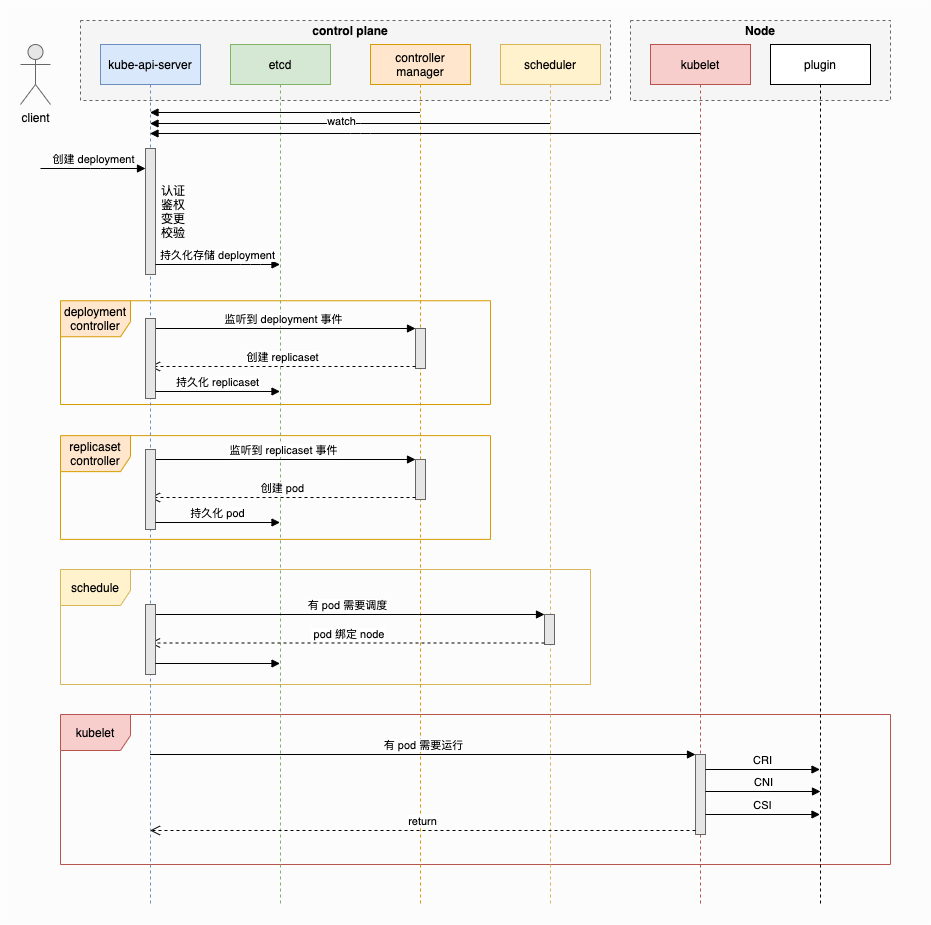
Kubernetes 從提交 deployment 到 pod 運行的全過程
當用戶向 Kubernetes 提交了一個創建 deployment 的請求后,Kubernetes 從接收請求直至創建對應的 pod 運行這整個過程中都發生了什么呢?
kubernetes 架構簡述
在搞清楚從 deployment 提交到 pod 運行整個過程之前,我們有先來看看 Kubernetes 的集群架構:
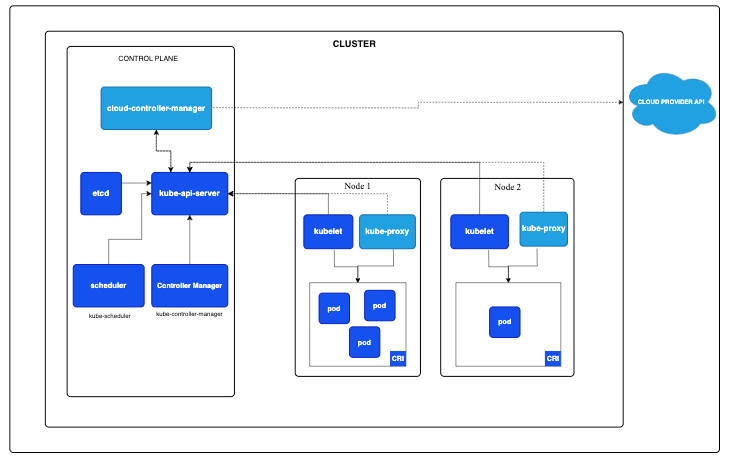
上圖與下圖相同:
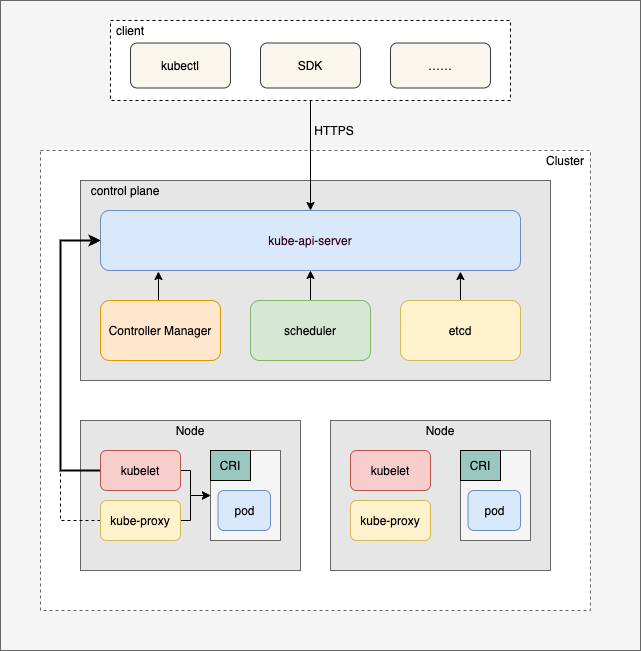
如圖所示,k8s 集群分為 control plane 控制平面和 node 節點。
control plane 控制平面(也稱之為主節點)主要包含以下組件:
- kube-api-server: 顧名思義,負責處理所有 api,包括客戶端以及集群內部組件的請求。
- etcd: 分布式持久化存儲、事件訂閱通知。只有 kube-api-server 直接操作 etcd,其它所有組件都是與 kube-api-server 進行相互。
- scheduler: 處理 pod 的調度,將 pod 綁定到具體的 node 節點。
- controller manager: 控制器,處理各種資源對象。
- cloud controller manager: 對接云服務商的控制器。
node 節點,專門部署用戶的應用程序(與控制平面隔離,避免影響到 k8s 的核心組件),主要包含以下組件:
- kubelet: 管理節點上的 pod 以及狀態檢查和上報。
