













Istio 可觀測性之指標,指標提供了一種以聚合的方式監控和理解行為的方法

Istio 為網格內所有的服務通信生成詳細的遙測數據。這種遙測技術提供了服務行為的可觀測性,使運維人員能夠排查故障、維護和優化應用程序,而不會給開發人員帶來其他額外的負擔。通過 Istio,運維人員可以全面了解到受監控的服務如何與其他服務以及 Istio 組件進行交互。
Istio 生成以下類型的遙測數據,以提供對整個服務網格的可觀測性:
- Metrics(指標):Istio 基于 4 個監控的黃金標識(延遲、流量、錯誤、飽和)生成了一系列服務指標,Istio 還為網格控制平面提供了更詳細的指標。除此以外還提供了一組默認的基于這些指標的網格監控儀表板。
- Tracing(分布式追蹤):Istio 為每個服務生成分布式追蹤 span,運維人員可以理解網格內服務的依賴和調用流程。
- Log(訪問日志):當流量流入網格中的服務時,Istio 可以生成每個請求的完整記錄,包括源和目標的元數據,該信息使運維人員能夠將服務行為的審查控制到單個工作負載實例的級別。
接下來我們將分別來學習 Istio 的指標、分布式追蹤和訪問日志是如何工作的。
指標
指標提供了一種以聚合的方式監控和理解行為的方法。為了監控服務行為,Istio 為服務網格中所有出入網格,以及網格內部的服務流量都生成了指標,這些指標提供了關于行為的信息,例如總流量、錯誤率和請求響應時間。除了監控網格中服務的行為外,監控網格本身的行為也很重要。Istio 組件還可以導出自身內部行為的指標,以提供對網格控制平面的功能和健康情況的洞察能力。
指標類別
整體上 Istio 的指標可以分成 3 個級別:代理級別、服務級別、控制平面級別。
代理級別指標
Istio 指標收集從 Envoy Sidecar 代理開始,每個代理為通過它的所有流量(入站和出站)生成一組豐富的指標。代理還提供關于它本身管理功能的詳細統計信息,包括配置信息和健康信息。
Envoy 生成的指標提供了資源(例如監聽器和集群)粒度上的網格監控。因此,為了監控 Envoy 指標,需要了解網格服務和 Envoy 資源之間的連接。
Istio 允許運維人員在每個工作負載實例上選擇生成和收集哪些 Envoy 指標。默認情況下,Istio 只支持 Envoy 生成的統計數據的一小部分,以避免依賴過多的后端服務,還可以減少與指標收集相關的 CPU 開銷。但是運維人員可以在需要時輕松地擴展收集到的代理指標數據。這樣我們可以有針對性地調試網絡行為,同時降低了跨網格監控的總體成本。
服務級別指標
除了代理級別指標之外,Istio 還提供了一組用于監控服務通信的面向服務的指標。這些指標涵蓋了四個基本的服務監控需求:延遲、流量、錯誤和飽和情況。而且 Istio 還自帶了一組默認的儀表板,用于監控基于這些指標的服務行為。默認情況下,標準 Istio 指標會導出到 Prometheus。而且服務級別指標的使用完全是可選的,運維人員可以根據自身的需求來選擇關閉指標的生成和收集。
控制平面指標
另外 Istio 控制平面還提供了一組自我監控指標。這些指標允許監控 Istio 自己的行為。
通過 Prometheus 查詢指標
Istio 默認使用 Prometheus 來收集和存儲指標。Prometheus 是一個開源的系統監控和警報工具包,它可以從多個源收集指標,并允許運維人員通過 PromQL 查詢語言來查詢收集到的指標。
首先要確保 Istio 的 prometheus 組件已經啟用,如果沒有啟用可以通過以下命令啟用:
