大模型+機(jī)器人,詳盡的綜述報告來了,多位華人學(xué)者參與
大模型的出色能力有目共睹,而如果將它們整合進(jìn)機(jī)器人,則有望讓機(jī)器人擁有一個更加智能的大腦,為機(jī)器人領(lǐng)域帶來新的可能性,比如自動駕駛、家用機(jī)器人、工業(yè)機(jī)器人、輔助機(jī)器人、醫(yī)療機(jī)器人、現(xiàn)場機(jī)器人和多機(jī)器人系統(tǒng)。
預(yù)訓(xùn)練的大型語言模型(LLM)、大型視覺 - 語言模型(VLM)、大型音頻 - 語言模型(ALM)和大型視覺導(dǎo)航模型(VNM)可以被用于更好地處理機(jī)器人領(lǐng)域的各種任務(wù)。將基礎(chǔ)模型整合進(jìn)機(jī)器人是一個快速發(fā)展的領(lǐng)域,機(jī)器人社區(qū)最近已經(jīng)開始探索將這些大模型用于感知、預(yù)測、規(guī)劃和控制等機(jī)器人領(lǐng)域。
近日,斯坦福大學(xué)和普林斯頓大學(xué)等多所大學(xué)以及英偉達(dá)和 Google DeepMind 等多家企業(yè)的一個聯(lián)合研究團(tuán)隊發(fā)布了一篇綜述報告,總結(jié)了基礎(chǔ)模型在機(jī)器人研究領(lǐng)域的發(fā)展情況和未來挑戰(zhàn)。

- 論文地址:https://arxiv.org/pdf/2312.07843.pdf
- 論文庫:https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
團(tuán)隊成員中有很多我們熟悉的華人學(xué)者,包括朱玉可、宋舒然、吳佳俊、盧策吾等。
在范圍廣泛的大規(guī)模數(shù)據(jù)上預(yù)訓(xùn)練的基礎(chǔ)模型在微調(diào)之后可以適用于多種多樣的下游任務(wù)。基礎(chǔ)模型已經(jīng)在視覺和語言處理方面取得了重大突破,相關(guān)模型包括 BERT、GPT-3、GPT-4、CLIP、DALL-E 和 PaLM-E。
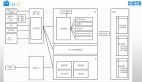
在基礎(chǔ)模型出現(xiàn)之前,用于機(jī)器人的傳統(tǒng)深度學(xué)習(xí)模型的訓(xùn)練使用的都是為不同任務(wù)收集的有限數(shù)據(jù)集。相反,基礎(chǔ)模型則是會使用大范圍多樣化數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,在其他領(lǐng)域(比如自然語言處理、計算機(jī)視覺和醫(yī)療保健)的應(yīng)用證明了其適應(yīng)能力、泛化能力和總體性能表現(xiàn)。最終,基礎(chǔ)模型也有望在機(jī)器人領(lǐng)域展現(xiàn)出自己的潛力。圖 1 展示了基礎(chǔ)模型在機(jī)器人領(lǐng)域的概況。

相比于針對特定任務(wù)的模型,從基礎(chǔ)模型遷移知識有可能減少訓(xùn)練時間和計算資源。尤其是在機(jī)器人相關(guān)領(lǐng)域,多模態(tài)基礎(chǔ)模型可以將從不同傳感器收集的多模態(tài)異構(gòu)數(shù)據(jù)融合和對齊成緊湊的緊湊同質(zhì)表征,而這正是機(jī)器人理解和推理所需的。其學(xué)習(xí)到的表征可望用于自動化技術(shù)棧的任何部分,包括感知、決策和控制。
不僅如此,基礎(chǔ)模型還能提供零樣本學(xué)習(xí)能力,也就是讓 AI 系統(tǒng)有能力在沒有任何示例或針對性訓(xùn)練的前提下執(zhí)行任務(wù)。這能讓機(jī)器人將所學(xué)知識泛化到全新的用例,增強(qiáng)機(jī)器人在非結(jié)構(gòu)化環(huán)境中的適應(yīng)能力和靈活性。
