鍵字定位、語音日記、語言增強等場景。語音識別基本過程一般包括:分析音頻、音頻分解、格式轉換、文本匹配,但實際的語音識別系統可能會更復雜,并且可能包括其他步驟和功能組件,例如:噪聲抑制、聲學模型、語言模型和置信度評估等。
多年來,語音識別技術的進步令人印象深刻,我們可以使用語音識別技術實現智能家居、控制汽車實現自動駕駛、與ChatGPT等大模型對接進行對話、智能音箱、居家機器人等等。這些年來也因為自然語言處理、語音識別等技術的發展,誕生了很多優秀的公司,例如:訊飛**。
隨著AI技術發展,越來越多的人或組織投入到語音識別相關領域的研究,也促進了該領域的開源項目蓬勃發展。開源項目往往更加易于定制化開發、使用成本更低、透明,并且可私有化部署,數據安全可控。這使得開源語音識別引擎在應用開發中越來越受到技術人員的青睞。
2024年已開始,AI熱度不減,以下是幾個截止目前比較優秀的開源語音識別引擎。
1.Whisper
源碼:https://github.com/openai/whisper
官網:https://openai.com/research/whisper
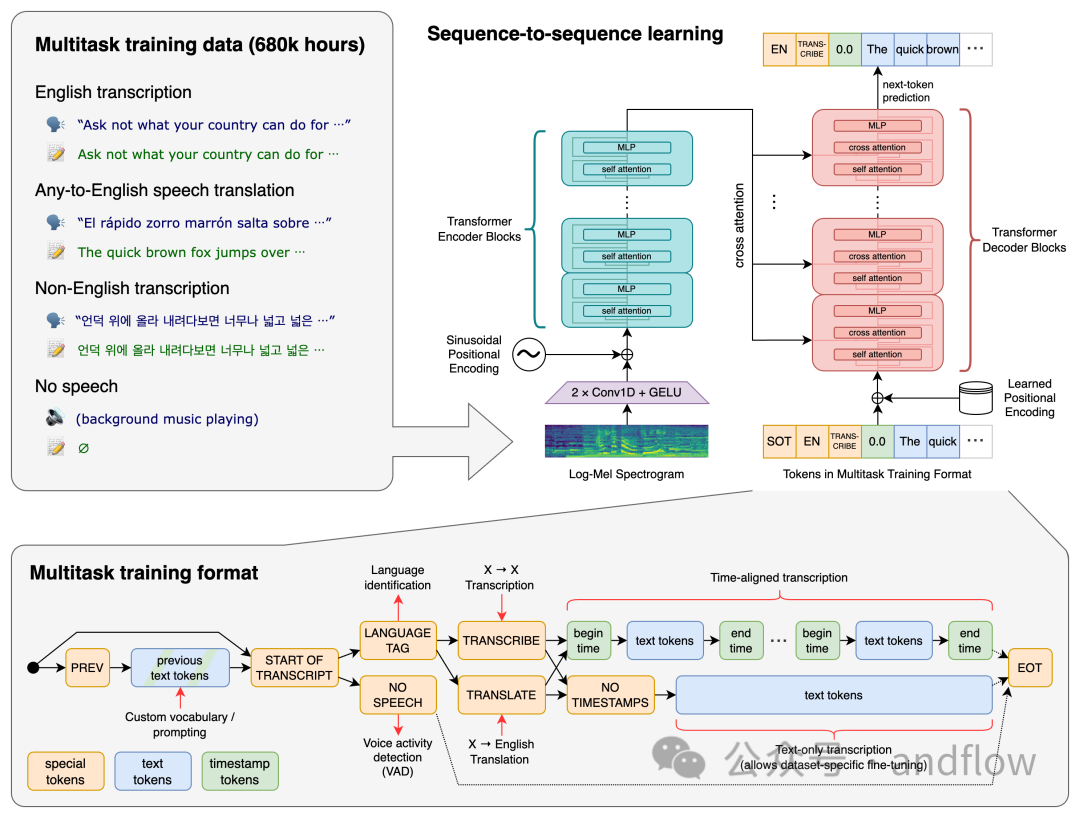
Whisper是Open AI的創意工具,提供了轉錄和翻譯服務。該AI工具于2022年9月發布,是最準確的自動語音識別模型之一。它從市場上的其他工具中脫穎而出,因為它訓練了大量的訓練數據集:來自互聯網的68萬小時的音頻文件。這種多樣化的數據范圍提高了該工具的魯棒性。
用Whisper進行轉錄必須先安裝Python或命令行界面。他提供了五種型號的模型,所有型號都具有不同的大小和功能。這些包括微小、基本、小型、中型和大型。模型越大,轉錄速度越快。盡管如此,你必須要有一個好的CPU和GPU設備,才能最大限度發揮它們的性能。
與精通LibriSpeech性能(最常見的語音識別基準之一)的模型相比還是有差距,但是,它的零樣本性能表現優異,API的錯誤比相同的模型少50%。
優點:
- 它支持的內容格式,如MP3,MP4,M4A,Mpeg,MPGA,WEBM和WAV。
- 它可以轉錄99種語言,并將它們全部翻譯成英語。
- 該工具是免費使用的。
缺點:
- 模型越大,消耗的GPU資源就越多,這可能會很昂貴。
- 這將花費您的時間和資源來安裝和使用該工具。
- 它不提供實時語音轉錄功能。
2.Project DeepSpeech
源碼:https://github.com/mozilla/DeepSpeech
Project DeepSearch是Mozilla的一個開源語音轉文本引擎。此語音轉文本命令和庫在Mozilla公共許可證(MPL)下發布。它的模型參考的是百度深度語音研究論文,具有端到端的可訓練性,并支持多種語言音頻轉錄。它使用Google的TensorFlow進行訓練和實現。
從GitHub下載源代碼,并將其安裝到您的Python中以使用它。該工具已經在英語模型上進行了預訓練。但是,您仍然可以使用您的數據訓練模型。或者,您可以獲得一個預先訓練的模型,并使用自定義數據對其進行改進。
優點:
- DeepSpeech很容易定制,因為它是一個原生代碼解決方案。
- 它為Python、C、.Net Framework和JavaScript提供了開發包,不管哪一個開發語言,都可以使用該工具。
- 它可以在各種小設備上運行,包括Raspberry Pi設備。
- 它的每字錯誤率非常低,為7.5%。
- Mozilla對隱私問題采取了嚴肅的態度。
缺點:
- 據報道,Mozilla將終止DeepSpeech的開發。這意味著在出現錯誤和實現問題時將提供更少的支持。
3.Kaldi
源碼:https://github.com/kaldi-asr/kaldi