kubectl apply -f samples/addons上面的命令會安裝 Kiali,包括 Prometheus、Grafana 以及 jaeger。當然這僅僅只能用于測試環境,在生產環境可以單獨安裝 Prometheus 進行有針對性的配置優化。
安裝后可以通過以下命令查看 Prometheus 服務狀態:
$ kubectl get svc prometheus -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus ClusterIP 10.106.228.196 <none> 9090/TCP 25d
$ kubectl get pods -n istio-system -l app=prometheus
NAME READY STATUS RESTARTS AGE
prometheus-5d5d6d6fc-2gtxm 2/2 Running 0 25d然后我們還是以 Bookinfo 應用為例,首先在瀏覽器中訪問 http://$GATEWAY_URL/productpage 應用,然后我們就可以打開 Prometheus UI 來查看指標了。在 Kubernetes 環境中,執行如下命令就可以打開 Prometheus UI:
istioctl dashboard prometheus
# 也可以創建 Ingress 或者 Gateway 來訪問 Prometheus UI打開后我們可以在頁面中隨便查詢一個指標,比如我們查詢 istio_requests_total 指標,如下所示:
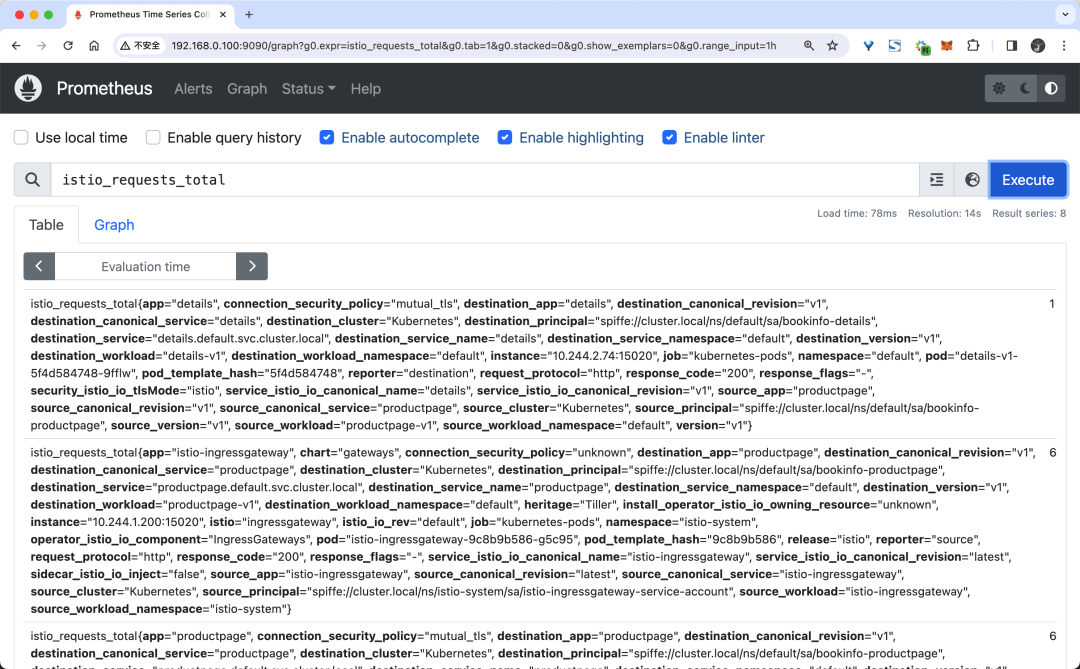
查詢指標
istio_requests_total 這是一個 COUNTER 類型的指標,用于記錄 Istio 代理處理的總請求數。
當然然后可以根據自己需求來編寫 promql 語句進行查詢,比如查詢 productpage 服務的總次數,可以用下面的語句:
istio_requests_total{destination_service="productpage.default.svc.cluster.local"}查詢 reviews 服務 v3 版本的總次數:
istio_requests_total{destination_service="reviews.default.svc.cluster.local", destination_versinotallow="v3"}該查詢返回所有請求 reviews 服務 v3 版本的當前總次數。
過去 5 分鐘 productpage 服務所有實例的請求頻次:
rate(istio_requests_total{destination_service=~"productpage.*", response_code="200"}[5m])在 Graph 選項卡中,可以看到查詢結果的圖形化表示。
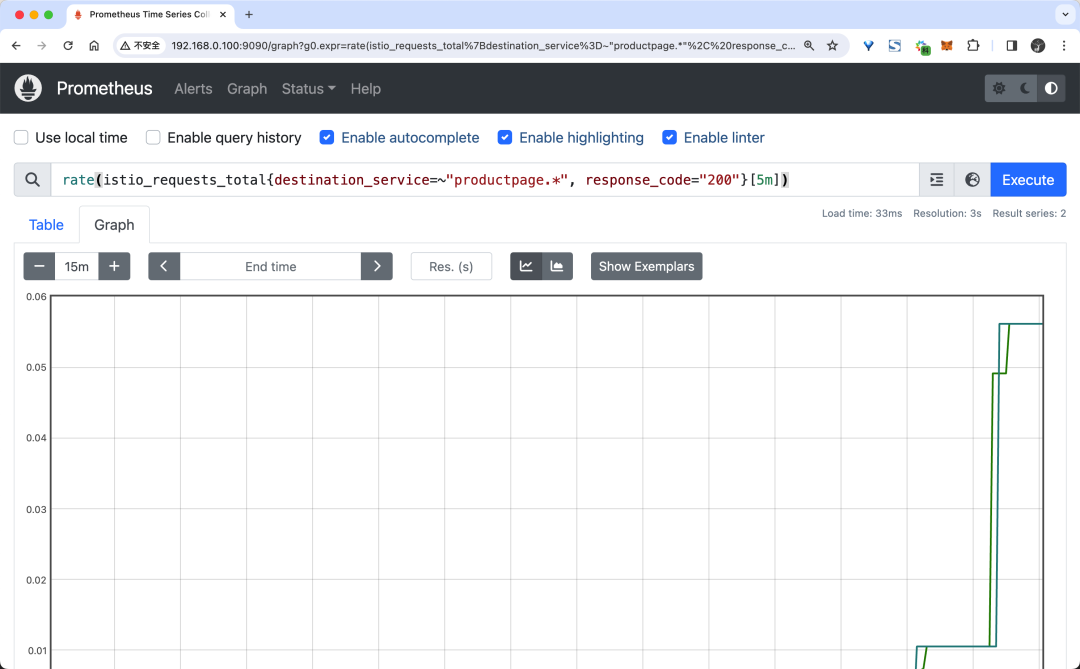
Graph
對于 PromQL 語句的使用可以參考官方文檔 Prometheus Querying Basics,或者我們的 《Prometheus 入門到實戰》課程,這并不是我們這里的重點,所以就不再詳細介紹了。
雖然我們這里并沒有做任何的配置,但是 Istio 默認已經為我們收集了一些指標,所以我們可以直接查詢到這些指標了。
使用 Grafana 可視化指標
Prometheus 提供了一個基本的 UI 來查詢指標,但是它并不是一個完整的監控系統,更多的時候我們可以使用 Grafana 來可視化指標。
