













詳解超強ResNet變體NFNet:拋棄歸一化后,性能卻達(dá)到了最強!
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
從上古時期一直到今天,Batch Norm (BN) 一直都是視覺骨干架構(gòu)里面很重要的一個環(huán)節(jié)。BN 使得研究人員可以訓(xùn)練更深的網(wǎng)絡(luò),并在訓(xùn)練集和測試集上實現(xiàn)更高的精度。Batch Norm 還可以平滑 Loss Landscape[1],使得我們可以在更大的 Batch Size 和學(xué)習(xí)率實現(xiàn)穩(wěn)定訓(xùn)練,具有正則化效果[2]。
但是,BN 也有一些不理想的特性,比如依賴于 Batch Size,引入了模型在 training 期間和 inference 期間的行為差異等等。
本文提出一種不含 BN 的神經(jīng)網(wǎng)絡(luò)模型 NFNet,在當(dāng)時超越了 EfficientNet 系列,如下圖1所示。本文還提出一種自適應(yīng)梯度裁剪用以拉大 Batch Size 的同時保持訓(xùn)練的穩(wěn)定,來支持 Large Batch 的訓(xùn)練。
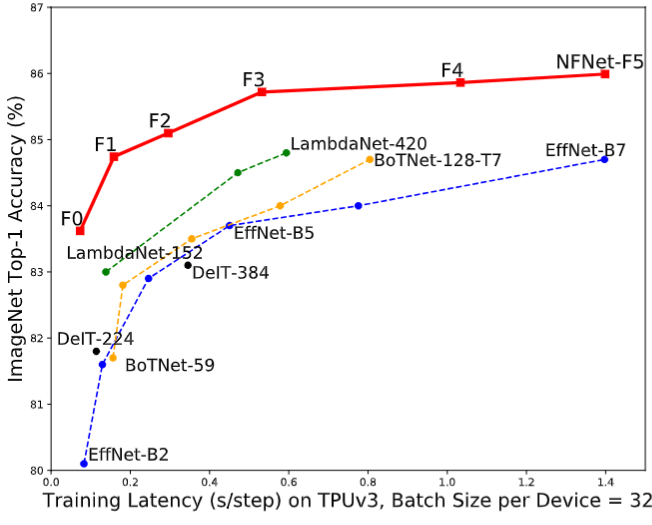
圖1:NFNet 的 ImageNet 精度和訓(xùn)練延時
1 NFNet 視覺大模型:無需 BN 的 ResNet 變體,以及匹敵 ViT 性能的大規(guī)模預(yù)訓(xùn)練
論文名稱:High-Performance Large-Scale Image Recognition Without Normalization (ICML 2021)
論文地址:
https://arxiv.org/pdf/2102.06171.pdf
1.1 背景:Batch Norm 的優(yōu)點
計算機視覺中很多 Backbone 模型是經(jīng)過了 Batch Norm[3]的訓(xùn)練的 ResNet 的變體。這兩種架構(gòu)的結(jié)合使得研究人員可以訓(xùn)練更深的網(wǎng)絡(luò),并在訓(xùn)練集和測試集上實現(xiàn)更高的精度。Batch Norm 還可以平滑 Loss Landscape[1],使得我們可以在更大的 Batch Size 和學(xué)習(xí)率實現(xiàn)穩(wěn)定訓(xùn)練,具有正則化效果[2]。
總結(jié) Batch Norm 具有4個主要的優(yōu)點:
- Batch Norm 縮小了 Residual Branch 的幅值: 當(dāng)把 BN 放置在殘差分支上時,減少了在模型訓(xùn)練初始化時殘差分支上激活的比例。這會使網(wǎng)絡(luò)的特征更多地偏向 Shortcut 這條路徑,也就確保了網(wǎng)絡(luò)在訓(xùn)練早期具有良好的梯度,從而便于實現(xiàn)高效的優(yōu)化。
