NeRF與自動駕駛的前世今生,近10篇論文匯總!
神經輻射場(Neural Radiance Fields)自2020年被提出以來,相關論文數量呈指數增長,不但成為了三維重建的重要分支方向,也逐漸作為自動駕駛重要工具活躍在研究前沿。
NeRF這兩年異軍突起,主要因為它跳過了傳統CV重建pipeline的特征點提取和匹配、對極幾何與三角化、PnP加Bundle Adjustment等步驟,甚至跳過mesh的重建、貼圖和光追,直接從2D輸入圖像學習一個輻射場,然后從輻射場輸出逼近真實照片的渲染圖像。也就是說,讓一個基于神經網絡的隱式三維模型,去擬合指定視角下的2D圖像,并使其兼具新視角合成和能力。NeRF的發展也和自動駕駛息息相關,具體體現在真實的場景重建和自動駕駛仿真器的應用中。NeRF擅長呈現照片級別的圖像渲染,因此用NeRF建模的街景能夠為自動駕駛提供高真實感的訓練數據;NeRF的地圖可以編輯,將建筑、車輛、行人組合成各種現實中難以捕捉的corner case,能夠用于檢驗感知、規劃、避障等算法的性能。因此,NeRF作為一個三維重建的分支方向和建模工具,掌握NeRF已經成為了研究者們做重建或者自動駕駛方向必不可少的技能。
今天為大家梳理下Nerf與自動駕駛相關的內容,近11篇文章,帶著大家探索Nerf與自動駕駛的前世今生;
1.Nerf開山之作
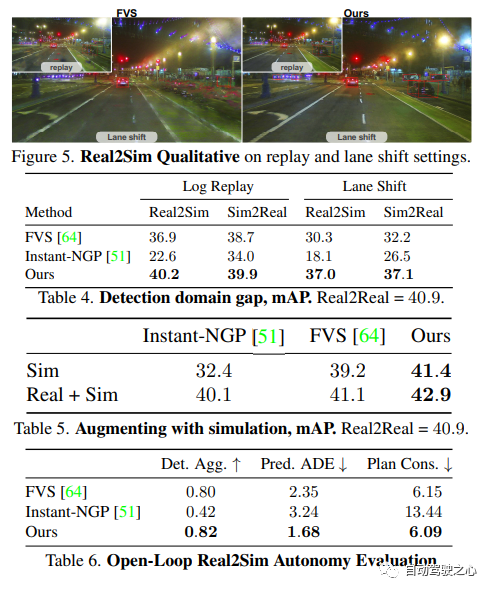
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV2020.
首篇,開山之作,提出了Nerf方法,該方法通過使用稀疏的輸入視圖集優化底層連續體積場景函數,實現了合成復雜場景的新視圖的最新結果。算法使用全連接(非卷積)深度網絡來表示場景,其輸入是單個連續5D坐標(空間位置(x,y,z)和觀看方向(θ,ξ)),其輸出是該空間位置的體積密度和與視圖相關的發射輻射。
NERF用 2D 的 posed images 作為監督,無需對圖像進行卷積,而是通過不斷學習位置編碼,用圖像顏色作為監督,來學習一組隱式參數,表示復雜的三維場景。通過隱式表示,可以完成任意視角的渲染。
2.Mip-NeRF 360
CVPR2020的工作,室外無邊界場景相關。Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
論文鏈接:https://arxiv.org/pdf/2111.12077.pdf
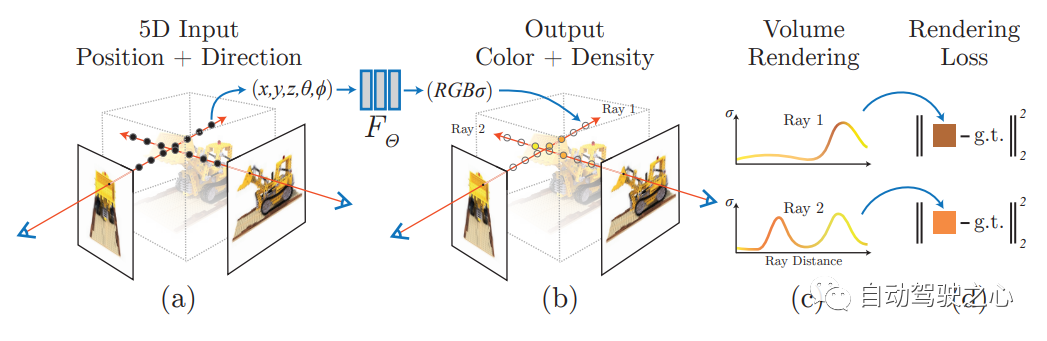
盡管神經輻射場(NeRF)已經在物體和空間的小邊界區域上展示了不錯的視圖合成結果,但它們在“無邊界”場景中很難實現,在這些場景中,相機可能指向任何方向,內容可能存在于任何距離。在這種情況下,現有的類NeRF模型通常會產生模糊或低分辨率的渲染(由于附近和遠處物體的細節和比例不平衡),訓練速度較慢,并且由于從一組小圖像重建大場景的任務的固有模糊性,可能會出現偽影。本文提出了mip-NeRF(一種解決采樣和混疊問題的NeRF變體)的擴展,它使用非線性場景參數化、在線蒸餾和一種新的基于失真的正則化子來克服無界場景帶來的挑戰。與mip-NeRF相比,均方誤差減少了57%,并且能夠為高度復雜、無邊界的真實世界場景生成逼真的合成視圖和詳細的深度圖。