首先同樣要保證 Istio 的 grafana 組件已經啟用,如果沒有啟用可以通過以下命令啟用:
kubectl apply -f samples/addons并且要保證 Prometheus 服務正在運行,服務安裝后可以通過下面的命令來查看狀態:
$ kubectl -n istio-system get svc grafana
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 10.96.197.74 <none> 3000/TCP 25d
$ kubectl -n istio-system get pods -l app=grafana
NAME READY STATUS RESTARTS AGE
grafana-5f9b8c6c5d-jv65v 1/1 Running 0 25d然后我們可以通過以下命令來打開 Grafana UI:
istioctl dashboard grafana
# 也可以創建 Ingress 或者 Gateway 來訪問 Grafana然后我們就可以在瀏覽器中打開 Grafana UI 了,默認情況下 Grafana 已經配置了 Prometheus 數據源,所以我們可以直接使用 Prometheus 數據源來查詢指標。
數據源
此外 Grafana 也已經內置了 Istio 的一些儀表盤,我們可以直接使用這些儀表盤來查看指標,比如我們可以打開 Istio Mesh Dashboard 儀表盤來查看網格的指標:
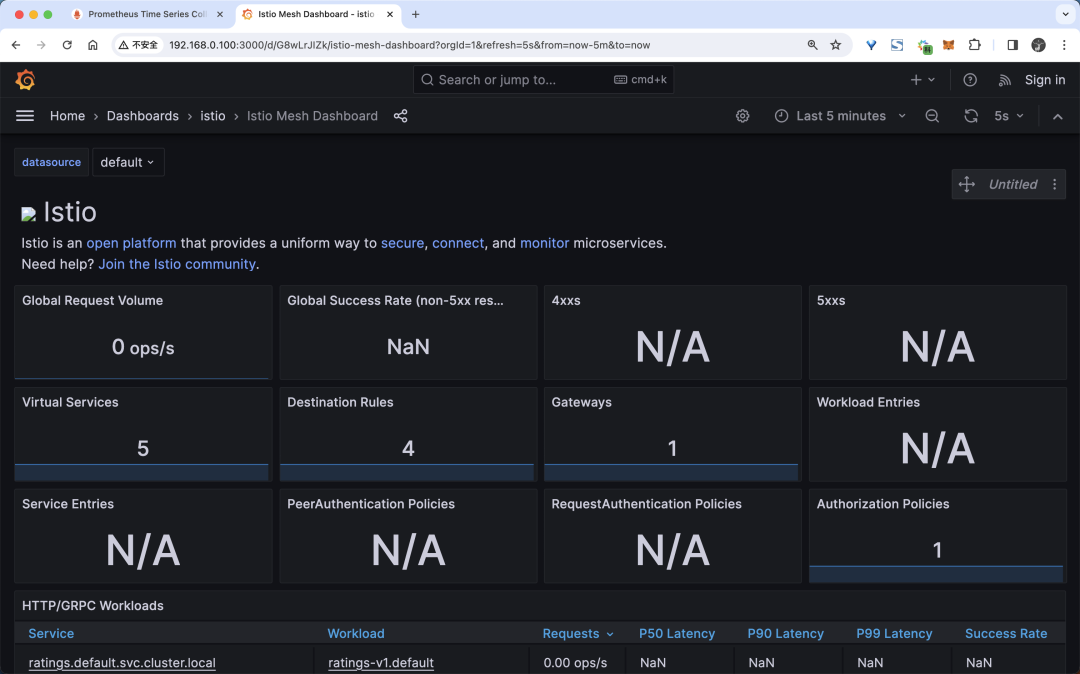
Dashboard
從圖中可以看出現在有一些數據,但是并不是很多,這是因為我們現在還沒產生一些流量請求,下面我們可以用下面的命令向 productpage 服務發送 100 個請求:
for i in $(seq 1 100); do curl -s -o /dev/null "http://$GATEWAY_URL/productpage"; done然后我們再次查看 Istio Mesh Dashboard,它應該反映所產生的流量,如下所示:

Mesh Dashboard
當然除此之外我們也可以查看到 Service 或者 Workload 的指標,比如我們可以查看 productpage 工作負載的指標:
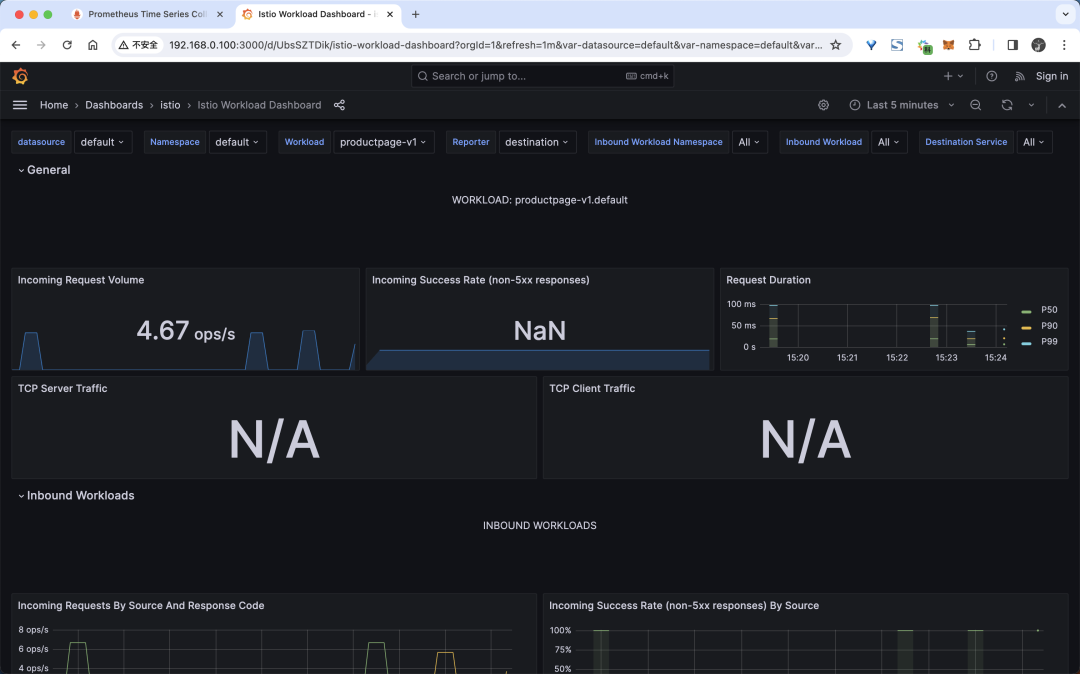
workload dashboard
這里給出了每一個工作負載,以及該工作負載的入站工作負載(將請求發送到該工作負載的工作負載)和出站服務(此工作負載向其發送請求的服務)的詳細指標。
Istio Dashboard 主要包括三個主要部分:
- 網格摘要視圖:這部分提供網格的全局摘要視圖,并顯示網格中(HTTP/gRPC 和 TCP)的工作負載。
- 單獨的服務視圖:這部分提供關于網格中每個單獨的(HTTP/gRPC 和 TCP)服務的請求和響應指標。這部分也提供關于該服務的客戶端和服務工作負載的指標。
- 單獨的工作負載視圖:這部分提供關于網格中每個單獨的(HTTP/gRPC 和 TCP)工作負載的請求和響應指標。這部分也提供關于該工作負載的入站工作負載和出站服務的指標。
指標采集原理
從上面的例子我們可以看出當我們安裝了 Istio 的 Prometheus 插件后,Istio 就會自動收集一些指標,但是我們并沒有做任何的配置,那么 Istio 是如何收集指標的呢?如果我們想使用我們自己的 Prometheus 來收集指標,那么我們應該如何配置呢?
