













攻克圖像「文本生成」難題,碾壓同級(jí)擴(kuò)散模型!兩代TextDiffuser架構(gòu)深度解析
近年來,文本生成圖像領(lǐng)域取得了顯著進(jìn)展,尤其是基于擴(kuò)散(Diffusion)的圖像生成模型在細(xì)節(jié)層面上展現(xiàn)出逼真的效果。
然而,一個(gè)挑戰(zhàn)仍然存在:如何將文本準(zhǔn)確地融入圖像。
生活中存在大量的「含文本圖像」,從廣告海報(bào)到書籍封面,再到路牌指示,都包含了重要的信息。如果人工智能模型能夠高效且準(zhǔn)確地生成含有文本的圖像,將極大推動(dòng)設(shè)計(jì)和視覺藝術(shù)領(lǐng)域的發(fā)展。
例如現(xiàn)有的先進(jìn)開源模型Stable Diffusion和閉源模型MidJourney都在文本渲染上存在巨大挑戰(zhàn)。

Stable Diffusion:a bear holds a board saying 'hello world'」
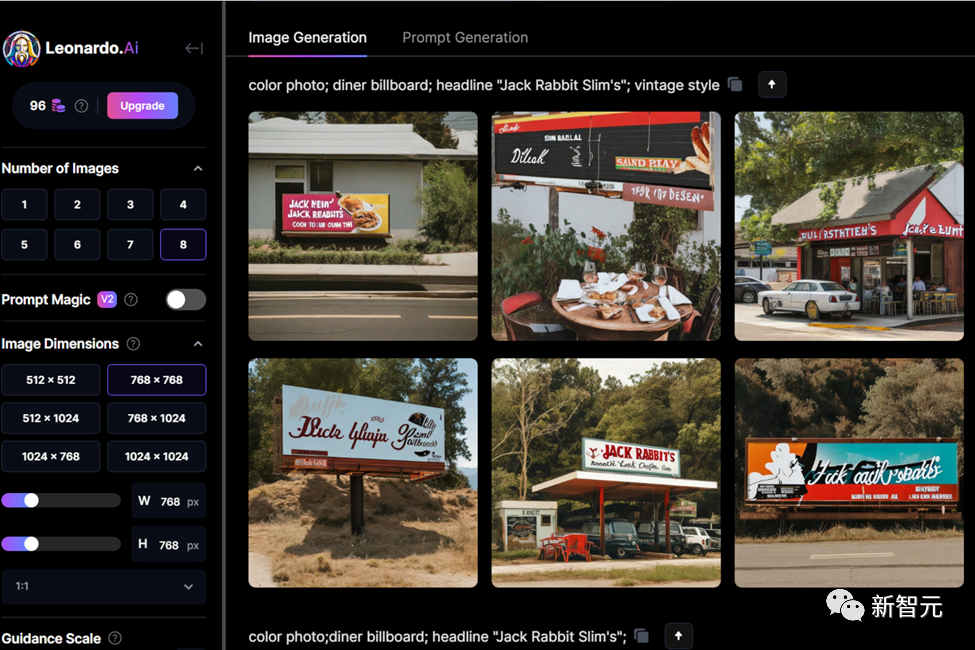
MidJourney:Color photo; diner billboard; headline “Jack Rabbit Slim’s”; vintage style (Leonardo AI prompted by Alan Truly)
為了應(yīng)對(duì)這一挑戰(zhàn),微軟亞洲研究院自然語言計(jì)算組聯(lián)合香港科技大學(xué)和中山大學(xué),提出了TextDiffuser和TextDiffuser-2模型。
這兩款模型不僅提升了圖像中文本渲染的準(zhǔn)確性和清晰度,還提升了靈活度和實(shí)用性,能夠執(zhí)行文本到圖像的生成、基于文本模板的圖像生成,或是圖像的文本補(bǔ)全等與文本渲染相關(guān)的任務(wù)。

論文標(biāo)題:TextDiffuser: Diffusion Models as Text Painters
項(xiàng)目主頁:https://jingyechen.github.io/textdiffuser/
代碼鏈接:https://github.com/microsoft/unilm/tree/master/textdiffuser
在線Demo:https://huggingface.co/spaces/JingyeChen22/TextDiffuser

TextDiffuser對(duì)于以上兩個(gè)prompt生成的結(jié)果