將基礎(chǔ)模型整合進(jìn)機(jī)器人系統(tǒng)能提升機(jī)器人感知環(huán)境以及與環(huán)境交互的能力,有可能實現(xiàn)上下文感知型機(jī)器人系統(tǒng)。
舉個例子,在感知領(lǐng)域,大型視覺 - 語言模型(VLM)能夠?qū)W習(xí)視覺和文本數(shù)據(jù)之間的關(guān)聯(lián),從而具備跨模態(tài)理解能力,從而輔助零樣本圖像分類、零樣本目標(biāo)檢測和 3D 分類等任務(wù)。再舉個例子,3D 世界中的語言定基(language grounding,即將 VLM 的上下文理解與 3D 現(xiàn)實世界對齊)可以通過將話語與 3D 環(huán)境中的具體對象、位置或動作關(guān)聯(lián)起來,從而增強(qiáng)機(jī)器人的空間感知能力。
在決策或規(guī)劃領(lǐng)域,研究發(fā)現(xiàn) LLM 和 VLM 可以輔助機(jī)器人規(guī)范涉及高層規(guī)劃的任務(wù)。
通過利用與操作、導(dǎo)航和交互有關(guān)的語言線索,機(jī)器人可以執(zhí)行更加復(fù)雜的任務(wù)。比如對于模仿學(xué)習(xí)和強(qiáng)化學(xué)習(xí)等機(jī)器人策略學(xué)習(xí)技術(shù),基礎(chǔ)模型似乎有能力提升數(shù)據(jù)效率和上下文理解能力。特別是語言驅(qū)動的獎勵可通過提供經(jīng)過塑造的獎勵來引導(dǎo)強(qiáng)化學(xué)習(xí)智能體。
另外,研究者也已經(jīng)在利用語言模型來為策略學(xué)習(xí)技術(shù)提供反饋。一些研究表明,VLM 模型的視覺問答(VQA)能力可以用于機(jī)器人用例。舉個例子,已有研究者使用 VLM 來回答與視覺內(nèi)容有關(guān)的問題,從而幫助機(jī)器人完成任務(wù)。另外,也有研究者使用 VLM 來幫助數(shù)據(jù)標(biāo)注,為視覺內(nèi)容生成描述標(biāo)簽。
盡管基礎(chǔ)模型在視覺和語言處理方面具備變革性的能力,但對于現(xiàn)實世界的機(jī)器人任務(wù)來說,基礎(chǔ)模型的泛化和微調(diào)依然頗具挑戰(zhàn)性。
這些挑戰(zhàn)包括:
1) 缺少數(shù)據(jù):如何為機(jī)器人操作、定位、導(dǎo)航等機(jī)器人任務(wù)獲取互聯(lián)網(wǎng)規(guī)模級的數(shù)據(jù),以及如何使用這些數(shù)據(jù)執(zhí)行自監(jiān)督訓(xùn)練;
2) 巨大的差異性:如何應(yīng)對物理環(huán)境、實體機(jī)器人平臺和潛在的機(jī)器人任務(wù)的巨大多樣性,同時保持基礎(chǔ)模型所需的通用性;
3) 不確定性的量化問題:如何解決實例層面的不確定性(比如語言歧義或 LLM 幻覺)、分布層面的不確定性和分布移位問題,尤其是閉環(huán)的機(jī)器人部署引起的分布移位問題。
4) 安全評估:如何在部署之前、更新過程中、工作過程中對基于基礎(chǔ)模型的機(jī)器人系統(tǒng)進(jìn)行嚴(yán)格測試。
5) 實時性能:如何應(yīng)對某些基礎(chǔ)模型推理時間長的問題 —— 這會有礙基礎(chǔ)模型在機(jī)器人上的部署,以及如何加速基礎(chǔ)模型的推理 —— 這是在線決策所需的。
這篇綜述論文總結(jié)了當(dāng)前基礎(chǔ)模型在機(jī)器人領(lǐng)域的使用情況。他們調(diào)查了當(dāng)前的方法、應(yīng)用、挑戰(zhàn),并建議了解決這些挑戰(zhàn)的未來研究方向,他們也給出了將基礎(chǔ)模型用于實現(xiàn)機(jī)器人自主能力的潛在風(fēng)險。
基礎(chǔ)模型背景知識