首先我們需要去查看下 Istio 的 Prometheus 插件的配置,通過 cat samples/addons/prometheus.yaml 命令查看配置文件,如下所示:
# Source: prometheus/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-19.6.1
heritage: Helm
name: prometheus
namespace: istio-system
spec:
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
selector:
component: "server"
app: prometheus
release: prometheus
sessionAffinity: None
type: "ClusterIP"
---
# Source: prometheus/templates/deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-19.6.1
heritage: Helm
name: prometheus
namespace: istio-system
spec:
selector:
matchLabels:
component: "server"
app: prometheus
release: prometheus
replicas: 1
strategy:
type: Recreate
rollingUpdate: null
template:
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-19.6.1
heritage: Helm
sidecar.istio.io/inject: "false"
spec:
enableServiceLinks: true
serviceAccountName: prometheus
containers:
- name: prometheus-server-configmap-reload
image: "jimmidyson/configmap-reload:v0.8.0"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://127.0.0.1:9090/-/reload
resources: {}
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
- name: prometheus-server
image: "prom/prometheus:v2.41.0"
imagePullPolicy: "IfNotPresent"
args:
- --storage.tsdb.retention.time=15d
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
scheme: HTTP
initialDelaySeconds: 0
periodSeconds: 5
timeoutSeconds: 4
failureThreshold: 3
successThreshold: 1
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 15
timeoutSeconds: 10
failureThreshold: 3
successThreshold: 1
resources: {}
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: /data
subPath: ""
dnsPolicy: ClusterFirst
securityContext:
fsGroup: 65534
runAsGroup: 65534
runAsNonRoot: true
runAsUser: 65534
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus
- name: storage-volume
emptyDir: {}
# 省略了部分配置從上面的資源清單中可以看出 Prometheus 服務的核心配置文件為 --config.file=/etc/config/prometheus.yml,而該配置文件是通過上面的 prometheus 這個 ConfigMap 以 volume 形式掛載到容器中的,所以我們重點是查看這個 ConfigMap 的配置,如下所示:
# Source: prometheus/templates/cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-19.6.1
heritage: Helm
name: prometheus
namespace: istio-system
data:
allow-snippet-annotations: "false"
alerting_rules.yml: |
{}
alerts: |
{}
prometheus.yml: |
global:
evaluation_interval: 1m
scrape_interval: 15s
scrape_timeout: 10s
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
- /etc/config/rules
- /etc/config/alerts
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/$1/proxy/metrics
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- honor_labels: true
job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: drop
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape_slow
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (.+?)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+)
replacement: __param_$1
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: service
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node
- honor_labels: true
job_name: kubernetes-service-endpoints-slow
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape_slow
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (.+?)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+)
replacement: __param_$1
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: service
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node
scrape_interval: 5m
scrape_timeout: 30s
- honor_labels: true
job_name: prometheus-pushgateway
kubernetes_sd_configs:
- role: service
relabel_configs:
- action: keep
regex: pushgateway
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- honor_labels: true
job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module:
- http_2xx
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: service
- honor_labels: true
job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: drop
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape_slow
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (\d+);(([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})
replacement: '[$2]:$1'
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_port
- __meta_kubernetes_pod_ip
target_label: __address__
- action: replace
regex: (\d+);((([0-9]+?)(\.|$)){4})
replacement: $2:$1
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_port
- __meta_kubernetes_pod_ip
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+)
replacement: __param_$1
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: drop
regex: Pending|Succeeded|Failed|Completed