- kube-proxy: 進行流量的路由轉發(目前是通過操作節點的 iptables 或者 ipvs 實現)。
- CRI: 容器運行時接口。
從 Deployment 到 Pod
從 Deployment 到 Pod 的整個過程如下圖所示:
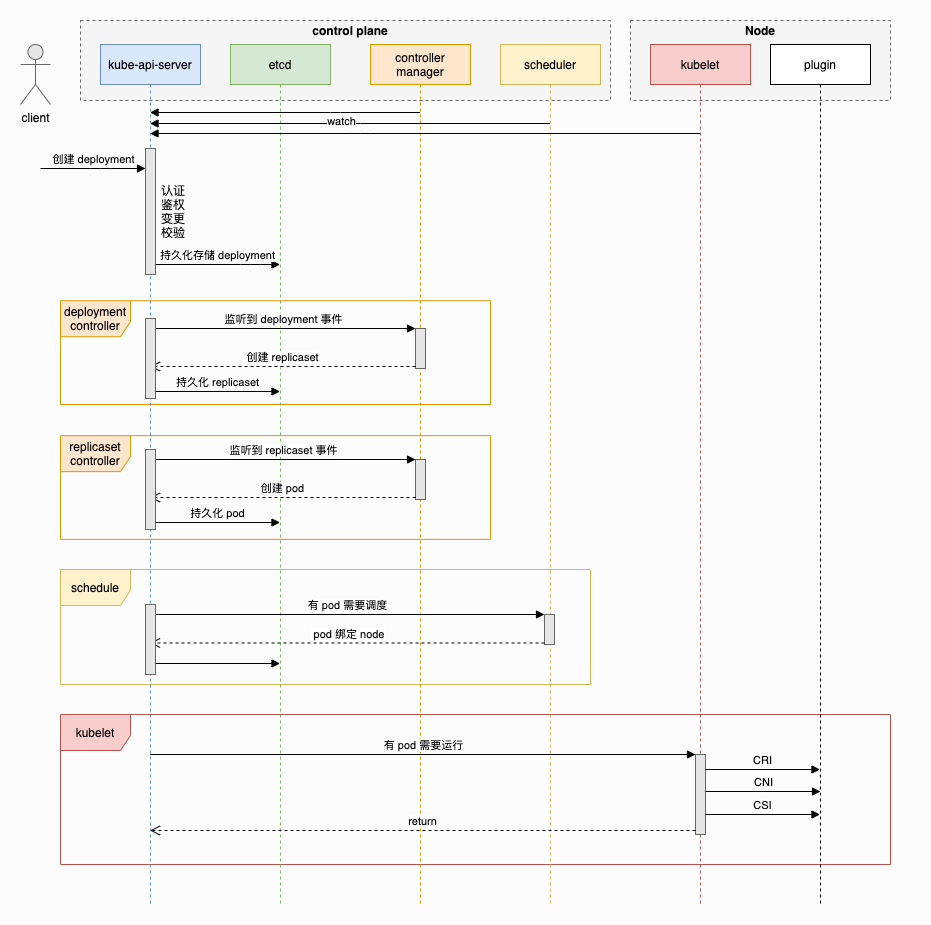
1. 請求發送到 kube-api-server
請求發送到 kube-api-server,然后會進行認證、鑒權、變更、校驗等一系列過程,最后將 deployment 的數據持久化存儲至 etcd。
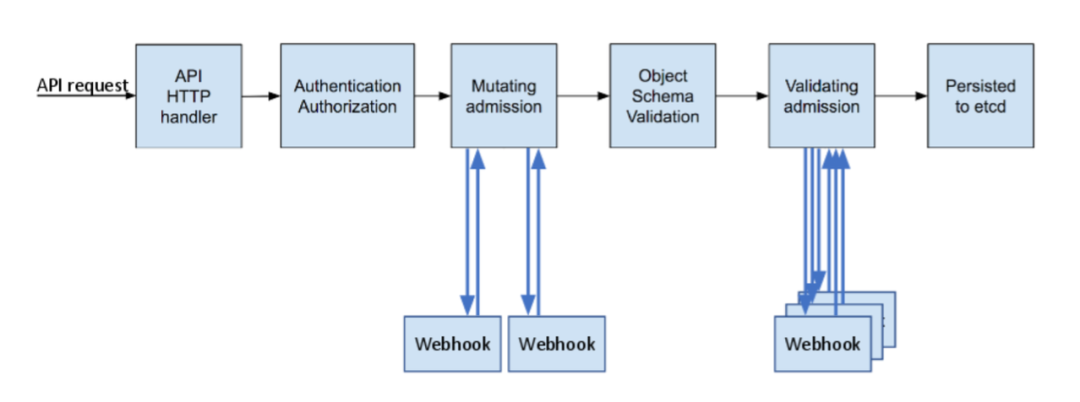
在這個過程我們可以通過 mutation admission 的 webhook 自主地對資源對象進行任意的變更,比如注入 sidecar 等等。
2. controller manager 處理
controller manager 組件針對不同的資源對象有不同的處理部分。
針對 Deployment,由于其并不直接管理 Pod,而是 Deployment 管理 ReplicaSet,ReplicaSet 再管理 Pod:
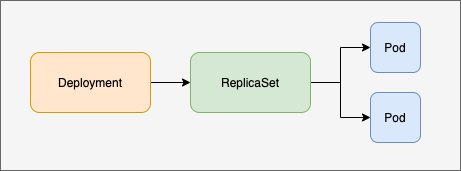
因此其中涉及到 controller manager 中的兩個部分:
- deployment controller
- replicaset controller
(1) 先是 deployment controller 監聽到 deployment 的創建事件,然后進行相關的處理,最后創建 replicaset。
(2) 然后 replicaset controller 監聽到 replicaset 的創建事件,進行相關處理后,最后創建 pod。