- Batch Norm 消除了 mean-shift: ReLU 或 GELU 等激活函數(shù)不是對稱的,具有非零的平均激活值。這就使得即使輸入特征之間的內(nèi)積接近于零,非線性激活值通常也是很大的正數(shù)。隨著網(wǎng)絡(luò)深度的增加,這個問題也變得更加嚴(yán)重,給激活值帶來了一個 mean-shift,可能導(dǎo)致模型在初始化時對所有輸入圖片的預(yù)測結(jié)果都為相同的標(biāo)簽。Batch Norm 消除了 mean-shift,因為可以確保每個 channel 的平均激活值為零。
- Batch Norm 有正則化效果: 因為一個 Batch 中的噪聲是在訓(xùn)練數(shù)據(jù)的子集上計算的,因此 BN 也可以扮演正則化器的角色增強測試集的準(zhǔn)確性。
- Batch Norm 允許較大 Batch 的訓(xùn)練: Batch Norm 可以平滑 Loss Landscape,這可以增加模型的最大穩(wěn)定學(xué)習(xí)率。雖然 large-batch training 沒有在給定 Epoch 數(shù)的限制下實現(xiàn)更好的測試集精度,但是它能夠以較少的參數(shù)更新次數(shù)的條件下實現(xiàn)給定的測試集精度。
1.2 背景:Batch Norm 的缺點以及 Normalizer-Free 的 ResNet 模型
但是,Batch Norm 具有3個顯著的實際缺點:
- Batch Norm 會產(chǎn)生內(nèi)存開銷,并顯著增加某些網(wǎng)絡(luò)中計算梯度所需的時間。
- Batch Norm 引入了模型在 training 期間和 inference 期間的行為差異。
- Batch Norm 打破了小 Batch 中訓(xùn)練示例之間的獨立性。
第3個缺點有一系列負(fù)面后果:
- 帶有 Batch Norm 的網(wǎng)絡(luò)通常難以在不同的硬件上精確復(fù)制,尤其是在分布式訓(xùn)練期間,Batch Norm 通常是細(xì)微實現(xiàn)錯誤的原因。
- Batch Norm 不能用于某些任務(wù),因為 Batch 中訓(xùn)練 instance 之間的交互使網(wǎng)絡(luò)能夠 "欺騙" 某些損失函數(shù)。比如,在對比學(xué)習(xí)任務(wù)[4][5]中,BN 需要特別注意防止信息泄漏。這也是序列建模任務(wù)的主要問題,它驅(qū)使 Transformer 這樣的語言模型使用 Layer Norm 的替代品。
- 如果在訓(xùn)練期間某個 Batch 的數(shù)據(jù)存在著較大的方差,Batch Norm 網(wǎng)絡(luò)的性能也會下降。BN 的性能對于 Batch Size 的大小很敏感,當(dāng) Batch Size 太小時,Batch Size 網(wǎng)絡(luò)的表現(xiàn)不佳,這限制了我們在有限硬件上訓(xùn)練的最大模型的尺寸。
