













微軟祭出代碼大模型WaveCoder!四項代碼任務兩萬個實例數據集,讓LLM泛化能力飆升
用高質量數據集進行指令調優,能讓大模型性能快速提升。
對此,微軟研究團隊訓練了一個CodeOcean數據集,包含了2萬個指令實例的數據集,以及4個通用代碼相關任務。
與此同時,研究人員微調了一個代碼大模型WaveCoder。

論文地址:https://arxiv.org/abs/2312.14187
實驗結果表明,Wavecoder優于其他開源模型,在以前的代碼生成任務中表現出色。
指令調優,釋放「代碼大模型」潛力
過去的一年,GPT-4、Gemini、Llama等大模型在一系列復雜NLP任務中取得了前所未有的性能。
這些LLM利用自監督預訓練的過程,以及隨后的微調,展示了強大的零/少樣本的能力,能夠有效遵循人類指示完成不同的任務。
然而,若想訓練微調這樣一個大模型,其成本非常巨大。
因此,一些相對較小的LLM,特別是代碼大語言模型(Code LLM),因其在廣泛的代碼相關任務上的卓越的性能,而引起了許多研究者的關注。
鑒于LLM可以通過預訓練獲得豐富的專業知識,因此在代碼語料庫上進行高效的預訓練,對代碼大模型至關重要。
包括Codex、CodeGen、StarCoder和CodeLLaMa在內的多項研究已經成功證明,預訓練過程可以顯著提高大模型處理代碼相關問題的能力。
此外,指令調優的多項研究(FLAN、ExT5)表明,指令調優后的模型在各種任務中的表現符合人類預期。
這些研究將數千個任務納入訓練管道,以提高預訓練模型對下游任務的泛化能力。
