蝦皮一面:如何保證數據雙寫一致?

年關將至,又到了準備面試跳槽的季節了。據不完全統計,跳槽是漲薪最快的方式,沒有之一。而跳槽成功與否的關鍵是“面試”,所以認真準備面試 = 快速漲薪。
準備面試,自然就少不了刷面試真題了,而今天這份剛出爐的蝦皮 Java 后端面試題就非常典型,它的難度適中,面試結構分為:半小時八股 + 半小時手撕代碼,是目前典型的大公司的面試方式,真題如下:

面試問題很多,一篇文章肯定是寫不完的(大部分面試題可以在我的網站上找到答案:www.javacn.site),咱們今天就拿里面最經典,最常見的面試題來聊一聊:如何保證緩存和數據庫的雙寫一致性?
1、什么是雙寫一致性?
在分布式系統中,數據庫和緩存會搭配一起使用,以此來保證程序的整體查詢性能。
也就說,分布式系統為了緩解數據庫查詢的壓力,會將查出來的數據保存在緩存中,下次再查詢時,直接走緩存系統,而不再查詢數據庫,這樣就極大的提高了整體的查詢性能。
(1)為什么緩存比數據庫快?
緩存之所以比數據庫快的主要原因有以下 3 點:
- 內存訪問速度快:緩存通常將數據存儲在內存中,而數據庫將數據存儲在磁盤上。相比于磁盤訪問,內存訪問速度更快,可以達到納秒級別的讀取速度,遠遠快于數據庫的毫秒級別的讀取速度。
- IO 操作次數少:數據庫通常需要進行磁盤 IO 操作,包括讀取和寫入磁盤數據。而緩存將數據存儲在內存中,避免了磁盤 IO 的開銷。內存訪問不需要進行磁盤尋址和機械運動,相對來說速度更快。
- 特殊的數據結構:緩存的數據結構通常為 key-value 形式的,也就是說緩存可以做到任何數據量級下的查詢數據復雜度為 O(1),所以它的查詢效率是非常高的;而數據庫采用的是傳統數據結構設計,可能需要查詢二叉樹、或全文搜索、或回表查詢等操作,所以其查詢性能是遠低于緩存系統的。
(2)緩存一致性問題
雖然緩存可以極大的提高查詢性能,但同時也帶來的新的問題:數據庫和緩存一致性的問題。
具體來說,在一個常見的應用場景中,當更新數據庫的操作完成后,需要同步更新緩存,以保證緩存中的數據與數據庫中的數據保持一致。然而,由于數據庫和緩存是兩個不同的組件,它們的數據更新操作是異步的,可能存在以下問題:
- 數據延遲:數據庫更新和緩存更新之間存在時間延遲,導致緩存中的數據不是最新的。這可能會引起數據的不一致,當其他請求讀取數據時,可能會讀取到舊的數據。
- 更新失敗:在嘗試更新緩存時,可能出現更新失敗的情況。例如,緩存節點暫時不可用,網絡故障等。如果更新緩存失敗而未進行適當的處理,也會導致數據庫和緩存之間的數據不一致。
也就說,因為以上原因,可能會導致 A 用戶和 B 用戶執行了同一個查詢操作,但是得到了完全不同的結果,這就是數據庫和緩存的一致性問題。
2、如何解決一致性問題?
解決緩存和數據庫一致問題的常見解決方案有以下 4 種:
- 先修改數據庫,后更新緩存。
- 先更新緩存,后修改數據庫。
- 先修改數據庫,后刪除緩存。
- 先刪除緩存,后修改數據庫。
然而,前 3 種解決方案,有同一個問題,也就是當第一步操作執行完之后,第二步未執行的情況下,就會導致數據庫和緩存的一致性問題,例如第一步執行完之后,系統掉電了,那么一致性問題就會一直存在。
相比之下,第 4 種解決方案(先刪除緩存,后修改數據庫)相比于前三種解決方案更有優勢,起碼它保證了雙方都未執行成功,那么從數據一致性層面來講,第 4 種方案起碼保證了一定的數據一致性,然而第 4 種執行方案依然存在其他問題,例如以下這幾個:
- 業務完整性問題:程序只執行了一半,第一步執行完了但第二步未執行的情況。
- 并發保存舊值的問題:在并發環境下,第四種方案可能會導致緩存保存舊值的情況,例如以下執行情況:
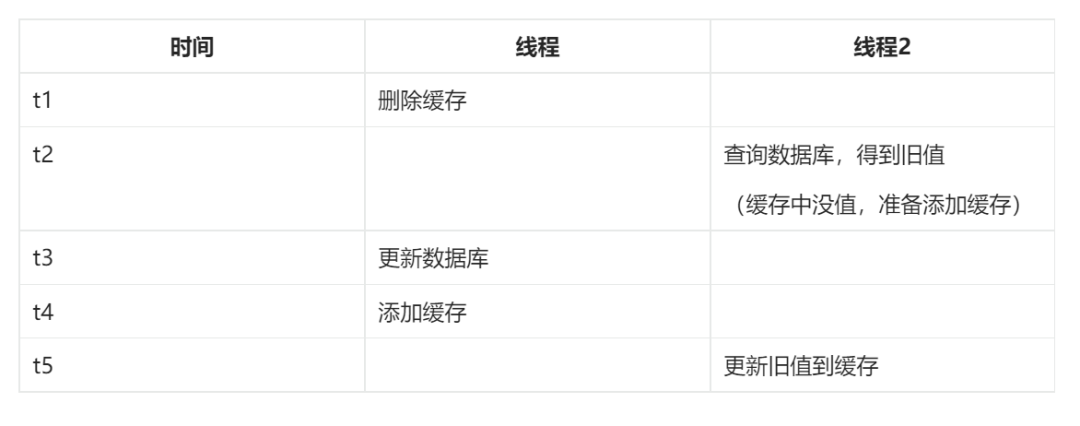
3、最終解決方案
所以,想要最大程度的雙寫一致性問題的最終解決方案是:消息隊列 + 延遲雙刪策略。
(1)為什么要使用消息隊列?
因為消息隊列里面有消息確認機制,它可以保證我們執行完第一步之后,即時掉電重啟的情況,依然可以執行后續的流程,因為之前的消息,未進行消息確認,所以程序重啟之后,會繼續執行后續的流程,這樣就保證了業務執行的完整性。
(2)什么是延遲雙刪?
延遲雙刪指的是刪除兩次緩存(并且最后一次是延遲刪除),具體執行流程如下:
- 刪除緩存
- 更新數據庫
- 延遲一會再刪除緩存
最后一次延遲刪除緩存的原因是,為了避免上面因為并發問題導致保存舊值的情況發生,所以會延遲一段時間之后再進行刪除操作。這樣即使有并發問題,也能最大限度的解決保存舊值的情況,因為是延遲之后刪除的,所以即使因為并發問題保存了舊值,但延遲一段時間之后舊值就會被刪除,那么這樣就自然而然的保證了數據庫和緩存的最終一致性。
小結
數據庫和緩存雙寫一致性問題是一道經典的面試題,最初解決方案是先更新數據庫、再刪除緩存,然而如果發生掉電情況,只執行了前一步操作,那么緩存和數據庫就出現了不一致性的問題。為了解決這個問題,所以通常會采用延遲雙刪 + 消息隊列來保證業務的完整執行和數據一致性問題。