source_labels:
- __meta_kubernetes_pod_phase
- honor_labels: true
job_name: kubernetes-pods-slow
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape_slow
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (\d+);(([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})
replacement: '[$2]:$1'
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_port
- __meta_kubernetes_pod_ip
target_label: __address__
- action: replace
regex: (\d+);((([0-9]+?)(\.|$)){4})
replacement: $2:$1
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_port
- __meta_kubernetes_pod_ip
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+)
replacement: __param_$1
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: drop
regex: Pending|Succeeded|Failed|Completed
source_labels:
- __meta_kubernetes_pod_phase
scrape_interval: 5m
scrape_timeout: 30s
recording_rules.yml: |
{}
rules: |
{}
---這個配置文件中描述了 6 個指標抓取任務的配置:
- prometheus:抓取 Prometheus 服務自身的指標。
- kubernetes-apiservers:抓取 Kubernetes API 服務器的指標。
- kubernetes-nodes:抓取 Kubernetes 節點的指標。
- kubernetes-nodes-cadvisor:抓取 Kubernetes 節點的 cadvisor 指標,主要包括容器的 CPU、內存、網絡、磁盤等指標。
- kubernetes-service-endpoints:抓取 Kubernetes 服務端點的指標。
- kubernetes-pods:抓取 Kubernetes Pod 的指標。
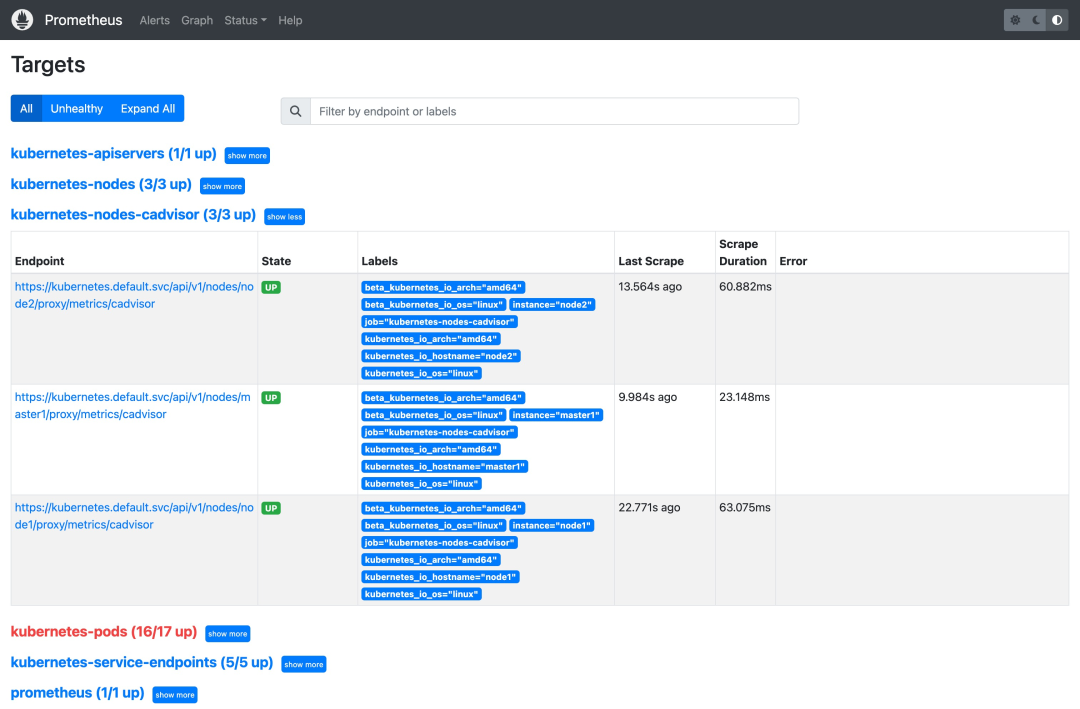
prometheus 配置
這里我們可以重點關注下 kubernetes-pods 這個指標抓取任務的配置,因為我們大部分的指標數據都是通過 Pod 的 Envoy Sidecar 來提供的。
從配置上可以看到這是基于 pod 的服務發現方式:
- 首先只會保留 __meta_kubernetes_pod_annotation_prometheus_io_scrape 這個源標簽為 true 的指標數據,這個源標簽表示的是如果 Pod 的 annotation 注解中有 prometheus.io/scrape 標簽,且值為 true,則會保留該指標數據,否則會丟棄該指標數據。
- 然后根據 prometheus.io/scheme 注解來配置協議為 http 或者 https。
- 根據 prometheus.io/path 注解來配置抓取路徑。
- 根據 prometheus.io/port 注解來配置抓取端口。
- 將 prometheus.io/param 注解的值映射為 Prometheus 的標簽。
- 然后還會將 pod 的標簽通過 labelmap 映射為 Prometheus 的標簽;最后還會將 pod 的 namespace 和 pod 的名稱映射為 Prometheus 的標簽。
- 最后需要判斷 Pod 的 phase 狀態,只有當 Pod 的 phase 狀態為 Running 時才會保留該指標數據,否則會丟棄該指標數據。
比如我們查詢 istio_requests_total{app="productpage", destination_app="details"} 這個指標,如下所示:
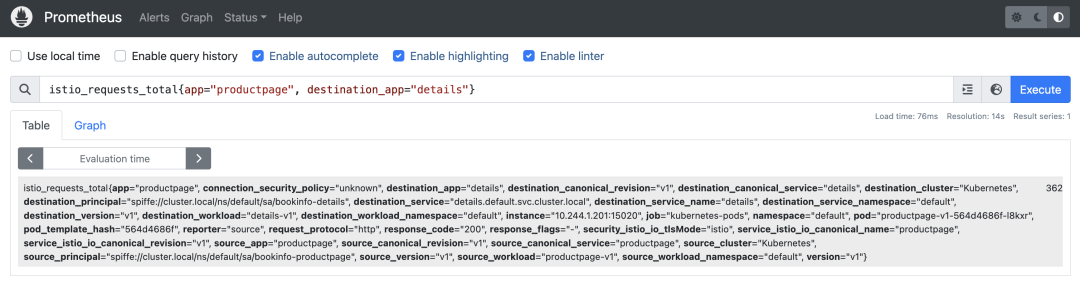
測試
該查詢語句的查詢結果為:
istio_requests_total{
app="details",
connection_security_policy="mutual_tls",
destination_app="details",
destination_canonical_revisinotallow="v1",
destination_canonical_service="details",
destination_cluster="Kubernetes",
destination_principal="spiffe://cluster.local/ns/default/sa/bookinfo-details",
destination_service="details.default.svc.cluster.local",
destination_service_name="details",
destination_service_namespace="default",
destination_versinotallow="v1",
destination_workload="details-v1",
destination_workload_namespace="default",
instance="10.244.2.74:15020",
job="kubernetes-pods",
namespace="default",
pod="details-v1-5f4d584748-9fflw",
pod_template_hash="5f4d584748",
reporter="destination",
request_protocol="http",
response_code="200",
response_flags="-",
security_istio_io_tlsMode="istio",
service_istio_io_canonical_name="details",
service_istio_io_canonical_revisinotallow="v1",
source_app="productpage",
source_canonical_revisinotallow="v1",
source_canonical_service="productpage",
source_cluster="Kubernetes",
source_principal="spiffe://cluster.local/ns/default/sa/bookinfo-productpage",
source_versinotallow="v1",
source_workload="productpage-v1",
source_workload_namespace="default",
versinotallow="v1"
} 362該查詢表示的是從 productpage 服務到 details 服務的請求總次數,從查詢結果可以看出該指標就是來源于 job="kubernetes-pods" 這個指標抓取任務,那說明這個指標數據是通過服務發現方式從 Pod 中抓取的。我們可以查看下 productpage Pod 的信息,如下所示:
$ kubectl get pods productpage-v1-564d4686f-l8kxr -oyaml
apiVersion: v1
kind: Pod
metadata:
annotations:
istio.io/rev: default
kubectl.kubernetes.io/default-container: productpage
kubectl.kubernetes.io/default-logs-container: productpage
prometheus.io/path: /stats/prometheus
prometheus.io/port: "15020"
prometheus.io/scrape: "true"
sidecar.istio.io/status: '{"initContainers":["istio-init"],"containers":["istio-proxy"],"volumes":["workload-socket","credential-socket","workload-certs","istio-envoy","istio-data","istio-podinfo","istio-token","istiod-ca-cert"],"imagePullSecrets":null,"revision":"default"}'
labels:
app: productpage
pod-template-hash: 564d4686f
security.istio.io/tlsMode: istio
service.istio.io/canonical-name: productpage
service.istio.io/canonical-revision: v1
version: v1
name: productpage-v1-564d4686f-l8kxr
namespace: default
spec:
containers:
- image: docker.io/istio/examples-bookinfo-productpage-v1:1.18.0
imagePullPolicy: IfNotPresent
# ......我們從上面的資源清單中可以看到該 Pod 包含如下幾個注解:
- prometheus.io/path: /stats/prometheus