因此,從這個角度來看,盡管 BN 層使得深度學(xué)習(xí)社區(qū)近年來取得了可觀的收益,但是從長遠(yuǎn)來看,可能會阻礙長遠(yuǎn)的發(fā)展。目前已有一些替代 BN 的歸一化層,比如 Layer Normalization[6],Group Normalization[7],但這些替代方案通常可以實現(xiàn)較差的測試精度并引入他們自己的缺點,例如推理的額外計算成本。
近年來出現(xiàn)了兩個有前途的研究課題:其一是研究 BN 對于訓(xùn)練的好處的起源[1][2][8]。其二是旨在訓(xùn)練無歸一化層的 ResNet,并實現(xiàn)具有競爭力的精度[9][10][11][12][13]。
1.3 去掉 Batch Norm 的網(wǎng)絡(luò)
許多無歸一化層的 ResNet 工作的一個關(guān)鍵做法是:可以通過抑制殘差分支上的特征值的比例來訓(xùn)練非常深的 ResNet 模型,而無需進(jìn)行歸一化。實現(xiàn)這一點的最簡單方法是在每個殘差分支的末尾引入一個可學(xué)習(xí)的標(biāo)量,初始化為0[14][12]。但是只有此技巧不足以在具有挑戰(zhàn)性的 ImageNet 上獲得有競爭力的測試精度。另一項工作表明,ReLU 激活函數(shù)引入了 "mean shift",這導(dǎo)致隨著網(wǎng)絡(luò)深度的增加,不同訓(xùn)練示例的激活值變得越來越相關(guān)。[10]提出 Normalizer-Free ResNet,通過 Scaled Weight Standardization 技術(shù)來去掉 "mean shift"。這種技術(shù)將卷積層重新參數(shù)化為

其中, 代表扇入系數(shù)。
ReLU 激活函數(shù)也由非線性特定標(biāo)量增益 來縮放, 這確保了激活函數(shù)和 BN 層的組合保持方差不變, 對于 ReLU 激活函數(shù)有 。
這里證明下這個結(jié)論
待證明: , 則:
證:
因為有 , 因此需要分別計算 和 。
- 的計算: 因為 , 因此有 。基于此: 。
- 的計算:
因此有 證畢。
以上結(jié)論說明:對于 ReLU 激活函數(shù)有 , 即對于正態(tài)分布 輸 激活函數(shù)輸出的方差是 。
通過額外正則化比如 Dropout 或者 Stochastic Depth,在 Batch Size 為1024時,無需歸一化的模型在 ImageNet 上匹配了帶有 Batch Norm 的 ResNet 的性能,甚至在小 Batch Size 時表現(xiàn)更好,但它們在大 Batch 下表現(xiàn)出不穩(wěn)定。
本文 NFNet 這個模型的設(shè)計基于 NF-ResNets[10],是一種 Normalizer-Free 的 ResNet。NF-ResNets 每個 Block 內(nèi)部的表達(dá)式可以寫為:

其中, 代表第 個殘差塊的輸入, 代表第 個殘差塊內(nèi)部的操作。函數(shù) 在初始化時保證了方差的不變性: 。
標(biāo)量 為每個殘差塊之后激活的方差增加的速率并且通常設(shè)置為一個小值, 比如0.2。標(biāo)量 是通過預(yù)測輸入到第 個殘差塊的標(biāo)準(zhǔn)差 來確定的, 其中
1.4 自適應(yīng)梯度裁剪
為了擴大訓(xùn)練的 Batch Size, 作者使用了梯度裁剪 (gradient clipping) 策略。梯度裁剪策略也允許使用更大的學(xué)習(xí)率, 以加快收玫過程。對于梯度向量 , 其中 是損失函數(shù), 是參數(shù)向量, 標(biāo)準(zhǔn)的梯度裁剪算法在更新參數(shù)之前裁剪梯度為:
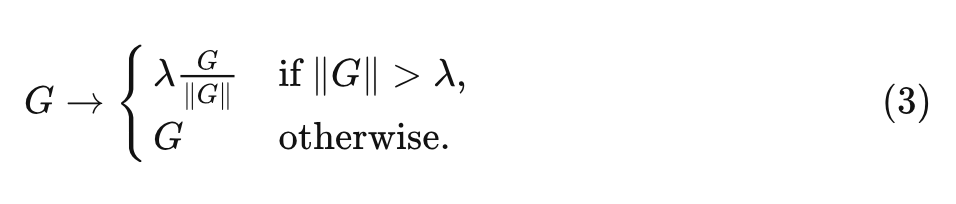
式中,裁剪閾值 是一個要調(diào)整的超參數(shù)。根據(jù)經(jīng)驗,作者發(fā)現(xiàn)雖然這種裁剪算法能夠以比以前更高的 Batch Size 進(jìn)行訓(xùn)練,但訓(xùn)練穩(wěn)定性對裁剪閾值的選擇非常敏感,需要在改變深度、Batch Size 或?qū)W習(xí)率時進(jìn)行細(xì)粒度的調(diào)整。
為了解決這個問題,本文提出自適應(yīng)梯度裁剪 (Adaptive Gradient Clipping, AGC)。
假設(shè) 為第 層的參數(shù)矩陣, 為對應(yīng)的權(quán)重矩陣。
, 其中 代表 Frobenius 范數(shù)。
AGC 算法的動機是通過梯度 與權(quán)值 的范數(shù)之比 來作為一種簡單的度量, 即梯度下降一步可以改變多少比例的權(quán)重。比如, 如果在沒有動量的情況下使用梯度下降進(jìn)行訓(xùn)練, 則 , 其中 是學(xué)習(xí)率。
對于 AGC 算法, 第 層的每個梯度 被裁剪為:
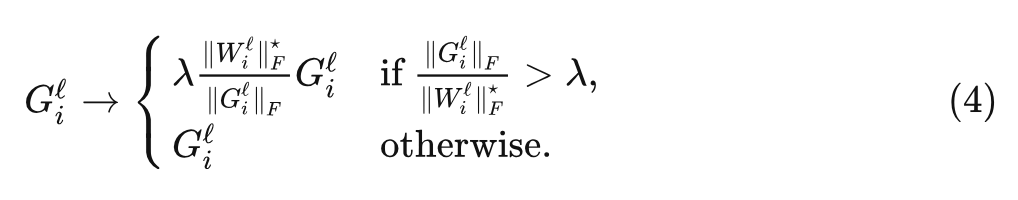
式中, 是裁剪閾值, 并定義 , 這可以防止零初始化的參數(shù)總是將它們的梯度裁剪為零。注意到最優(yōu)的裁剪閾值 可能取決于優(yōu)化器的選擇、學(xué)習(xí)率和 Batch Size。根據(jù)經(jīng)驗,作者發(fā)現(xiàn)對于較大的 Batch Size, 應(yīng)該更小。
1.5 自適應(yīng)梯度裁剪的消融實驗結(jié)果
為了測試 AGC 的效果,作者對 ImageNet 上對 NF-ResNet-50 和 NF-ResNet-200 進(jìn)行了實驗,使用 SGD 和 Nesterov 動量在 256 到 4096 之間的 Batch Size 范圍內(nèi)進(jìn)行 90 個 Epochs 的訓(xùn)練。對 Batch Size 為 256 使用 0.1 的基本學(xué)習(xí)率,該學(xué)習(xí)率隨著 Batch Size 進(jìn)行線性縮放。作者考慮一系列的 λ\lambda\lambda 值 [0.01, 0.02, 0.04, 0.08, 0.16]。