Kaldi是專門為語音識別的研究人員創建的語音識別工具。它是用C++編寫的,并在Apache 2.0許可證下發布,這是限制最少的開源許可。與Whisper和DeepSpeech等專注于深度學習的工具不同,Kaldi主要專注于使用老式可靠工具的語音識別模型。這些模型包括隱馬爾可夫模型(Hidden Markov Models)、高斯混合模型(Gaussian Mixture Models)和有限狀態傳感器(Finite State Transducers)。
優點:
- Kaldi非常可靠。它的代碼經過徹底驗證。
- 雖然它的重點不是深度學習,但它有一些模型可以實現轉錄服務。
- 它非常適合學術和行業相關的研究,允許用戶測試他們的模型和技術。
- 它有一個活躍的論壇,提供適量的支持。
- 還有一些資源和文檔可以幫助用戶解決任何問題。
- 作為開源,有隱私或安全問題的用戶可以檢查代碼以了解它是如何工作的。
缺點:
- 它使用傳統的模型方法可能會限制其準確性水平。
- Kaldi不是用戶友好的,因為它只是在命令行界面上運行。
- 它使用起來相當復雜,適合有技術經驗的用戶。
- 你需要大量的計算能力來使用這個工具包。
4.SpeechBrain
源碼:https://github.com/speechbrain/speechbrain
SpeechBrain是一個用于促進語音相關技術的研究和開發的開源工具包。它支持各種任務,包括:語音識別、增強、分離、說話日志和麥克風信號處理等。Speechbrain使用PyTorch作為開發框架。開發人員和研究人員可以從Pytorch的生態系統和支持中受益,以構建和訓練神經網絡。
優點:
- 用戶可以選擇傳統的或者基于深度學習的ASR模型。
- 很容易定制模型以適應您的需求。
- 它與Pytorch的集成使其更易于使用。
- 用戶可以使用預訓練模型來開發語音轉文本的任務。
缺點:
- SpeechBrain的文檔不像Kaldi的文檔那么廣泛。
- 它的預訓練模型是有限的。
- 您可能需要特殊的專業知識來使用該工具。沒有它,你可能需要經歷一個陡峭的學習曲線。
5.Coqui
源碼:https://github.com/coqui-ai/STT
Coqui是一個先進的深度學習工具包,非常適合培訓和部署stt模型。根據Mozilla公共許可證2.0授權,您可以使用它生成多個轉錄本,每個轉錄本都有一個置信度分數。它提供了預先訓練的模型以及示例音頻文件,您可以使用這些文件來測試引擎并幫助進行進一步的微調。此外,它有非常詳細的文檔和資源,可以幫助您使用和解決任何出現的問題。
優點:
- 它提供的STT模型經過高質量數據的高度訓練。
- 模型支持多種語言。
- 有一個友好的支持社區,您可以在那里提出問題并獲得與STT相關的任何細節。
- 它支持實時轉錄,延遲極低,以秒計。
- 開發人員可以根據各種用例自定義模型,從轉錄到充當語音助手。
缺點:
Coqui已經停止維護STT項目,專注于他們的文本到語音工具包。這意味著您可能需要自己解決任何問題。
6.Julius
源碼:https://github.com/julius-speech/julius

Julius是一個古老的語音轉文本項目,起源于日本,最早可以追溯到1997年。它是在BSD-3許可證下發布。它主要支持日語ASR,但作為一個獨立于語言的程序,該模型可以理解和處理多種語言,包括英語,斯洛文尼亞語,法語,泰語等。轉錄的準確性在很大程度上取決于您是否擁有正確的語言和聲學模型。該項目是用C語言編寫的,支持在Windows,Linux,Android和macOS系統中運行。
優點:
- Julius可以執行實時語音到文本的轉錄,內存占用率低。
- 它有一個活躍的社區,可以幫助解決ASR問題。
- 用英語訓練的模型可以在網上下載。
- 它不需要訪問互聯網進行語音識別,因此適合重視隱私的用戶。
缺點:
- 像任何其他開源程序一樣,您需要具有技術經驗的用戶才能使其工作。