3.Instant-NGP
顯示體素加隱式特征的混合場景表達(SIGGRAPH 2022)
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
鏈接:https://nvlabs.github.io/instant-ngp
這里先直接給出Instant-NGP與NeRF的異同:
- 同樣基于體渲染
- 不同于NeRF的MLP,NGP使用稀疏的參數化的voxel grid作為場景表達;
- 基于梯度,同時優化場景和MLP(其中一個MLP用作decoder)。
可以看出,大的框架還是一樣的,最重要的不同,是NGP選取了參數化的voxel grid作為場景表達。通過學習,讓voxel中保存的參數成為場景密度的形狀。MLP最大的問題就是慢。為了能高質量重建場景,往往需要一個比較大的網絡,每個采樣點過一遍網絡就會耗費大量時間。而在grid內插值就快的多。但是grid要表達高精度的場景,就需要高密度的voxel,會造成極高的內存占用。考慮到場景中有很多地方是空白的,所以NVIDIA就提出了一種稀疏的結構來表達場景。



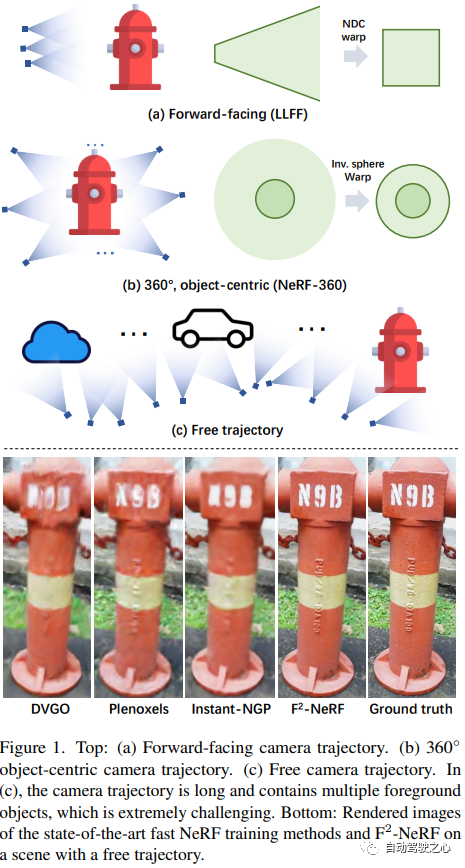
4. F2-NeRF
F2-NeRF: Fast Neural Radiance Field Training with Free Camera Trajectories
論文鏈接:https://totoro97.github.io/projects/f2-nerf/
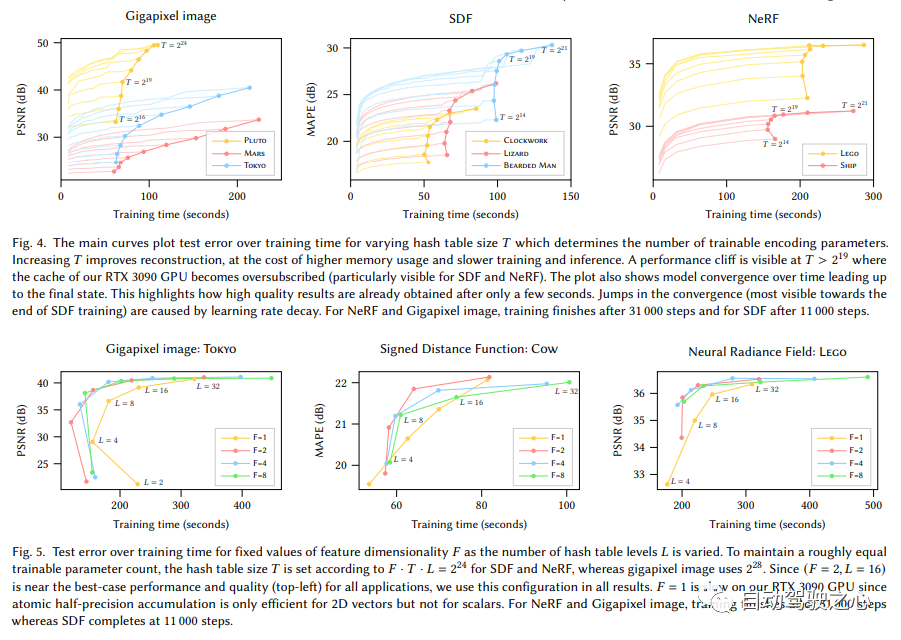
提出了一種新的基于網格的NeRF,稱為F2-NeRF(Fast Free NeRF),用于新的視圖合成,它可以實現任意輸入的相機軌跡,并且只需要幾分鐘的訓練時間。現有的基于快速網格的NeRF訓練框架,如Instant NGP、Plenoxels、DVGO或TensoRF,主要針對有界場景設計,并依靠空間warpping來處理無界場景。現有的兩種廣泛使用的空間warpping方法僅針對面向前方的軌跡或360? 以物體為中心的軌跡,但不能處理任意的軌跡。本文深入研究了空間warpping處理無界場景的機制。進一步提出了一種新的空間warpping方法,稱為透視warpping,它允許我們在基于網格的NeRF框架中處理任意軌跡。大量實驗表明,F2-NeRF能夠在收集的兩個標準數據集和一個新的自由軌跡數據集上使用相同的視角warpping來渲染高質量圖像。