如下圖 2(a) 所示為 AGC 可以有效地將 NF-ResNets 擴展到更大的 Batch Size。圖 2(b) 所示是不同裁剪閾值 λ\lambda\lambda 的性能且當(dāng) Batch Size 很大時就需要更小的裁剪閾值。
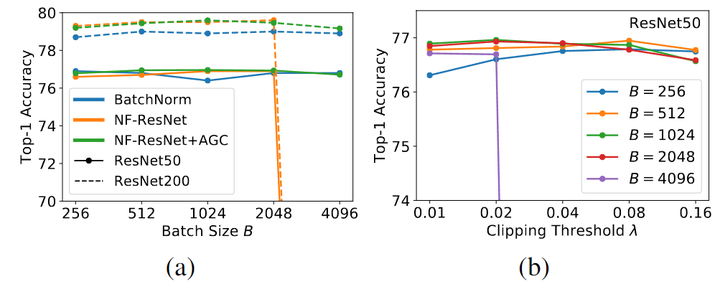
圖2:(a) AGC 有效地將 NF-ResNets 擴展到更大的 Batch Size (b) 不同裁剪閾值 λ 的性能
本文又通過一些消融實驗發(fā)現(xiàn),除了最終的線性層之外,將 AGC 應(yīng)用于其他所有層比較好,因此后續(xù)就按照這種做法。
1.6 NFNet 模型架構(gòu)改進(jìn)
在模型設(shè)計的過程中,可以有多重度量的范式:
- 理論 FLOPs
- 目標(biāo)設(shè)備上的 inference latency
- 加速器上的 training latency
每個度量的性質(zhì)將產(chǎn)生不同的設(shè)計要求,本文中作者專注于加速器上的 training latency。未來的加速器可能能夠利用潛在的訓(xùn)練速度,開發(fā)在當(dāng)前硬件上提高訓(xùn)練速度的模型將有助于加速研究。作者注意到 GPU 和 TPU 等加速器傾向于密集計算,雖然這兩個平臺之間存在差異,但為一個設(shè)備設(shè)計的模型很可能在另一個設(shè)備上快速訓(xùn)練。如圖3所示是 NFNet bottleneck block design 的改進(jìn)和不同,圖4是細(xì)節(jié)架構(gòu)。作者從具有 GELU 激活函數(shù)的 SE-ResNeXt-D 模型開始,因為發(fā)現(xiàn)它是 Normalizer-Free 的不錯的基線。然后,作者做了幾處改進(jìn):
將 3×3 卷積的組寬度設(shè)置為128: 較小的組寬度減少了理論FLOPs,但計算密度的降低意味著在許多現(xiàn)代加速器上,沒有實現(xiàn)實際的加速。
深度縮放模式: 作者注意到 ResNet 的默認(rèn)深度縮放模式 (例如從 ResNet50 中增加深度以構(gòu)建 ResNet101 或 ResNet200 的方法) 是不均勻地增加第2和3個 Stage 的層數(shù),同時保持第1和4個 Stage 的層數(shù)不變。作者發(fā)現(xiàn)這種策略是次優(yōu)的。早期階段的層以更高的分辨率運行,需要更多的內(nèi)存和計算,并且傾向于學(xué)習(xí)一般性的特征。而后期的層以較低分辨率運行,包含大部分模型的參數(shù),并學(xué)習(xí)更多特定任務(wù)相關(guān)的特征。但是,在早期階段過于簡約可能會損害性能,因為模型需要足夠的容量來提取良好的局部特征。最小的模型 NFNet-F0 的各個 Stage 的層數(shù)是 [1, 2, 6, 3]。