比如,InstructGPT通過整合人類標注者編寫的高質量指令數據,有效地調整了用戶輸入,推進指令調優的進一步探索。
斯坦福的Alpaca利用ChatGPT通過Self-Instruct的方法,自己生成指令數據,進而用于指令調優的過程。
WizardLM和WizardCoder則應用了evol-instruct的方法,進一步提高了預訓練模型的有效性。
這些近來的研究都體現了,指令調優在提高大模型性能方面,展現出強大的潛力。
基于這些工作,研究人員的直覺是,指令調優可以激活大模型的潛力,然后將預訓練模型微調到出色的智能水平。
對此,他們總結了指令調優的主要功能:
- 泛化
指令調優最初是為了增強大模型的跨任務泛化能力而提出的,當使用不同的NLP任務指令進行微調時,指令調優可提高模型在大量未見任務中的性能。
- 對齊
預訓練模型從大量token和句子層面的自監督任務中學習,已經具備了理解文本輸入的能力。指令調優為這些預訓練模型提供了指令級任務,讓它們能夠從指令中提取原始文本語義之外的更多信息。這些額外的信息是用戶的意圖,能增強它們與人類用戶的交互能力,從而有助于對齊。
為了通過指令調優提高代碼大模型的性能,目前已有許多設計好的生成指令數據的方法,主要集中在兩個方面。
例如,self-instructe、vol-instruct利用teacher LLM的零/少樣本的能力來生成指令數據,這為教學數據的生成提供了一種神奇的方法。
然而,這些生成方法過于依賴于teacher LLM的性能,有時會產生大量的重復數據,便會降低微調的效率。
CodeOcean:四項任務代碼相關指令數據
為了解決這些問題,如圖2所示,研究人員提出了一種可以充分利用源代碼,并明確控制生成數據質量的方法。