基礎(chǔ)模型有數(shù)以十億計的參數(shù),并且使用了互聯(lián)網(wǎng)級的大規(guī)模數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練。訓(xùn)練如此大規(guī)模和高復(fù)雜性的模型需要極高的成本。獲取、處理和管理數(shù)據(jù)的成本也會很高。其訓(xùn)練過程需要大量計算資源,需要 GPU 或 TPU 等專用硬件,還需要用于模型訓(xùn)練的軟件和基礎(chǔ)設(shè)施,這些都需要資金。此外,需要基礎(chǔ)模型還需要很長的時間,這也會導(dǎo)致高成本。因此這些模型往往是作為可插拔模塊使用的,即將基礎(chǔ)模型整合進(jìn)各種應(yīng)用中,而無需大量定制工作。
表 1 給出了常用基礎(chǔ)模型的細(xì)節(jié)。
這一節(jié)將主要介紹 LLM、視覺 Transformer、VLM、具身多模態(tài)語言模型和視覺生成模型。還會介紹用于訓(xùn)練基礎(chǔ)模型的不同訓(xùn)練方法。
他們首先介紹了一些相關(guān)的術(shù)語和數(shù)學(xué)知識,其中涉及 token 化、生成模型、判別模型、Transformer 架構(gòu)、自回歸模型、掩碼式自動編碼、對比學(xué)習(xí)和擴(kuò)散模型。
然后他們介紹了大型語言模型(LLM)的示例和歷史背景。之后重點說明了視覺 Transformer、多模態(tài)視覺 - 語言模型(VLM)、具身多模態(tài)語言模型、視覺生成模型。
機(jī)器人研究
這一節(jié)關(guān)注的是機(jī)器人決策、規(guī)劃和控制。在這一領(lǐng)域,大型語言模型(LLM)和視覺語言模型(VLM)都有潛力用于增強(qiáng)機(jī)器人的能力。舉個例子,LLM 可以促進(jìn)任務(wù)規(guī)范過程,讓機(jī)器人可以接收和解讀來自人類的高級指令。
VLM 也有望為這一領(lǐng)域做出貢獻(xiàn)。VLM 擅長分析視覺數(shù)據(jù)。要讓機(jī)器人做出明智的決策和執(zhí)行復(fù)雜的任務(wù),視覺理解能力是至關(guān)重要的。現(xiàn)在,機(jī)器人可以使用自然語言線索來增強(qiáng)自己執(zhí)行操作、導(dǎo)航和交互相關(guān)任務(wù)的能力。
基于目標(biāo)的視覺 - 語言策略學(xué)習(xí)(不管是通過模仿學(xué)習(xí)還是強(qiáng)化學(xué)習(xí))有望通過基礎(chǔ)模型獲得提升。語言模型還能為策略學(xué)習(xí)技術(shù)提供反饋。這個反饋循環(huán)有助于持續(xù)提升機(jī)器人的決策能力,因為機(jī)器人可以根據(jù)從 LLM 收到的反饋優(yōu)化自己的行動。
這一節(jié)關(guān)注的是 LLM 和 VLM 在機(jī)器人決策領(lǐng)域的應(yīng)用。
這一節(jié)分為六部分。其中第一部分介紹了用于決策和控制和機(jī)器人策略學(xué)習(xí),其中包括基于語言的模仿學(xué)習(xí)和語言輔助的強(qiáng)化學(xué)習(xí)。
第二部分是基于目標(biāo)的語言 - 圖像價值學(xué)習(xí)。
第三部分介紹了使用大型語言模型來規(guī)劃機(jī)器人任務(wù),其中包括通過語言指令來說明任務(wù)以及使用語言模型生成任務(wù)規(guī)劃的代碼。
第四部分是用于決策的上下文學(xué)習(xí)(ICL)。
接下來是機(jī)器人 Transformer。
第六部分則是開放詞匯庫的機(jī)器人導(dǎo)航和操作。
表 2 給出了一些特定于機(jī)器人的基礎(chǔ)模型,其中報告了模型的大小和架構(gòu)、預(yù)訓(xùn)練任務(wù)、推理時間和硬件設(shè)置。
感知