5.MobileNeRF
移動端實時渲染,Nerf導出Mesh,被CVPR2023收錄!
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures.
https://arxiv.org/pdf/2208.00277.pdf
神經輻射場(NeRF)已經證明了從新穎的視圖合成3D場景圖像的驚人能力。然而,它們依賴于基于光線行進的專用volumetric 渲染算法,這些算法與廣泛部署的圖形硬件的功能不匹配。本文介紹了一種新的基于紋理多邊形的NeRF表示,該表示可以通過標準渲染pipeline有效地合成新圖像。NeRF表示為一組多邊形,其紋理表示二元不透明性和特征向量。使用z緩沖區對多邊形進行傳統渲染會生成每個像素都具有特征的圖像,這些特征由片段著色器中運行的小型視圖相關MLP進行解釋,以生成最終的像素顏色。這種方法使NeRF能夠使用傳統的多邊形光柵化pipeline進行渲染,該pipeline提供了巨大的像素級并行性,在包括手機在內的各種計算平臺上實現交互式幀率。




6.Co-SLAM
實時視覺定位和NeRF建圖工作,被CVPR2023收錄;
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
論文鏈接:https://arxiv.org/pdf/2304.14377.pdf
Co-SLAM是一個基于神經隱式表示的實時RGB-D SLAM系統,能夠進行相機跟蹤和高保真度的表面重建。Co-SLAM將場景表示為多分辨率哈希網格,以利用其極高的收斂速度和表示高頻局部特征的能力。此外,為了融合表面一致性先驗,Co-SLAM添加了一種塊狀編碼方法,證明它使得在未觀測區域能夠進行強大的場景補全。我們的聯合編碼將兩種優點結合到了Co-SLAM中:速度、高保真度重建以及表面一致性先驗,射線采樣策略使得Co-SLAM能夠對所有關鍵幀進行全局捆綁調整!




7.Neuralangelo
當前最好的NeRF表面重建方法(CVPR2023)

神經表面重建已被證明可以通過基于圖像的神經渲染來恢復密集的3D表面。然而,目前的方法很難恢復真實世界場景的詳細結構。為了解決這個問題,本文提出了Neuralangelo,它將多分辨率3D哈希網格的表示能力與神經表面渲染相結合。兩個關鍵因素:
(1) 用于計算作為平滑操作的高階導數的數值梯度,以及(2)控制不同細節級別的哈希網格上的從粗到細優化。
即使沒有深度等輔助輸入,Neuralangelo也可以有效地從多視圖圖像中恢復密集的3D表面結構,其保真度大大超過了以前的方法,從而能夠從RGB視頻捕獲中進行詳細的大規模場景重建!




8.MARS
首個開源自動駕駛NeRF仿真工具。
https://arxiv.org/pdf/2307.15058.pdf
自動駕駛汽車在普通情況下可以平穩行駛,人們普遍認為,逼真的傳感器模擬將在解決剩余拐角情況方面發揮關鍵作用。為此,MARS提出了一種基于神經輻射場的自動駕駛模擬器。與現有作品相比,MARS有三個顯著特點:(1)實例意識。模擬器使用獨立的網絡分別對前景實例和背景環境進行建模,以便可以分別控制實例的靜態(例如大小和外觀)和動態(例如軌跡)特性。(2) 模塊化。模擬器允許在不同的現代NeRF相關主干、采樣策略、輸入模式等之間靈活切換。希望這種模塊化設計能夠推動基于NeRF的自動駕駛模擬的學術進步和工業部署。(3) 真實。模擬器在最佳模塊選擇的情況下,設置了最先進的真實感結果。
最重要的一點是:開源!