- prometheus.io/port: "15020"
- prometheus.io/scrape: "true"
這些注解就是用來配置 Prometheus 服務發現的,其中 prometheus.io/scrape: "true" 表示該 Pod 的指標數據是需要被抓取的,而 prometheus.io/path: /stats/prometheus 和 prometheus.io/port: "15020" 則是用來配置抓取路徑和抓取端口的,當 Prometheus 發現這個 Pod 后根據配置就可以通過 <pod ip>:15020/stats/prometheus 這個路徑來抓取該 Pod 的指標數據了,這個路徑就是 Envoy Sidecar 提供的 /stats/prometheus 路徑,而 15020 則是 Envoy Sidecar 的端口,這個端口是通過 istio-proxy 這個容器配置的靜態監聽器暴露出來的。
當然定義的標簽也被映射為 Prometheus 的標簽了,從結果來看除了 Pod 的這些標簽之外,Envoy Sidecar 也會自己添加很多相關標簽,主要是標明 destination 和 source 的信息,有了這些標簽我們就可以很方便的對指標進行查詢了。Envoy Sidecar 自行添加的一些主要標簽如下所示:
- reporter:標識請求指標的上報端,如果指標由服務端 Istio 代理上報,則設置為 destination,如果指標由客戶端 Istio 代理或網關上報,則設置為 source。
- source_workload:標識源工作負載的名稱,如果缺少源信息,則標識為 unknown。
- source_workload_namespace:標識源工作負載的命名空間,如果缺少源信息,則標識為 unknown。
- source_principal:標識流量源的對等主體,當使用對等身份驗證時設置。
- source_app:根據源工作負載的 app 標簽標識源應用程序,如果源信息丟失,則標識為 unknown。
- source_version:標識源工作負載的版本,如果源信息丟失,則標識為 unknown。
- destination_workload:標識目標工作負載的名稱,如果目標信息丟失,則標識為 unknown。
- destination_workload_namespace:標識目標工作負載的命名空間,如果目標信息丟失,則標識為 unknown。
- destination_principal:標識流量目標的對等主體,使用對等身份驗證時設置。
- destination_app:它根據目標工作負載的 app 標簽標識目標應用程序,如果目標信息丟失,則標識為 unknown。
- destination_version:標識目標工作負載的版本,如果目標信息丟失,則標識為 unknown。
- destination_service:標識負責傳入請求的目標服務主機,例如:details.default.svc.cluster.local。
- destination_service_name:標識目標服務名稱,例如 details。
- destination_service_namespace:標識目標服務的命名空間。
- request_protocol:標識請求的協議,設置為請求或連接協議。
- response_code:標識請求的響應代碼,此標簽僅出現在 HTTP 指標上。
- connection_security_policy:標識請求的服務認證策略,當 Istio 使用安全策略來保證通信安全時,如果指標由服務端 Istio 代理上報,則將其設置為 mutual_tls。如果指標由客戶端 Istio 代理上報,由于無法正確填充安全策略,因此將其設置為 unknown。
- response_flags:有關來自代理的響應或連接的其他詳細信息。
- Canonical Service:工作負載屬于一個 Canonical 服務,而 Canonical 服務卻可以屬于多個服務。Canonical 服務具有名稱和修訂版本,因此會產生以下標簽:
- source_canonical_service
- source_canonical_revision
- destination_canonical_service
- destination_canonical_revision
- destination_cluster:目標工作負載的集群名稱,這是由集群安裝時的 global.multiCluster.clusterName 設置的。
- source_cluster:源工作負載的集群名稱,這是由集群安裝時的 global.multiCluster.clusterName 設置的。
- grpc_response_status: 這標識了 gRPC 的響應狀態,這個標簽僅出現在 gRPC 指標上。
對于 Istio 來說包括 COUNTER 和 DISTRIBUTION 兩種指標類型,這兩種指標類型對應我們比較熟悉的計數器和直方圖。
對于 HTTP,HTTP/2 和 GRPC 通信,Istio 生成以下指標:
- 請求數 (istio_requests_total): 這都是一個 COUNTER 類型的指標,用于記錄 Istio 代理處理的總請求數。
- 請求時長 (istio_request_duration_milliseconds): 這是一個 DISTRIBUTION 類型的指標,用于測量請求的持續時間。
- 請求體大小 (istio_request_bytes): 這是一個 DISTRIBUTION 類型的指標,用來測量 HTTP 請求主體大小。
- 響應體大小 (istio_response_bytes): 這是一個 DISTRIBUTION 類型的指標,用來測量 HTTP 響應主體大小。
- gRPC 請求消息數 (istio_request_messages_total): 這是一個 COUNTER 類型的指標,用于記錄從客戶端發送的 gRPC 消息總數。
- gRPC 響應消息數 (istio_response_messages_total): 這是一個 COUNTER 類型的指標,用于記錄從服務端發送的 gRPC 消息總數。
對于 TCP 流量,Istio 生成以下指標:
- TCP 發送字節大小 (istio_tcp_sent_bytes_total): 這是一個 COUNTER 類型的指標,用于測量在 TCP 連接情況下響應期間發送的總字節數。
- TCP 接收字節大小 (istio_tcp_received_bytes_total): 這是一個 COUNTER 類型的指標,用于測量在 TCP 連接情況下請求期間接收到的總字節數。
- TCP 已打開連接數 (istio_tcp_connections_opened_total): 這是一個 COUNTER 類型的指標,用于記錄 TCP 已打開的連接總數。
- TCP 已關閉連接數 (istio_tcp_connections_closed_total): 這是一個 COUNTER 類型的指標,用于記錄 TCP 已關閉的連接總數。
當我們了解了 Istio 指標數據采集的原理后,我們就可以根據自身的需求來定制了,比如在我們的監控系統采樣的是 Prometheus Operator 方式,那么也應該知道該如何來配置采集這些指標數據了。
自定義指標
除了 Istio 自帶的指標外,我們還可以自定義指標,要自定指標需要用到 Istio 提供的 Telemetry API,該 API 能夠靈活地配置指標、訪問日志和追蹤數據。Telemetry API 現在已經成為 Istio 中的主流 API。
需要注意的是,Telemetry API 無法與 EnvoyFilter 一起使用。請查看此問題 issue。
從 Istio 版本 1.18 版本開始,Prometheus 的 EnvoyFilter 默認不會被安裝, 而是通過 meshConfig.defaultProviders 來啟用它,我們應該使用 Telemetry API 來進一步定制遙測流程,新的 Telemetry API 不但語義更加清晰,功能也一樣沒少。對于 Istio 1.18 之前的版本,應該使用以下的 IstioOperator 配置進行安裝:
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
values:
telemetry:
enabled: true
v2:
enabled: falseTelemetry 資源對象的定義如下所示:
$ kubectl explain Telemetry.spec
GROUP: telemetry.istio.io
KIND: Telemetry
VERSION: v1alpha1
FIELD: spec <Object>
DESCRIPTION:
Telemetry configuration for workloads. See more details at:
https://istio.io/docs/reference/config/telemetry.html
FIELDS:
accessLogging <[]Object>
Optional.
metrics <[]Object>
Optional.
selector <Object>
Optional.
tracing <[]Object>
Optional.可以看到 Telemetry 資源對象包含了 accessLogging、metrics、selector 和 tracing 四個字段,其中 accessLogging 和 tracing 字段用于配置訪問日志和追蹤數據,而 metrics 字段用于配置指標數據,selector 字段用于配置哪些工作負載需要采集指標數據。
我們這里先來看下 metrics 字段的配置,該字段的定義如下所示:
$ kubectl explain Telemetry.spec.metrics
GROUP: telemetry.istio.io
KIND: Telemetry
VERSION: v1alpha1
FIELD: metrics <[]Object>
DESCRIPTION:
Optional.