3. scheduler 調度
scheduler 接受到 pod 需要調度的事件后,進行一系列調度邏輯處理,最后選擇一個合適的 node 節點,將 pod 綁定到這個節點上(所謂的節點調度在這里只是修改 pod 數據,對其中的 nodeName 進行賦值)。
具體的調度算法比較復雜,涉及強制性調度、親和與反親和、污點和容忍、以及硬件資源計算、優先級等等,本文不做展開。
4. 節點 kubelet 處理
調度完成后,pod 被綁定的 node 節點上的 kubelet 同樣通過 kube-api-server 會接受到相應的事件,然后 kubelet 會進行 pod 的創建。
在這個過程中 kubelet 會分別調用 CRI、CNI、CSI:
- CRI(Container Runtime Interface): 容器運行時接口,CRI 插件負責執行拉取鏡像、創建、刪除容器等操作。CRI 的幾種常用插件:
- containerd
- CRI-O
- Docker Engine
- CNI(Container Network Interface): 容器網絡接口,CNI 插件負責給 pod 分配 IP 地址,確保 pod 能夠與集群內的其它 pod 進行通信。CNI 的幾種常用插件:
- Cilium
- Calico
- CSI(Container Storage Interface): 容器存儲接口,CSI 插件負責與外部存儲提供者通信,執行卷的附加、掛載等操作。
所謂的接口其實只是定義了通信的規范或者標準(使用的是 grpc 協議),具體的實現則是交給了插件。
至此,Kubernetes 從創建 deployment 到 pod 運行的全過程就是這樣了。