













Python自動化辦公實戰:PDF文本提取技巧
PDF文件具有跨平臺的特點,可以在不同的操作系統和設備上保持一致的顯示效果。但是,PDF文件也有一些缺點,比如不易編輯、復制和搜索。如果我們想要從PDF文件中提取文本內容,該怎么辦呢?
在本教程中,我們將介紹如何使用Python中的PyPDF2庫來提取PDF文件中的內嵌文字內容。PyPDF2是一個純Python的庫,可以讀取、分割、合并、裁剪和轉換PDF文件。它不需要安裝任何其他的依賴庫,也不需要調用外部的程序或服務。
安裝PyPDF2庫
要使用PyPDF2庫,我們首先需要安裝它。我們可以使用pip命令來安裝,如下所示:
pip install PyPDF2如果安裝成功,我們可以在Python中導入PyPDF2模塊,如下所示:
import PyPDF2讀取PDF文件
要從PDF文件中提取文本內容,我們首先需要讀取PDF文件。我們可以使用PyPDF2.PdfReader類來創建一個PDF文件的讀取對象,然后傳入一個文件對象或一個文件路徑作為參數。例如,假設我們有一個名為sample.pdf的PDF文件,我們可以用以下代碼來讀取它:
# 通過文件對象來讀取
with open("sample.pdf", "rb") as f: # 以二進制模式打開文件
reader = PyPDF2.PdfReader(f) # 創建一個PdfFileReader對象
# 通過文件路徑來讀取
reader = PyPDF2.PdfReader("sample.pdf") # 創建一個PdfFileReader對象注意,我們必須以二進制模式("rb")來打開PDF文件,否則會出現錯誤。
獲取PDF文件的基本信息
在讀取了PDF文件之后,我們可以使用PdfReader對象的一些屬性和方法來獲取PDF文件的基本信息,例如頁數、作者、標題等。例如:
# 獲取頁數
num_pages = len(reader.pages) # 返回一個整數,表示PDF文件的總頁數
print(f"該PDF文件共有{num_pages}頁")
# 獲取作者
author = reader.metadata.author # 返回一個字符串,表示PDF文件的作者信息
print(f"該PDF文件的作者是{author}")
# 獲取標題
title = reader.metadata.title # 返回一個字符串,表示PDF文件的標題信息
print(f"該PDF文件的標題是{title}")提取單頁文本內容
要從單頁中提取文本內容,我們可以使用PdfReader對象的pages來獲取指定頁碼的頁面對象(PyPDF2.pdf.PageObject類),然后使用頁面對象的extract_text()方法來獲取頁面中的文本內容。例如:
# 獲取第一頁的頁面對象
page1 = reader.pages[0]# 傳入一個整數作為參數,表示頁碼(從0開始)
# 提取第一頁的文本內容
text1 = page1.extract_text() # 返回一個字符串,表示頁面中的文本內容
# 打印第一頁的文本內容
print(text1)注意,extract_text()方法只能提取內嵌文字內容,不能提取圖像或其他元素。另外,提取出來的文本內容可能不完全符合原始格式,可能存在換行、空格、缺失等問題。
提取多頁文本內容
要從多頁中提取文本內容,我們可以使用一個循環來遍歷PdfReader對象的每一頁,然后使用extract_text()方法來獲取每一頁的文本內容,并將它們拼接成一個完整的字符串。例如:
# 創建一個空字符串,用于存儲所有頁面的文本內容
text = ""
# 遍歷每一頁
for i in range(num_pages):
# 獲取當前頁的頁面對象
page = reader.pages[i]
# 提取當前頁的文本內容
page_text = page.extract_text()
# 將當前頁的文本內容添加到總字符串中
text += page_text
# 打印所有頁面的文本內容
print(text)保存提取的文本內容
提取了PDF文件中的文本內容之后,我們可以將它保存到一個文本文件中,以便后續的處理或分析。我們可以使用Python的內置函數open()來創建一個文本文件對象,然后使用write()方法來寫入提取的文本內容。例如:
# 創建一個名為output.txt的文本文件對象,以寫入模式打開
with open("output.txt", "w", encoding="utf-8") as f: # 指定編碼為utf-8,避免亂碼
# 將提取的文本內容寫入到文件中
f.write(text)注意,我們需要指定編碼為utf-8,以避免出現亂碼。
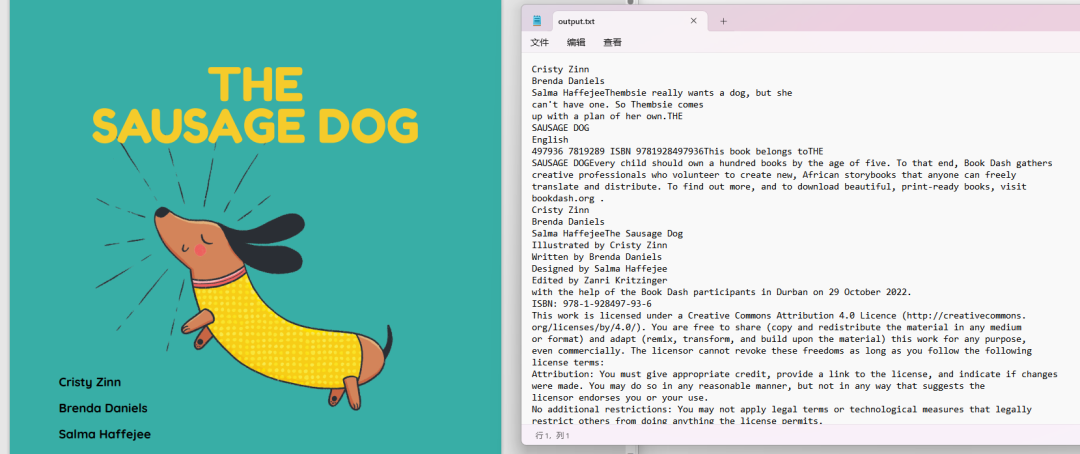
如下是:sample.pdf和output.txt文件的部分截圖
總結
在本教程中,我們介紹了如何使用Python中的PyPDF2庫來提取PDF文件中的內嵌文字內容。我們首先安裝了PyPDF2庫,并導入了PyPDF2模塊。然后,我們使用PyPDF2.PdfReader類來讀取PDF文件,并獲取了PDF文件的基本信息。接著,我們使用pages和extract_text()方法來提取單頁或多頁的文本內容,并將它們保存到一個文本文件中。通過這些操作,我們可以實現Python自動化辦公的一個功能,即從PDF文件中提取文本內容。





