由于指令調優是為了使預訓練模型與指令遵循訓練集保持一致,研究人員提出了一個用于指令數據生成的LLM Generator-Disciminator(大模型生成器-判別器)框架。
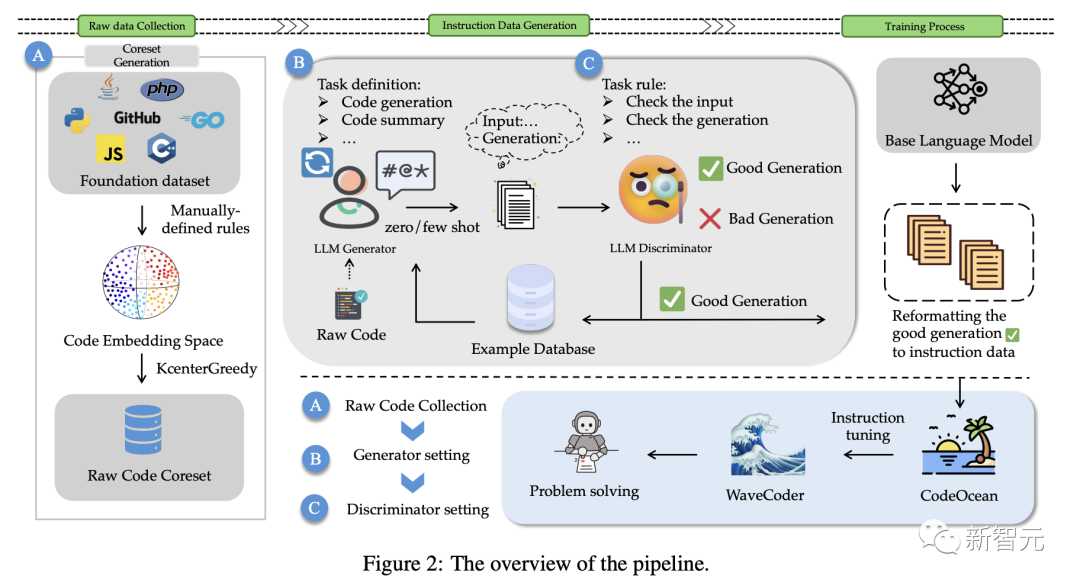
通過使用生成器和判別器,最新方法可以使數據生成過程,更可定制和更可控。
該方法以原始代碼作為輸入,選擇核心數據集,通過調整原始代碼的分布,可以穩定地生成更真實的指令數據,控制數據的多樣性。
針對上述挑戰,研究人員將指令實例分類為4個通用的代碼相關任務:代碼匯總、代碼生成、代碼翻譯、代碼修復。
同時,使用數據生成策略為4個代碼相關的任務生成一個由20000個指令實例的數據集,稱為CodeOcean。
為了驗證最新的方法,研究人員將StarCoder、CodeLLaMa、DeepseekCoder作為基礎模型,根據最新的數據生成策略,微調出全新的WaveCoder模型。
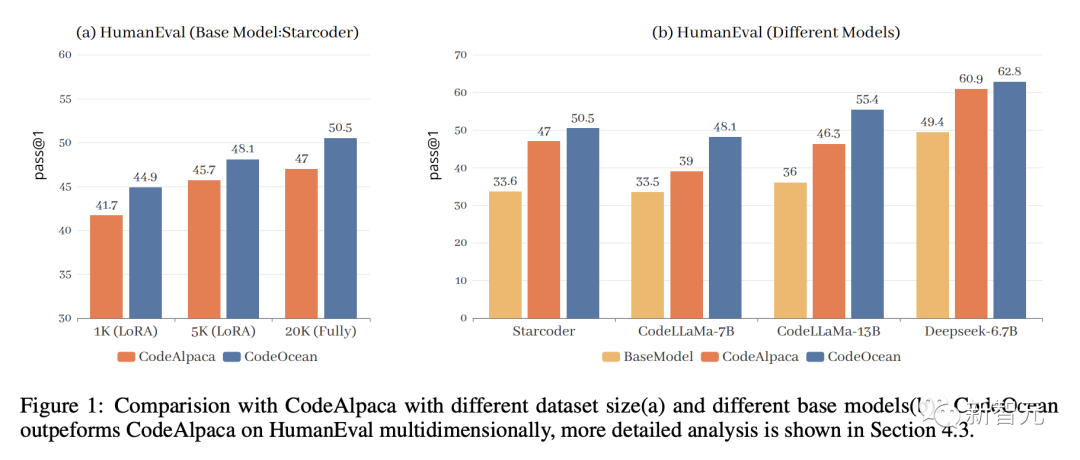
與此同時,研究人員在 HumanEval、MBPP、HumanEvalPack對模型進行了評估,結果表明,WaveCoder在小規模指令調優的基準上擁有出色的性能。
代碼數據生成
如上所述,研究人員選擇了4個具有代表性的編碼任務,并從開源數據集中收集原始代碼。
以下具體介紹了訓練數據生成過程。
在本節中,我們將介紹我們探索的方法細節。我們首先選擇4個代表性的編碼任務,并從開源數據集中收集原始代碼。
對于每個任務,作者使用GPT-3.5-turbo生成指令數據進行微調。生成提示如表2所示。