FIELDS:
overrides <[]Object>
Optional.
providers <[]Object>
Optional.
reportingInterval <string>
Optional.可以看到 metrics 字段包含了 overrides、providers 和 reportingInterval 三個字段。
- overrides 字段用于配置指標數據的采集方式。
- providers 字段用于配置指標數據的提供者,這里一般配置為 prometheus。
- reportingInterval 字段用于配置指標數據的上報間隔,可選的。目前僅支持 TCP 度量,但將來可能會將其用于長時間的 HTTP 流。默認持續時間為 5 秒。
刪除標簽
比如以前需要在 Istio 配置的 meshConfig 部分配置遙測,這種方式不是很方便。比如我們想從 Istio 指標中刪除一些標簽以減少基數,那么你的配置中可能有這樣一個部分:
# istiooperator.yaml
telemetry:
enabled: true
v2:
enabled: true
prometheus:
enabled: true
configOverride:
outboundSidecar:
debug: false
stat_prefix: istio
metrics:
- tags_to_remove:
- destination_canonical_service
...現在我們可以通過 Telemetry API 來配置,如下所示:
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: remove-tags
namespace: istio-system
spec:
metrics:
- providers:
- name: prometheus # 指定指標數據的提供者
overrides:
- match: # 提供覆蓋的范圍,可用于選擇個別指標,以及生成指標的工作負載模式(服務器和/或客戶端)。如果未指定,則overrides 將應用于兩種操作模式(客戶端和服務器)的所有指標。
metric: ALL_METRICS # Istio 標準指標之一
mode: CLIENT_AND_SERVER # 控制選擇的指標生成模式:客戶端和/或服務端。
tagOverrides: # 要覆蓋的標簽列表
destination_canonical_service:
operation: REMOVE
# disabled: true # 是否禁用指標在上面的 Telemetry 資源對象中我們指定了一個 metrics 字段,表示用來自定義指標的,然后通過 providers.name 字段指定指標數據的提供者為 prometheus,然后最重要的是 overrides 字段,用于配置指標數據的采集方式。
其中 overrides.match.metric 字段用來指定要覆蓋的 Istio 標準指標,支持指標如下所示:
名稱 | 描述 |
ALL_METRICS | 使用這個枚舉表示應將覆蓋應用于所有 Istio 默認指標。 |
REQUEST_COUNT | 對應用程序的請求計數器,適用于 HTTP、HTTP/2 和 GRPC 流量。Prometheus 提供商將此指標導出為:istio_requests_total。Stackdriver 提供商將此指標導出為:istio.io/service/server/request_count(服務器模式)istio.io/service/client/request_count(客戶端模式) |
REQUEST_DURATION | 請求持續時間的直方圖,適用于 HTTP、HTTP/2 和 GRPC 流量。Prometheus 提供商將此指標導出為:istio_request_duration_milliseconds。Stackdriver 提供商將此指標導出為:istio.io/service/server/response_latencies(服務器模式)istio.io/service/client/roundtrip_latencies(客戶端模式) |
REQUEST_SIZE | 請求體大小的直方圖,適用于 HTTP、HTTP/2 和 GRPC 流量。Prometheus 提供商將此指標導出為:istio_request_bytes。Stackdriver 提供商將此指標導出為:istio.io/service/server/request_bytes(服務器模式)istio.io/service/client/request_bytes(客戶端模式) |
RESPONSE_SIZE | 響應體大小的直方圖,適用于 HTTP、HTTP/2 和 GRPC 流量。Prometheus 提供商將此指標導出為:istio_response_bytes。Stackdriver 提供商將此指標導出為:istio.io/service/server/response_bytes(服務器模式)istio.io/service/client/response_bytes(客戶端模式) |
TCP_OPENED_CONNECTIONS | 工作負載生命周期中打開的 TCP 連接計數器。Prometheus 提供商將此指標導出為:istio_tcp_connections_opened_total。Stackdriver 提供商將此指標導出為:istio.io/service/server/connection_open_count(服務器模式)istio.io/service/client/connection_open_count(客戶端模式) |
TCP_CLOSED_CONNECTIONS | 工作負載生命周期中關閉的 TCP 連接計數器。Prometheus 提供商將此指標導出為:istio_tcp_connections_closed_total。Stackdriver 提供商將此指標導出為:istio.io/service/server/connection_close_count(服務器模式)istio.io/service/client/connection_close_count(客戶端模式) |
TCP_SENT_BYTES | TCP 連接期間發送的響應字節計數器。Prometheus 提供商將此指標導出為:istio_tcp_sent_bytes_total。Stackdriver 提供商將此指標導出為:istio.io/service/server/sent_bytes_count(服務器模式)istio.io/service/client/sent_bytes_count(客戶端模式) |
TCP_RECEIVED_BYTES | TCP 連接期間接收的請求字節計數器。Prometheus 提供商將此指標導出為:istio_tcp_received_bytes_total。Stackdriver 提供商將此指標導出為:istio.io/service/server/received_bytes_count(服務器模式)istio.io/service/client/received_bytes_count(客戶端模式) |
GRPC_REQUEST_MESSAGES | 每發送一個 gRPC 消息時遞增的客戶端計數器。Prometheus 提供商將此指標導出為:istio_request_messages_total |
GRPC_RESPONSE_MESSAGES | 每發送一個 gRPC 消息時遞增的服務器計數器。Prometheus 提供商將此指標導出為:istio_response_messages_total |
比如我們這里配置的指標為 ALL_METRICS 則表示要覆蓋所有的 Istio 標準指標。
overrides.match.mode 則表示選擇網絡流量中底層負載的角色,如果負載是流量的目標(從負載的角度看,流量方向是入站),則將其視為作為 SERVER 運行。如果負載是網絡流量的源頭,則被視為處于 CLIENT 模式(流量從負載出站)。
名稱 | 描述 |