TextDiffuser
模型通過兩階段的工作流程生成含有文本的圖像。
第一階段,模型通過用戶的提示(prompt)確定關(guān)鍵詞的文本布局。
它采用了Layout Transformer技術(shù),自回歸地生成每個(gè)關(guān)鍵詞的坐標(biāo)框,相當(dāng)于得到了字符坐標(biāo)框級(jí)別的遮罩(Box-Level Segmentation Mask),能為每個(gè)字符提供精確的控制。
第二階段,作者改進(jìn)了Stable Diffusion架構(gòu)以結(jié)合字符的坐標(biāo)框信息進(jìn)行生成,使得TextDiffuser能夠在指定位置生成清晰的字符。
具體來說,作者重新設(shè)計(jì)了輸入的特征,維度由原先的4維變成了17維。其中包含4維加噪圖像的特征,8維字符信息,1維圖像掩碼,還有4維未被mask圖像的特征。通過mask圖像的部分或全部,即可實(shí)現(xiàn)生成部分圖像(稱為Part-Image Generation或Text-inpainting)或是整張圖像(稱為Whole-Image Generation)。
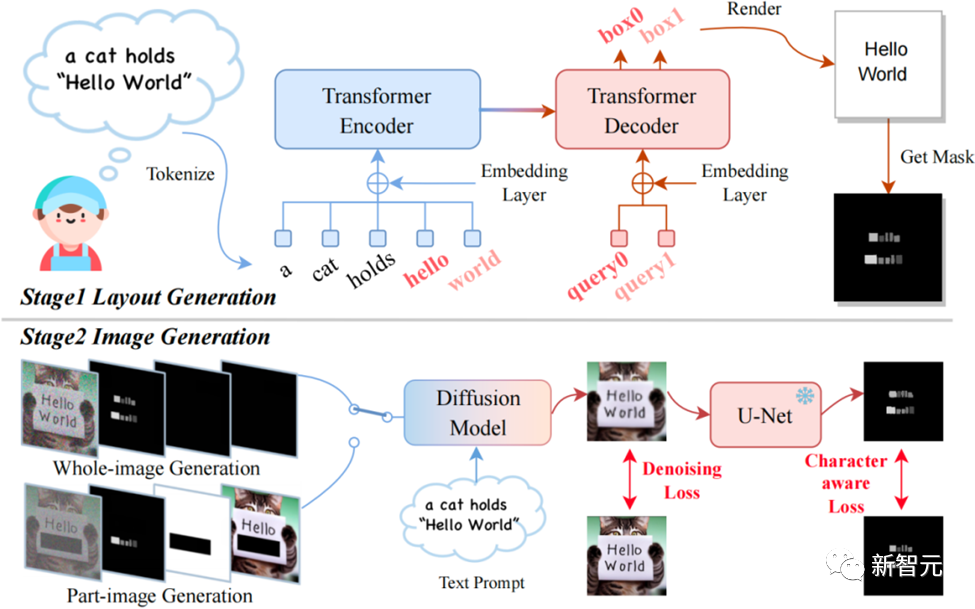
TextDiffuser框架圖,包含兩個(gè)階段:布局生成與圖像生成
在Inference階段,TextDiffuser非常靈活,有三種使用方式:
1. 根據(jù)用戶給定的指令生成圖像。并且,如果用戶不滿意第一步Layout Generation生成的布局,用戶可以更改坐標(biāo)也可以更改文本的內(nèi)容,這增加了模型的可控性。
2. 直接從第二個(gè)階段開始。根據(jù)模板圖像生成最終結(jié)果,其中模板圖像可以是印刷文本圖像,手寫文本圖像,場(chǎng)景文本圖像。作者訓(xùn)練了一個(gè)字符集分割網(wǎng)絡(luò)用于從模板圖像中提取Layout。
3. 同樣也是從第二個(gè)階段開始,用戶給定圖像并指定需要修改的區(qū)域與文本內(nèi)容。該操作可以多次進(jìn)行,直到用戶對(duì)生成的結(jié)果感到滿意為止。
為了支持TextDiffuser的訓(xùn)練,研究團(tuán)隊(duì)構(gòu)建了一個(gè)包含1000萬張文本圖像的MARIO-10M數(shù)據(jù)集,包含三個(gè)子集:LAION-OCR,TMDB與OpenLibrary。