寬度模式: 作者考慮了 ResNet 中的默認(rèn)寬度模式,其中第1個 Stage 有256個 channel,在隨后的每個 Stage 都會翻倍,得到的 channel 數(shù)分別為 [256, 512, 1024, 2048]。作者發(fā)現(xiàn)只有 [256, 512, 1536, 1536] 這一個選擇優(yōu)于默認(rèn)值,這種深度的模式旨在增加第三階段的容量,同時在第二階段略微降低容量,且可以大致保持訓(xùn)練速度。作者發(fā)現(xiàn)第3階段是增加容量的最佳位置,且假設(shè)這是因為這個階段足夠深,有較大的感受野,同時具有比最終階段稍高的分辨率。
縮放策略 (如何把模型做大): 作者使用上述固定寬度、同時縮放深度以及縮放訓(xùn)練分辨率,使得每個變體的訓(xùn)練速度大約是其前面更小的模型的約一半。同時,作者以稍高的分辨率進(jìn)行推理,選擇的分辨率使得推理速度大約是訓(xùn)練速度的 33%。
正則化強度: 作者還發(fā)現(xiàn),隨著模型容量的增加,增加正則化強度有幫助。但是,修改權(quán)重衰減或 stochastic depth rate 并不有效,而修改 Dropout 比較有效。因為 NFNet 模型模型缺乏 BN 帶來的隱式正則化,而如果再缺乏顯式的正則化作用就會導(dǎo)致過擬合。
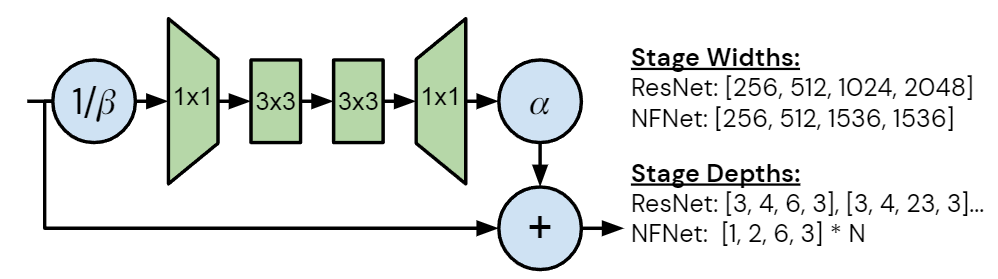
圖3:NFNet bottleneck block design 的改進(jìn)和不同
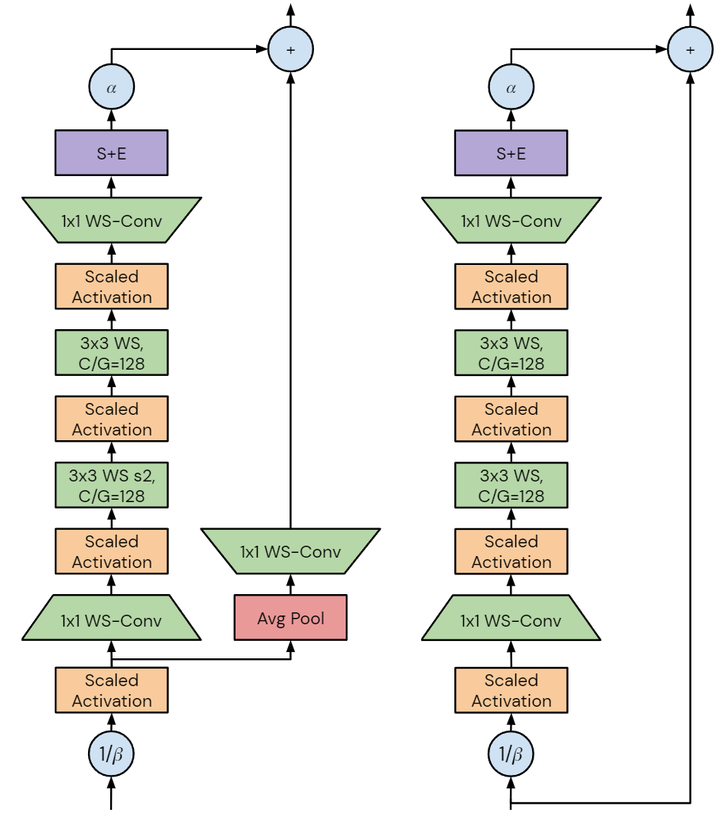
圖4:左:NFNet Transition Block。右:NFNet Non-Transition Block
最后,再來總結(jié)下 NFNet 的 training recipe:
- 將 Normalizer-Free 模型的策略應(yīng)用于 SE-ResNeXt-D。
- 修改寬度模式和深度縮放模式,以及第2個空間卷積。
- 除了分類器層的線性權(quán)重外,將 AGC 應(yīng)用于每個參數(shù)。
- 強正則化和數(shù)據(jù)增強。
1.7 NFNet 實驗結(jié)果
作者在 ImageNet 上訓(xùn)練 NFNet 模型,Batch Size 為 4096,訓(xùn)練300 Epochs,使用 Nesterov's Momentum,momentum coefficient 是 0.9,學(xué)習(xí)率在5個 Epoch 內(nèi),線性地從0增加到1.6。從下圖5的前3行中,可以看到本文的方法都可以使得性能略有提高,而訓(xùn)練延遲僅略有變化。另外,數(shù)據(jù)增強也顯著提高了性能。
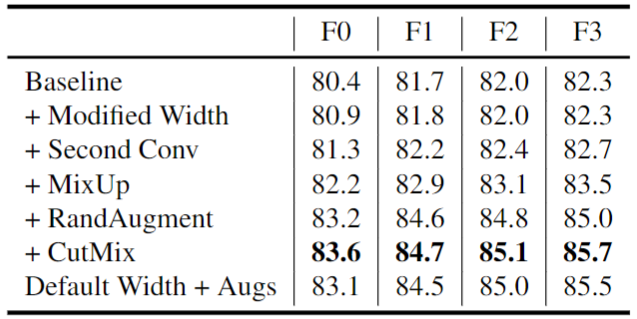
圖5:消融實驗結(jié)果