- 它有一個巨大的學習曲線。
7.Flashlight ASR
源碼:https://github.com/flashlight/wav2letter
Flashlight ASR是由Facebook AI研究團隊設計的開源語音識別工具包。它擁有處理大型數據集的能力,速度和效率非常突出。可以將速度歸功于其在語言建模、機器翻譯和語音合成中僅使用卷積神經網絡。
在理想情況下,大多數語音識別引擎使用卷積和遞歸神經網絡來理解和建模語言。然而,遞歸網絡可能需要高計算能力,從而影響引擎的速度。
Flashlight ASR使用C++編譯,支持在CPU和GPU上運行。
優點:
- 它是最快的語音轉文本系統之一。
- 您可以將其用于各種語言和方言。
- 該模型不會消耗大量的GPU和CPU資源。
缺點:
- 它不提供任何預先訓練的語言模型,包括英語。
- 你需要有深厚的編碼專業知識來操作這個工具。
- 對于新用戶來說,它有一個陡峭的學習曲線。
8.PaddleSpeech
源碼:https://github.com/PaddlePaddle/Paddle
PaddleSpeech是個開源的語音轉文本工具包,可以在Paddlepaddle平臺上使用,該工具在Apache 2.0許可下開源。PaddleSpeech是功能最多的工具包之一,能夠執行語音識別、語音到文本轉換、關鍵字定位、翻譯和音頻分類。它的轉錄質量非常好,贏得了NAACL2022最佳演示獎。
該語音轉文本引擎支持多種語言模型,但優先考慮中文和英文模型。特別是中文模型,具有較為規范的文本和發音,使其適應中文語言的規則。
優點:
- 該工具包提供使用市場上最好的技術的高端和超輕型型號。
- 語音轉文本引擎提供了命令行和服務器選項,使其易于使用。
- 這對于開發人員和研究人員來說都是非常方便的。
- 它的源代碼是用最常用的語言之一Python編寫的。
缺點:
- 它的重點是中文資源,因此在支持其他語言方面存在一些限制。
- 它有一個陡峭的學習曲線。
- 您需要具備一定的專業知識來集成和使用該工具。
9.OpenSeq2Seq
源碼:https://github.com/NVIDIA/OpenSeq2Seq
OpenSeq2Seq正如它的名字一樣,是一個開源的語音轉文本工具包,可以幫助訓練不同類型的序列到序列模型。該工具包由Nvidia開發,在Apache 2.0許可證下發布,這意味著它對所有人都是免費的。它訓練執行轉錄,翻譯,自動語音識別和情感分析任務的語言模型。
可以根據自己的需求,使用默認預訓練模型或者訓練自己的模型。OpenSeq2Seq在使用多個顯卡和計算機時可以達到最佳性能。它在Nvidia驅動的設備上工作得最好。
優點:
- 該工具具有多種功能,使其非常通用。
- 它可以與最新的Python,TensorFlow和CUDA版本一起使用。
- 開發人員和研究人員可以訪問該工具,進行協作并進行創新。
- 對使用Nvidia驅動設備的用戶有利。
缺點:
- 由于其并行處理能力,可能消耗大量的計算機資源。
- 隨著Nvidia暫停項目開發,社區支持隨著時間的推移而減少。
- 對于沒有Nvidia硬件的用戶可能不是很有利。
10.Vosk
源碼:https://github.com/alphacep/vosk-api
官網:https://alphacephei.com/vosk/
Vosk是最緊湊、最輕量級的語音轉文本引擎之一。這個開源工具包可以在多種設備上離線運行,包括:Android、iOS和Raspberry Pi。它支持20多種語言或方言,包括:英語、中文、葡萄牙語、波蘭語、德語等。
Vosk提供了小型語言模型,不占用太多空間,理想情況下,大約只有50MB。然而,一些大型模型可以占用高達1.4GB。該工具響應速度快,可以連續將語音轉換為文本。
優點:
- 支持各種編程語言開發,如Java、Python、C++、Kotlyn和Shell等等。
- 它有各種各樣的用例,從傳輸到開發聊天機器人和虛擬助手。
- 具有快速的響應時間。
缺點:
- 引擎的準確性可能會因語言和口音而出現差異。
- 您需要開發專業知識來集成、使用該工具。
11.Athena
源碼:https://github.com/athena-team/athena
Athena是一個基于序列到序列的語音轉文本開源引擎,在Apache 2.0開源許可下發布。該工具包適合研究人員和開發人員的端到端語音處理需求。模型可以處理的任務包括:自動語音識別(ASR)、語音合成、語音檢測和關鍵字定位等。所有語言模型都基于TensorFlow實現,使更多開發人員可以訪問該工具包。
優點:
- Athena用途廣泛,從轉錄服務到語音合成。
- 它不依賴于Kaldi,因為它有自己的Python特征提取器。
- 該工具維護良好,并且定期更新。
- 它是開源的,免費使用,可供各種用戶使用。
Cons缺點:
- 它對新用戶有比較陡峭的學習曲線。
- 雖然它有一個WeChat群組來提供社區支持,但它將訪問權限限制為只有那些可以訪問該平臺的人。
12.ESPnet
源碼:https://github.com/espnet/espnet

ESPnet是一個基于Apache 2.0許可證發布的開源語音轉文本軟件,它提供端到端語音處理功能,涵蓋了ASR、翻譯、語音合成、增強和日志化等任務。該工具包采用Pytorch作為其深度學習框架,并遵循Kaldi數據處理風格。因此,您可以獲得各種語言處理任務的全面配方。該工具支持多語言。可以將其與現成的預訓練模型一起使用,或根據需求創建自己的模型。
優點:
- 與其他語音轉文本軟件相比,該工具包具備出色的性能。
- 它可以實時處理音頻,使其適合現場語音轉錄。
- 適合研究人員和開發人員使用。
- 它是提供各種語音處理任務的最通用工具之一。
缺點:
- 對于新用戶來說,集成和使用它可能很復雜。
- 您必須熟悉Pytorch和Python才能運行該工具包。
13.Tensorflow ASR
源碼:https://github.com/TensorSpeech/TensorFlowASR

Tensorflow ASR是一個使用Tensorflow 2.0作為深度學習框架來實現各種語音處理的語音轉文本開源引擎。這個項目在Apache 2.0許可下發布。
Tensorflow最大優勢是其準確率,作者聲稱它幾乎是一個“最先進”的模型。它也是維護最好的工具之一,定期更新以改進其功能。例如,該工具包現在還支持在TPU(一種特殊硬件)上進行語言培訓。
Tensorflow還支持使用特定的模型,如:Conformer、ContextNet、DeepSpeech2和Jasper。可以根據要處理的任務進行選擇。例如,對于一般任務可以考慮DeepSpeech2,但對于精度有較高要求的則使用Conformer。
優點:
- 在處理語音轉文本時,語言模型具備較高準確性和效率。
- 可以將模型轉換為TFlite格式,使其輕量且易于部署。
- 它可以提供各種語音到文本相關的任務。
- 它支持多種語言,并提供預先訓練的英語、越南語、德語等語言模型。
缺點:
- 對于初學者來說,安裝過程可能相當復雜。用戶需要具備一定的專業知識。
- 使用高級模型有一個比較陡峭的學習曲線。
- TPU不允許測試,限制了工具的功能。
選型
以上推薦的開源語音識別引擎各有優缺點。如何選擇,取決于具體應用需求和可用資源。
如果您需要一個兼容各種設備的輕量級工具包,那么Vosk 以及 Julius比較合適。因為它們可以在Android、iOS、Raspberry Pi上運行,并且還不會占用太多資源。
如果您需要自己訓練模型,可以使用Whisper、OpenSeq2Seq、Flashlight ASR或者Athena等工具包。