作者還基于MARIO設(shè)計(jì)了MARIO-Eval文本渲染任務(wù)的大規(guī)模基準(zhǔn)。作者進(jìn)行了實(shí)驗(yàn),與DeepFloyd等先進(jìn)模型對(duì)比。
例如下圖所示,在Whole-Image Generation任務(wù)中,TextDiffuser生成的圖像具有更加清晰可讀的文本,并且文本區(qū)域與背景區(qū)域較為和諧。
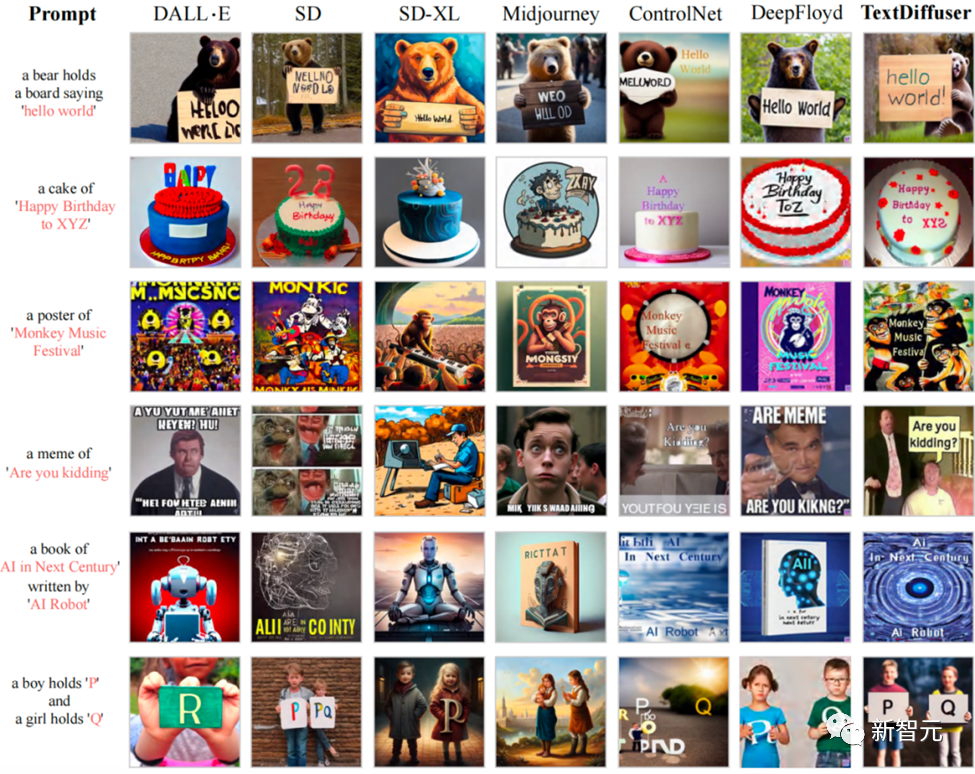
與現(xiàn)有文本生成圖像方法相比,TextDiffuser可以生成正確的文本,并且文本與背景融合度較高
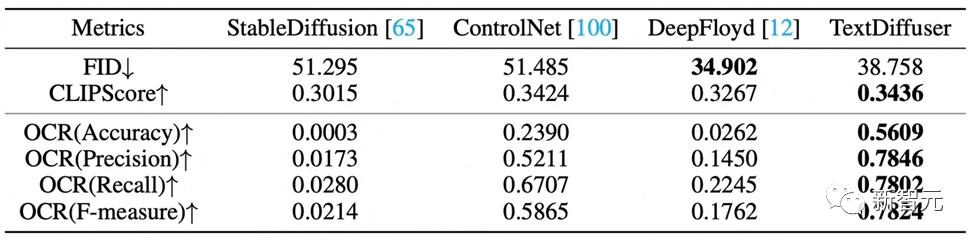
定性的實(shí)驗(yàn)的評(píng)估指標(biāo)有FID,CLIPScore與OCR。尤其是OCR指標(biāo),TextDiffuser相對(duì)于對(duì)比方法有很大的提升。
對(duì)于Part-Image Generation任務(wù),下面是在給定的圖像上增加或修改字符的例子,TextDiffuser生成的結(jié)果很自然。
TextDiffuser-2
TextDiffuser-2進(jìn)一步釋放了語言模型在視覺文本渲染方面的潛能,提升了文本渲染的多樣性和靈活性。

論文標(biāo)題:TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
項(xiàng)目主頁:https://jingyechen.github.io/textdiffuser2/
代碼鏈接:https://github.com/microsoft/unilm/tree/master/textdiffuser-2
在線Demo:https://huggingface.co/spaces/JingyeChen22/TextDiffuser-2
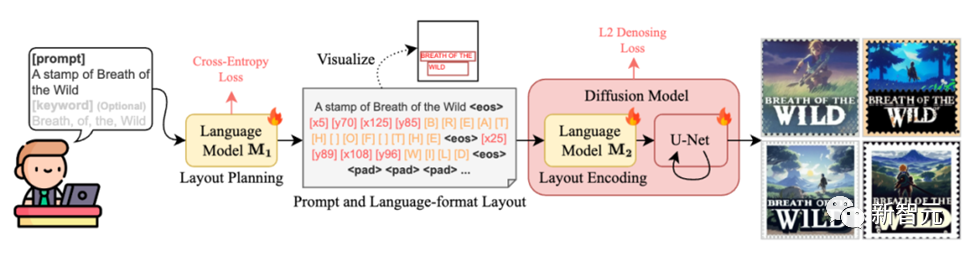
TextDiffuser-2繼承并優(yōu)化了其前身TextDiffuser的核心特性,主要?jiǎng)?chuàng)新在于其對(duì)語言模型的應(yīng)用。現(xiàn)有研究成果顯示,大型語言模型內(nèi)含有對(duì)視覺布局有一定理解的能力,足以處理布局生成任務(wù)。
基于這一發(fā)現(xiàn),研究團(tuán)隊(duì)用圖像描述-文本布局?jǐn)?shù)據(jù)集對(duì)vicuna-1.5-7B語言模型進(jìn)行了微調(diào),使TextDiffuser-2能夠更有效地處理文本布局生成任務(wù),生成協(xié)調(diào)且美觀的布局。