與周圍環(huán)境交互的機(jī)器人會接收不同模態(tài)的感官信息,比如圖像、視頻、音頻和語言。這種高維數(shù)據(jù)對機(jī)器人在環(huán)境中的理解、推理和互動而言至關(guān)重要。基礎(chǔ)模型可以將這些高維輸入轉(zhuǎn)換成容易解讀和操作的抽象結(jié)構(gòu)化表征。尤其是多模態(tài)基礎(chǔ)模型可讓機(jī)器人將不同感官的輸入整合成一個統(tǒng)一的表征,其中包含語義、空間、時間和可供性信息。這些多模態(tài)模型需要跨模態(tài)的交互,通常需要對齊不同模態(tài)的元素來確保一致性和互相對應(yīng)。比如圖像描述任務(wù)就需要文本和圖像數(shù)據(jù)對齊。
這一節(jié)將關(guān)注與機(jī)器人感知相關(guān)的一系列任務(wù),這些任務(wù)可使用基礎(chǔ)模型來對齊模態(tài),從而獲得提升。其中的重點是視覺和語言。
這一節(jié)分為五部分,首先是開放詞匯庫的目標(biāo)檢測和 3D 分類,然后是開放詞匯庫的語義分割,接下來是開放詞匯庫的 3D 場景和目標(biāo)表征,再然后是學(xué)習(xí)到的功能可供性,最后是預(yù)測模型。
具身 AI
近段時間,有研究表明 LLM 可以成功用于具身 AI 領(lǐng)域,其中「具身(embodied)」通常是指在世界模擬器中的虛擬具身,而非具有實體機(jī)器人身體。
這方面已經(jīng)出現(xiàn)了一些有趣的框架、數(shù)據(jù)集和模型。其中尤其值得一提的是將 Minecraft 游戲用作訓(xùn)練具身智能體的平臺。舉個例子,Voyager 使用了 GPT-4 來引導(dǎo)智能體探索 Minecraft 環(huán)境。其能通過上下文 prompt 設(shè)計來與 GPT-4 互動,而無需對 GPT-4 的模型參數(shù)進(jìn)行微調(diào)。
機(jī)器人學(xué)習(xí)方面的一個重要研究方向是強(qiáng)化學(xué)習(xí),也有研究者在嘗試通過基礎(chǔ)模型來為強(qiáng)化學(xué)習(xí)設(shè)計獎勵。
使用基礎(chǔ)模型輔助機(jī)器人執(zhí)行高層規(guī)劃自然也早有研究者嘗試。此外也有研究者在嘗試將基于思維鏈的推理和動作生成方法用于具身智能體。
挑戰(zhàn)和未來方向
這一節(jié)會給出將基礎(chǔ)模型用于機(jī)器人的相關(guān)挑戰(zhàn)。該團(tuán)隊也會探索可望解決這些挑戰(zhàn)的未來研究方向。
第一個挑戰(zhàn)是克服訓(xùn)練用于機(jī)器人的基礎(chǔ)模型時的數(shù)據(jù)稀缺問題,其中包括:
1. 使用非結(jié)構(gòu)化游戲數(shù)據(jù)和未標(biāo)注的人類視頻來擴(kuò)展機(jī)器人學(xué)習(xí)
2. 使用圖像修復(fù)(Inpainting)來增強(qiáng)數(shù)據(jù)
3. 克服訓(xùn)練 3D 基礎(chǔ)模型時的缺少 3D 數(shù)據(jù)的問題
4. 通過高保真模擬來生成合成數(shù)據(jù)
5. 使用 VLM 進(jìn)行數(shù)據(jù)增強(qiáng)
6. 機(jī)器人的物理技能受限于技能的分布
第二個挑戰(zhàn)則與實時性能有關(guān),其中關(guān)鍵的是基礎(chǔ)模型的推理時間。
第三個挑戰(zhàn)涉及到多模態(tài)表征的局限性。
第四個挑戰(zhàn)則是如何量化不同層級的不確定性的問題,比如實例層面和分布層面,另外還涉及到如何校準(zhǔn)以及應(yīng)對分布移位的難題。
第五個挑戰(zhàn)涉及到安全評估,包括部署之前的安全測試和運行時的監(jiān)控和對分布外情況的檢測。
第六個挑戰(zhàn)則涉及到如何選擇:使用現(xiàn)有的基礎(chǔ)模型還是為機(jī)器人構(gòu)建新的基礎(chǔ)模型?
第七個挑戰(zhàn)涉及到機(jī)器人設(shè)置中的高度可變性。
第八個挑戰(zhàn)是如何在機(jī)器人設(shè)置中進(jìn)行基準(zhǔn)評估以及保證可復(fù)現(xiàn)性。
更多研究細(xì)節(jié),可參考原論文。