嚴把數據質量關,用Pandas輕松進行七項基本數據檢查
一、簡介
作為一名數據工程師,面對糟糕的數據質量,該如何進行必要的數據質量檢查呢?可以使用Pandas執行快捷的數據質量檢查。
本文使用scikit-learn提供的California Housing數據集。
【數據集】:https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html
二、California Housing數據集概述
本文使用Scikit-learn數據集模塊中的California Housing數據集。該數據集包含20000多條記錄,涵蓋了八個數值特征和一個目標房價中值。
【數據集模塊】:https://scikit-learn.org/stable/datasets/real_world.html#real-world-datasets
接下來,將數據集讀取到一個名為df的Pandas數據幀中:
from sklearn.datasets import fetch_california_housing
import pandas as pd
# 獲取California Housing數據集
data = fetch_california_housing()
# 將數據集轉換為Pandas DataFrame
df = pd.DataFrame(data.data, columns=data.feature_names)
# 添加目標列
df['MedHouseVal'] = data.target要獲取數據集的詳細描述,運行data.DESCR,如下所示:
print(data.DESCR) 圖片
圖片
data.DESCR的輸出結果
接下來了解一下數據集的基本信息:
df.info()輸出結果如下:
Output >>>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MedInc 20640 non-null float64
1 HouseAge 20640 non-null float64
2 AveRooms 20640 non-null float64
3 AveBedrms 20640 non-null float64
4 Population 20640 non-null float64
5 AveOccup 20640 non-null float64
6 Latitude 20640 non-null float64
7 Longitude 20640 non-null float64
8 MedHouseVal 20640 non-null float64
dtypes: float64(9)
memory usage: 1.4 MB由于存在數值特征,因此也使用describe()方法獲取摘要統計信息:
df.describe() 圖片
圖片
df.describe()的輸出結果
三、7項基本數據質量檢查
3.1 檢查缺失值
現實世界的數據集經常存在缺失值。為了分析數據和建立模型,就需要處理這些缺失值。
為確保數據質量,應該檢查缺失值的比例是否在特定的容差范圍內。然后,可以使用適當的填充策略對缺失值進行填充。
因此,第一步是檢查數據集中所有特征的缺失值。
以下代碼會檢查數據幀df中每一列的缺失值:
# 檢查數據幀中的缺失值
missing_values = df.isnull().sum()
print("Missing Values:")
print(missing_values)結果是一個顯示每列缺失值計數的Pandas序列:
Output >>>
Missing Values:
MedInc 0
HouseAge 0
AveRooms 0
AveBedrms 0
Population 0
AveOccup 0
Latitude 0
Longitude 0
MedHouseVal 0
dtype: int64如上所示,此數據集中沒有缺失值。
3.2 識別重復記錄
數據集中的重復記錄可能會影響分析結果。因此,應該根據需要檢查并刪除重復記錄。
以下是識別并返回df中重復行的代碼。如果存在重復行,它們將包含在結果中:
# 檢查數據幀中是否有重復行
duplicate_rows = df[df.duplicated()]
print("Duplicate Rows:")
print(duplicate_rows)結果是一個空數據幀。這意味著數據集中沒有重復記錄:
Output >>>
Duplicate Rows:
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []3.3 檢查數據類型
在分析數據集時,經常需要轉換或縮放一個或多個特征。為了避免在執行此類操作時出現意外錯誤,重要的是檢查列是否都是預期的數據類型。
以下代碼檢查數據框df中每一列的數據類型:
# 檢查DataFrame中每一列的數據類型
data_types = df.dtypes
print("Data Types:")
print(data_types)在這里,所有的數值特征都是預期的浮點數據類型:
Output >>>
Data Types:
MedInc float64
HouseAge float64
AveRooms float64
AveBedrms float64
Population float64
AveOccup float64
Latitude float64
Longitude float64
MedHouseVal float64
dtype: object3.4 檢查異常值
異常值是指與數據集中其他點顯著不同的數據點。在“California Housing數據集概述”部分,本文對數據幀運行了describe()方法。
根據四分位值和最大值,可以確定一些特征包含異常值。具體而言,這些特征有:
- MedInc
- AveRooms
- AveBedrms
- Population
處理異常值的一種方法是使用四分位數間距(interquartile range,IQR),即第75個四分位數和第25個四分位數之間的差值。如果Q1是第25個四分位數,Q3是第75個四分位數,那么四分位數間距的計算公式為Q3 - Q1。