此外,TextDiffuser-2采用了Stable Diffusion模型中現(xiàn)有的語言模型編碼布局信息,通過引入坐標(biāo)token和字符token,提高了在特定位置繪制相應(yīng)文本內(nèi)容的能力。
具體來說,第一階段的目標(biāo)是對(duì)一個(gè)預(yù)訓(xùn)練的大型語言模型M1進(jìn)行微調(diào),讓它能夠作為解碼器,使用圖片描述與OCR(光學(xué)字符識(shí)別)結(jié)果對(duì)進(jìn)行訓(xùn)練。輸入遵循這樣的格式:“[描述] 提示: [提示] 關(guān)鍵詞: [關(guān)鍵詞]”。
輸出方面,我們期望每一行都遵循“文本行x0, y0, x1, y1”的格式,其中(x0, y0)和(x1, y1)分別代表左上角和右下角的坐標(biāo)。我們利用OCR結(jié)果中檢測(cè)到的所有文本作為關(guān)鍵詞來構(gòu)造輸入。
通過這樣的方法,TextDiffuser-2模型不僅能夠根據(jù)用戶的需求靈活地生成圖像布局,還能夠通過對(duì)話交互的方式,進(jìn)一步細(xì)化和調(diào)整布局,為圖像生成提供更高的靈活性和個(gè)性化選項(xiàng)。
第二階段引入了一種簡(jiǎn)單且無需額外參數(shù)的策略,即將提示(prompt)和布局結(jié)合到語言模型M2中,M2在潛在擴(kuò)散模型中扮演文本編碼器的角色。
與調(diào)節(jié)個(gè)別字符位置的字符級(jí)分割掩碼不同,行級(jí)邊界框在生成過程中提供了更大的靈活性,并且不會(huì)限制樣式的多樣性。之前的研究表明,細(xì)粒度的分詞可以增強(qiáng)擴(kuò)散模型的拼寫能力。
受此啟發(fā),作者設(shè)計(jì)了一種混合粒度的分詞方法,既提高了模型的拼寫能力,又避免了序列變得過長(zhǎng)。具體來說,一方面,作者保持了原始的BPE分詞方法用于處理提示。
另一方面,作者引入了新的字符token,并將每個(gè)關(guān)鍵詞分解為字符級(jí)表示。例如,單詞“WILD”被分解為token “[W]”, “[I]”, “[L]”, “[D]”。此外,作者引入了新的坐標(biāo)token來編碼位置。例如,token “[x5]”和“[y70]”分別對(duì)應(yīng)于x坐標(biāo)5和y坐標(biāo)70。