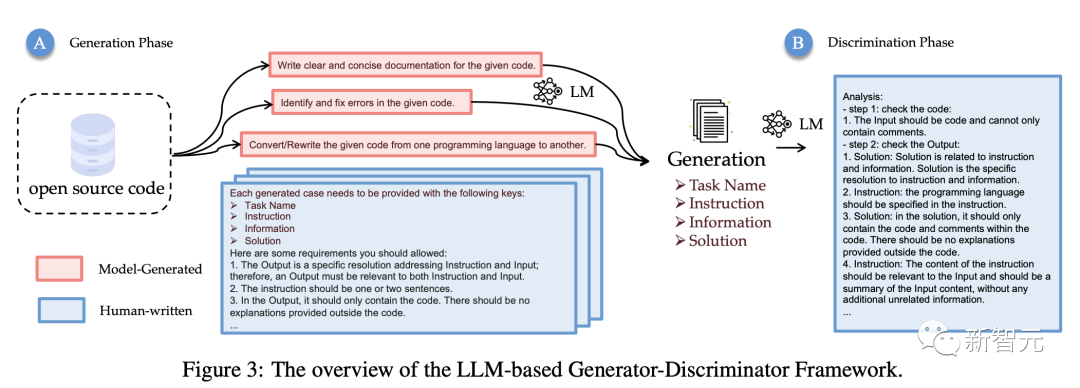
如下,是LLM Generator-Disciminator整體架構,也是數據生成的完整過程。
Codesearchnet是一個包含來自 GitHub 上托管的開源庫的200萬對(注釋、代碼)的數據集。它包括6種編程語言的代碼和文檔。我們選擇 CodeSearchNet 作為我們的基礎數據集,并應用基于 coreset 的選擇方法KCenterGreedy來最大化原始代碼的多樣性。
具體來說,生成器根據輸入(a)生成指令數據。隨后,判別器接受輸出并生成分析結果,輸出(b)包括四個鍵,研究人員將這些信息作為指令調優的輸入和輸出。
分析(c)包括每條規則的詳細原因和總體答案,以檢查樣本是否滿足所有要求。

實驗評估結果
代碼生成任務評估
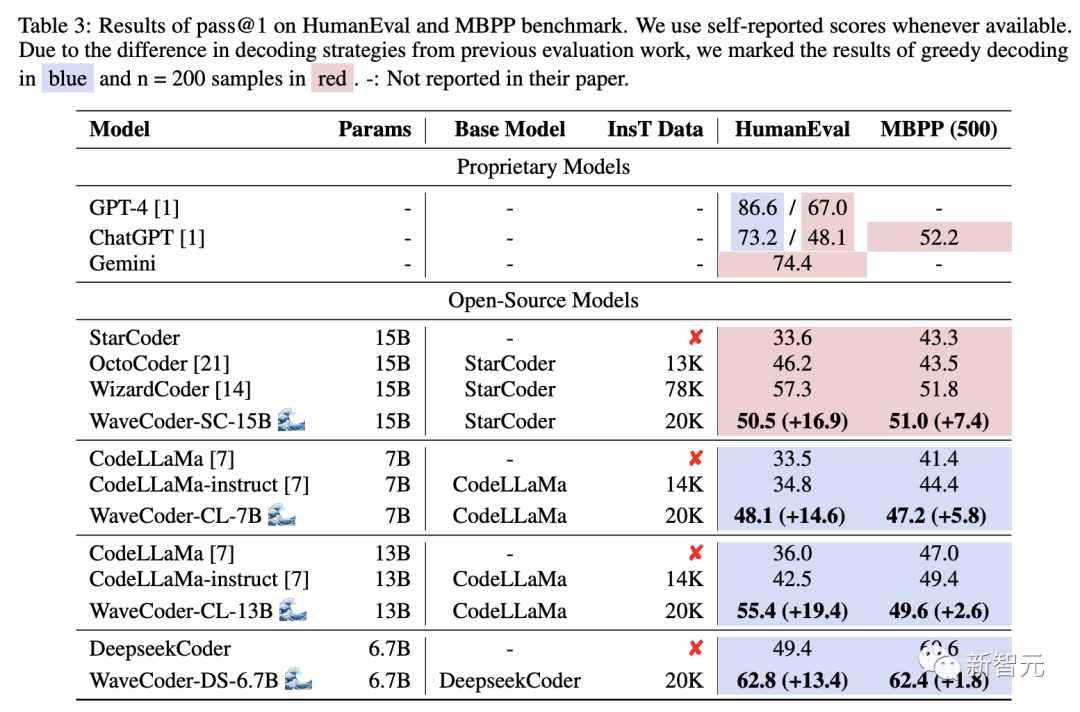
表3顯示了兩個基準上不同大模型的pass@1得分。從結果來看,我們有以下觀察結果:
WaveCoder大大優于使用少于20k指令調優數據(InsT Data)的指令模型訓練。
經過微調過程,與基礎模型和開源模型的選擇相比,最新模型的性能顯示出實質性的改善,但它仍然落后于專有模型的指導模型訓練超過70k的訓練數據。
研究人員還用HumanEvalPack上最先進的Code LLM對WaveCoder進行評分,如表4。
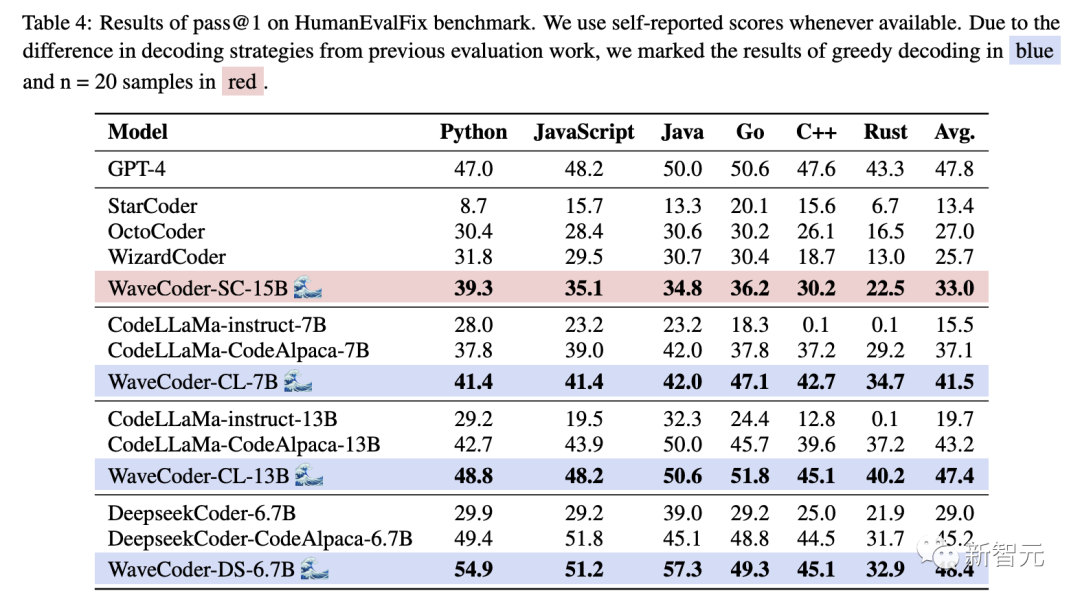
表5列出了WaveCoder在代碼匯總任務方面的結果,突出顯示了以下顯著的觀察結果:

