然后使用四分位數和IQR來定義區間[Q1 - 1.5 * IQR, Q3 + 1.5 * IQR]。所有在此范圍之外的點都是異常值。
columns_to_check = ['MedInc', 'AveRooms', 'AveBedrms', 'Population']
# 查找帶有異常值的記錄的函數
def find_outliers_pandas(data, column):
Q1 = data[column].quantile(0.25)
Q3 = data[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = data[(data[column] < lower_bound) | (data[column] > upper_bound)]
return outliers
# 對每個指定的列查找帶有異常值的記錄
outliers_dict = {}
for column in columns_to-check:
outliers_dict[column] = find_outliers_pandas(df, column)
# 打印每列中帶有異常值的記錄
for column, outliers in outliers_dict.items():
print(f"Outliers in '{column}':")
print(outliers)
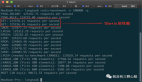
print("\n") 圖片
圖片
'AveRooms'列中的異常值 | 用于異常值檢查的截斷輸出
3.5 驗證數值范圍
對于數值特征,一項重要的檢查是驗證范圍。這可以確保特征的所有觀測值都在預期范圍內。
以下代碼將驗證MedInc值是否在預期范圍內,并識別出不符合這一標準的數據點:
# 檢查'MedInc'列的數值范圍
valid_range = (0, 16)
value_range_check = df[~df['MedInc'].between(*valid_range)]
print("Value Range Check (MedInc):")
print(value_range_check)也可以嘗試選擇其他的數值特征。但可以看到,MedInc列中的所有數值都在預期范圍內:
Output >>>
Value Range Check (MedInc):
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []3.6 檢查列間的依賴關系
大多數數據集都包含相關的特征。因此,根據列(或特征)之間的邏輯相關關系進行檢查是很重要的。
雖然單個特征本身可能在預期范圍內取值,但它們之間的關系可能是不一致的。
以下是本文數據集的一個示例。在一個有效的記錄中,“AveRooms”通常應大于或等于“AveBedRms”。
# AveRooms不應小于AveBedrooms
invalid_data = df[df['AveRooms'] < df['AveBedrms']]
print("Invalid Records (AveRooms < AveBedrms):")
print(invalid_data)在正在處理的California housing數據集中,沒有發現這樣的無效記錄:
Output >>>
Invalid Records (AveRooms < AveBedrms):
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []3.7 檢查不一致的數據輸入
在大多數數據集中,不一致的數據輸入是一個常見的數據質量問題。例如:
- 日期時間列中的格式不一致
- 分類變量值的記錄不一致
- 以不同單位記錄讀數
在本文的數據集中,已經驗證了列的數據類型并識別了異常值。但還可以嘗試檢查數據輸入是否一致。
接下來舉一個簡單的例子,檢查所有的日期輸入是否具有一致的格式。
在這里,本文使用正則表達式結合Pandas的apply()函數來檢查所有日期輸入是否符合YYYY-MM-DD的格式:
import pandas as pd
import re
data = {'Date': ['2023-10-29', '2023-11-15', '23-10-2023', '2023/10/29', '2023-10-30']}
df = pd.DataFrame(data)
# 定義預期的日期格式
date_format_pattern = r'^\d{4}-\d{2}-\d{2}$' # YYYY-MM-DD format
# 檢查日期值是否符合預期格式的函數
def check_date_format(date_str, date_format_pattern):
return re.match(date_format_pattern, date_str) is not None
# 對'Date'列應用格式檢查
date_format_check = df['Date'].apply(lambda x: check_date_format(x, date_format_pattern))
# 識別并檢索不符合預期格式的日期記錄
non_adherent_dates = df[~date_format_check]
if not non_adherent_dates.empty:
print("Entries that do not follow the expected format:")
print(non_adherent_dates)
else:
print("All dates are in the expected format.")這將返回不符合預期格式的日期記錄:
Output >>>
Entries that do not follow the expected format:
Date
2 23-10-2023
3 2023/10/29四、總結
本文介紹了使用Pandas進行常見數據質量檢查的方法。
當在處理較小的數據分析項目時,使用Pandas進行這些數據質量檢查是一個很好的起點。根據問題和數據集的不同,還可以加入其他檢查。