每個(gè)關(guān)鍵詞信息由結(jié)束符token “?eos?”分隔,任何剩余的空間直到最大長(zhǎng)度L將被填充token “?pad?”填充。作者對(duì)整個(gè)擴(kuò)散模型進(jìn)行訓(xùn)練,包括語言模型M2和U-Net,使用L2去噪損失。
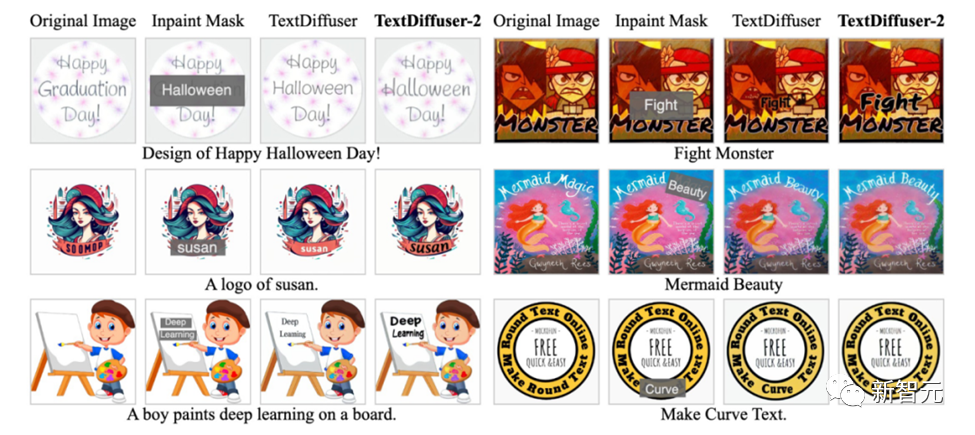
作者進(jìn)行了廣泛的實(shí)驗(yàn)來驗(yàn)證TextDiffuser-2的有效性,在文本到圖像生成的任務(wù)上,與當(dāng)前最前沿的模型進(jìn)行比較,TextDiffuser-2展示了卓越性能,不僅能準(zhǔn)確渲染文字,而且展示了布局的自然性和逼真度。
在處理復(fù)雜和多樣化的文本樣式方面,例如手寫體和藝術(shù)體,TextDiffuser-2 表現(xiàn)出色,證明了其在細(xì)節(jié)和樣式多樣性上的優(yōu)勢(shì)。

此外,在圖像的文本補(bǔ)全(Text Inpainting)任務(wù)上,TextDiffuser-2同樣展現(xiàn)了其優(yōu)越性,能夠在保持文本與背景匹配的同時(shí),提升整體圖像的質(zhì)感和美觀度。
在定量實(shí)驗(yàn)中,TextDiffuser-2在大多數(shù)指標(biāo)上具有優(yōu)異的性能。
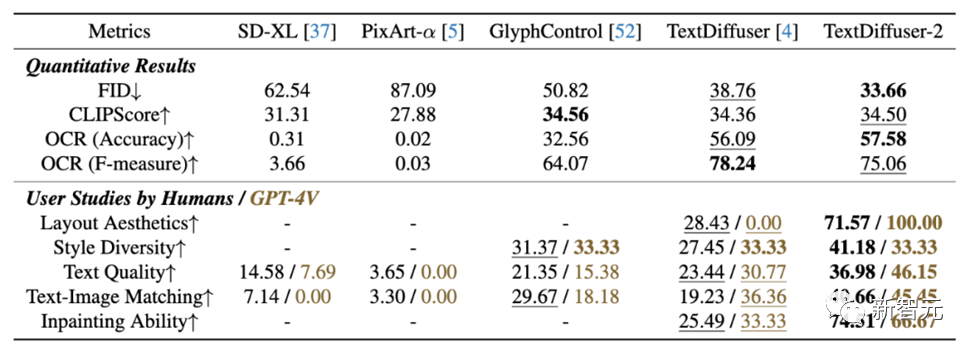
研究團(tuán)隊(duì)還使用GPT-4V進(jìn)行了用戶評(píng)測(cè)。評(píng)測(cè)結(jié)果顯示,GPT-4V具有優(yōu)異的識(shí)圖識(shí)字能力,并且其總結(jié)的理由也顯得合理。TextDiffuser-2在GPT-4V的評(píng)測(cè)中也獲得了比其他對(duì)比模型優(yōu)異的結(jié)果。

TextDiffuser和TextDiffuser-2的推出及其持續(xù)發(fā)展,在圖像中準(zhǔn)確渲染文本這一任務(wù)上取得了顯著的進(jìn)步。
為了促進(jìn)這一技術(shù)的廣泛應(yīng)用,研究團(tuán)隊(duì)已經(jīng)公布了TextDiffuser和 TextDiffuser-2的代碼、數(shù)據(jù)集和Demo,鼓勵(lì)廣大研究者和設(shè)計(jì)師進(jìn)行探索和應(yīng)用,進(jìn)一步推動(dòng)設(shè)計(jì)和視覺藝術(shù)領(lǐng)域的創(chuàng)新與發(fā)展。