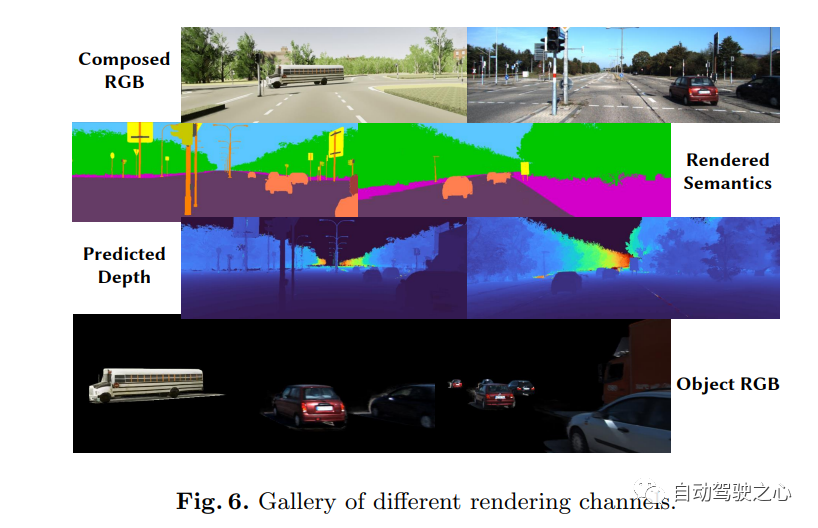
9.UniOcc
NeRF和3D占用網絡, AD2023 Challenge
UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering.
論文鏈接:https://arxiv.org/abs/2306.09117
UniOCC是以視覺為中心的3D占用預測,用于占用預測的現有方法主要集中于使用3D占用標簽來優化3D volume 空間上的投影特征。然而,這些標簽的生成過程復雜且昂貴(依賴于3D語義注釋),并且受體素分辨率的限制,它們無法提供細粒度的空間語義。為了解決這一限制,本文提出了一種新的統一占用(UniOcc)預測方法,明確施加空間幾何約束,并通過體射線渲染補充細粒度語義監督。方法顯著提高了模型性能,并證明了在降低人工標注成本方面的潛力。考慮到標注3D占用的費力性質,進一步引入了深度感知師生(DTS)框架,以使用未標記數據提高預測精度。解決方案在單機型的官方排行榜上獲得了51.27%mIoU的成績,在本次挑戰中排名第三。


10.Unisim
waabi出品,必是精品啊!
UniSim: A Neural Closed-Loop Sensor Simulator
論文鏈接:https://arxiv.org/pdf/2308.01898.pdf
阻礙自動駕駛普及的一個重要原因是安全性仍然不夠。真實世界過于復雜,尤其是存在長尾效應(long tail)。邊界場景對安全駕駛至關重要,很多樣,但又很難遇到。測試自動駕駛系統在這些場景的表現非常困難,因為這些場景很難遇到,而且在真實世界中測試非常昂貴和危險。
為了解決這個挑戰,工業界和學術界都開始重視仿真系統的開發。一開始,仿真系統主要專注于模擬其他車輛/行人的運動行為,測試自動駕駛規劃模塊的準確性。而最近幾年,研究重心逐漸轉向傳感器層面的仿真,即仿真生成激光雷達、相機圖片等原始數據,實現端到端測試自動駕駛系統從感知、預測一直到規劃。
不同于以往工作, UniSim首次同時做到了:
- 高度逼真(high realism): 可以準確地模擬真實世界(圖片和LiDAR), 減小鴻溝(domain gap )
- 閉環測試(closed-loop simulation): 可以生成罕見的危險場景測試無人車, 并允許無人車和環境自由交互
- 可擴展 (scalable): 可以很容易的擴展到更多的場景, 只需要采集一次數據, 就能重建并仿真測

仿真系統的搭建
UniSim 首先從采集的數據中,在數字世界中重建自動駕駛場景,包括汽車、行人、道路、建筑和交通標志。然后,控制重建的場景進行仿真,生成一些罕見的關鍵場景。
閉環仿真(closed-loop simulation)
UniSim可以進行閉環的仿真測試,首先, 通過控制汽車的行為, UniSim可以創建一個危險的罕見場景, 比如有一輛汽車在當前車道突然迎面駛來;然后, UniSim仿真生成對應的數據;接著, 運行自動駕駛系統, 輸出路徑規劃的結果;根據路徑規劃的結果, 無人車移動到下一個指定位置, 并更新場景(無人車和其他車輛的位置);然后我們繼續進行仿真, 運行自動駕駛系統, 更新虛擬世界狀態 ……通過這種閉環測試, 自動駕駛系統和仿真環境可以進行交互, 創造出與原始數據完全不一樣的場景