作者在下圖6中提供了6個 NFNet 模型變體 NFNet-F0 到 F5 的大小、訓(xùn)練延遲 (TPUv3 和 V100) 和 ImageNet 精度的詳細(xì)比較,以及與其他具有相似訓(xùn)練延遲的模型的比較。NFNet-F5 模型達(dá)到了 86.0% 的 Top-1 精度,比 EfficientNet-B8 小幅提升。NFNet-F1 模型的性能與 84.7% 的 EfficientNet-B7 相當(dāng),同時訓(xùn)練速度快 8.7 倍。
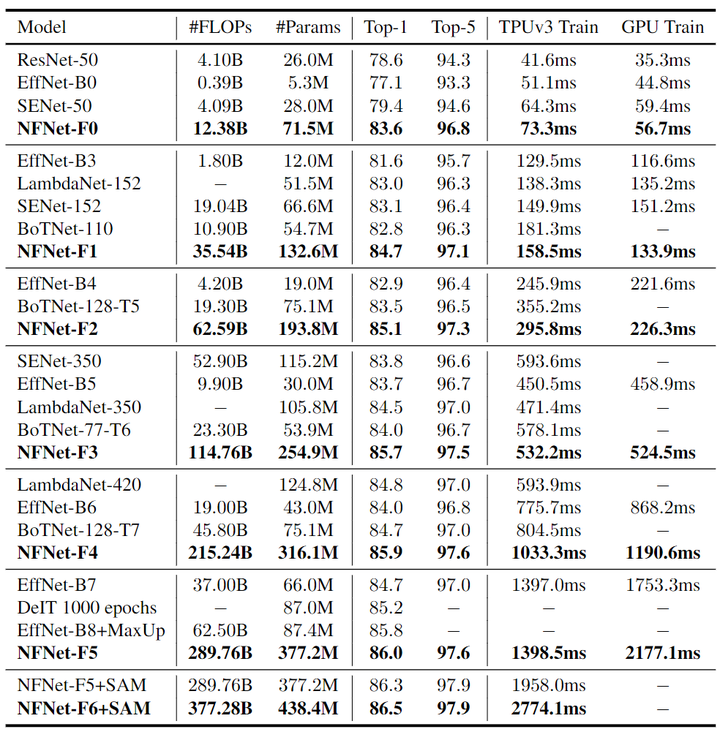
圖6:ImageNet 實驗結(jié)果
1.8 NFNet 的大規(guī)模預(yù)訓(xùn)練
NFNet 由于不含 BN 帶來的隱式正則化效果,除非顯式正則化,否則對于像 ImageNet 這樣的數(shù)據(jù)集往往會過擬合。但是當(dāng)在極大規(guī)模的數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練時,這種正則化可能不僅是不必要的,而且對性能有害,降低了模型將其全部容量投入到訓(xùn)練集的能力。
基于這一點,作者假設(shè) Normalizer-Free 的模型天然適用大規(guī)模預(yù)訓(xùn)練,及其后續(xù)的遷移學(xué)習(xí),并在 300 million labeled images 數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練。
預(yù)訓(xùn)練的做法是:對一系列帶 BN 的 ResNets 和 NF-ResNets 預(yù)訓(xùn)練10 個 Epochs,然后同時使用 Batch Size 為2048,和 0.1 的小學(xué)習(xí)率同時在 ImageNet 上微調(diào)所有層,輸入圖像分辨率范圍為 [224, 320, 384]。結(jié)果如圖7所示,Normalizer-Free 網(wǎng)絡(luò)在每種情況下都優(yōu)于其 Batch-Normalized 對應(yīng)模型,說明在遷移學(xué)習(xí)機制中,去除 BN 可以直接有利于最終性能。
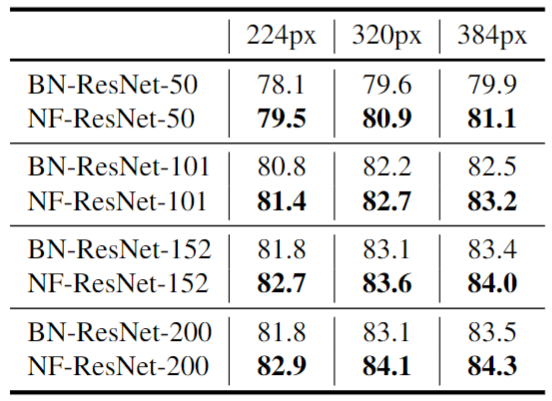
圖7:ImageNet 預(yù)訓(xùn)練后的 Top-1 精度
作者又使用 NFNet 模型進(jìn)行了相同的實驗,預(yù)訓(xùn)練的模型是 NFNet-F4 和一個稍微寬點的變體 NFNet-F4+。經(jīng)過 20 個 epoch 的預(yù)訓(xùn)練,NFNet-F4+ 獲得了 89.2% 的 ImageNet Top-1 精度。這是在當(dāng)時使用遷移學(xué)習(xí)實現(xiàn)的最高精度。

原文鏈接:https://mp.weixin.qq.com/s/41WSOh2RO8kK3ShcndcQIA




