CLIENT_AND_SERVER | 選擇適用于工作負載既是網絡流量的源頭,又是目標的場景。 |
CLIENT | 選擇適用于工作負載是網絡流量的源頭的場景。 |
SERVER | 選擇適用于工作負載是網絡流量的目標的場景。 |
另外的 tagOverrides 字段表示要覆蓋選定的指標中的標簽名稱和標簽表達式的集合,該字段中的 key 是標簽的名稱,value 是對標簽執行的操作,可以添加、刪除標簽,或覆蓋其默認值。
字段 | 類型 | 描述 | 是否必需 |
operation | Operation | 操作控制是否更新/添加一個標簽,或者移除它。 | 否 |
value | string | 當操作為 UPSERT 時才考慮值。值是基于屬性的 CEL 表達式。例如:string(destination.port) 和 request.host。Istio 暴露所有標準的 Envoy 屬性。此外,Istio 也將節點元數據作為屬性暴露出來。更多信息請參見 自定義指標文檔。 | 否 |
對應的操作 Operator 可以配置 UPSERT 和 REMOVE 兩個操作:
名稱 | 描述 |
UPSERT | 使用提供的值表達式插入或更新標簽。如果使用 UPSERT 操作,則必須指定 value 字段。 |
REMOVE | 指定標簽在生成時不應包含在指標中。 |
現在我們直接應用上面的這個資源對象,然后我們再去訪問下 productpage 應用,再次驗證下指標數據中是否包含我們移除的 destination_canonical_service 標簽。
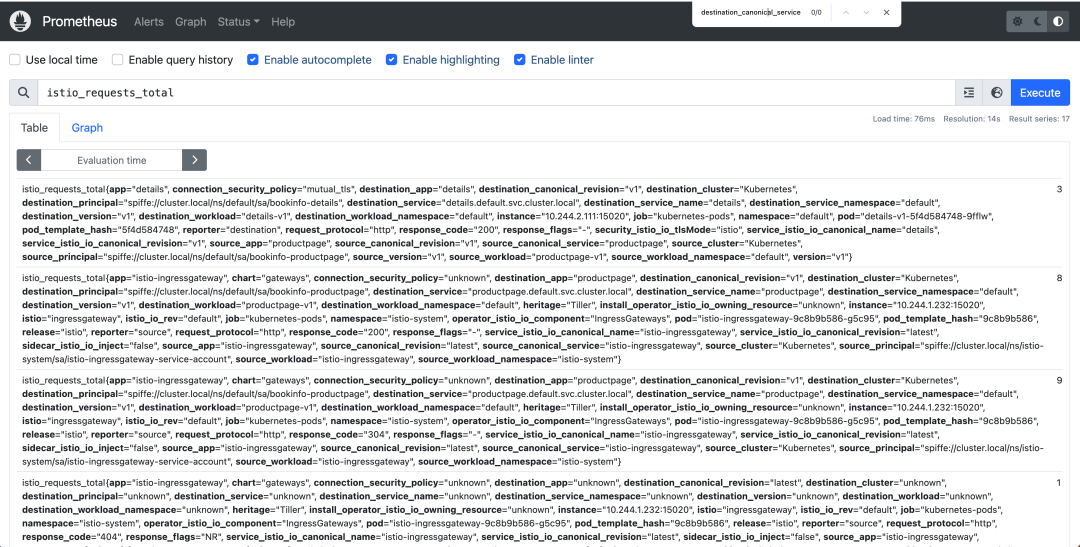
刪除標簽
從上面的結果可以看到,我們已經成功刪除了 destination_canonical_service 標簽,這樣就可以減少指標數據的基數了,可以用同樣的方法再去刪除一些不需要的標簽。
另外需要注意在 Telemetry 對象中我們還可以通過 selector 字段來配置哪些工作負載應用這個遙測策略,如果未設置,遙測策略將應用于與遙測策略相同的命名空間中的所有工作負載,當然如果是在 istio-system 命名空間中則會應用于所有命名空間中的工作負載。
添加指標
上面我們已經介紹了如何刪除指標中的標簽,那么我們也可以通過 Telemetry API 來添加指標中的標簽,如下所示:
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: add-tags
spec:
metrics:
- overrides:
- match:
metric: REQUEST_COUNT
mode: CLIENT
tagOverrides:
destination_x:
operation: UPSERT
value: "upstream_peer.labels['app'].value" # 必須加上雙引號
- match:
metric: REQUEST_COUNT
tagOverrides:
destination_port:
value: "string(destination.port)"
request_host:
value: "request.host"
providers:
- name: prometheus在上面的這個資源對象中我們在 tagOverrides 中首先添加了如下的配置:
destination_x:
operation: UPSERT
value: "upstream_peer.labels['app'].value"表示我們要添加一個名為 destination_x 的標簽,然后通過 value 字段指定標簽的值為 upstream_peer.labels['app'].value,這個值是一個 CEL 表達式(必須在 JSON 中用雙引號引用字符串)。Istio 暴露了所有標準的 Envoy 屬性,對于出站請求,對等方元數據作為上游對等方(upstream_peer)的屬性可用;對于入站請求,對等方元數據作為下游對等方(downstream_peer)的屬性可用,包含以下字段:
屬性 | 類型 | 值 |
name | string | Pod 名 |
namespace | string | Pod 所在命名空間 |
labels | map | 工作負載標簽 |
owner | string | 工作負載 owner |
workload_name | string | 工作負載名稱 |
platform_metadata | map | 平臺元數據 |
istio_version | string | 代理的版本標識 |
mesh_id | string | 網格唯一 ID |
app_containers | list<string> | 應用容器的名稱列表 |
cluster_id | string | 工作負載所屬的集群標識 |
例如,用于出站配置中的對等應用標簽的表達式是 upstream_peer.labels['app'].value,所以上面我們最終添加的 destination_x 這個標簽的值為上游對等方的 app 標簽的值。
另外添加的兩個標簽 destination_port 和 request_host 的值分別為 string(destination.port) 和 request.host,這兩個值就來源于暴露的 Envoy 屬性。
另外這個資源對象我們指定的是 default 命名空間,則只會對 default 命名空間中的工作負載應用這個遙測策略。
同樣應用這個資源對象后,再次訪問 productpage 應用產生指標,現在我們可以看到指標中已經包含了我們添加的標簽了。

添加標簽
禁用指標
對于禁用指標則相對更簡單了。比如我們通過以下配置禁用所有指標:
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: remove-all-metrics
namespace: istio-system
spec:
metrics:
- providers:
- name: prometheus
overrides:
- disabled: true
match:
mode: CLIENT_AND_SERVER
metric: ALL_METRICS通過以下配置禁用 REQUEST_COUNT 指標:
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: remove-request-count
namespace: istio-system
spec:
metrics:
- providers:
- name: prometheus
overrides:
- disabled: true
match:
mode: CLIENT_AND_SERVER
metric: REQUEST_COUNT通過以下配置禁用客戶端的 REQUEST_COUNT 指標:
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: remove-client
namespace: istio-system
spec:
metrics:
- providers:
- name: prometheus
overrides:
- disabled: true
match:
mode: CLIENT
metric: REQUEST_COUNT通過以下配置禁用服務端的 REQUEST_COUNT 指標:
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: remove-server
namespace: istio-system
spec:
metrics:
- providers:
- name: prometheus
overrides:
- disabled: true
match:
mode: SERVER
metric: REQUEST_COUNT到這里我們就了解了如何通過 Telemetry API 來自定義指標了,這樣我們就可以根據自身的需求來定制了。



























