彩虹橋架構演進之路-性能篇
一、前言
一年前的《彩虹橋架構演進之路》側重探討了穩定性和功能性兩個方向。在過去一年中,盡管業務需求不斷增長且流量激增了數倍,彩虹橋仍保持著零故障的一個狀態,算是不錯的階段性成果。而這次的架構演進,主要分享一下近期針對性能層面做的一些架構調整和優化。其中最大的調整就是 Proxy-DB 層的線程模式從 BIO 改造成了性能更好的 NIO。下面會詳細介紹一下具體的改造細節以及做了哪些優化。
閱讀本文預計需要 20~30 分鐘,整體內容會有些枯燥難懂,建議閱讀前先看一下上一篇彩虹橋架構演進的文章(彩虹橋架構演進之路)以及 MySQL 協議相關基礎知識。
二、改造前的架構
先來復習一下彩虹橋的全景架構圖:
 圖片
圖片
Proxy三層模塊
針對 Proxy 這一層,可以大致分成 Frontend、Core、Backend 三層:
Frontend-服務暴露層:使用 Netty 作為服務器,按照 MySQL 協議對接收&返回的數據進行編解碼。
Core-功能&內核層:通過解析、改寫、路由等內核能力實現數據分片、讀寫分離、影子庫路由等核心功能。
Backend-底層DB交互層:通過 JDBC 實現與數據庫交互、對結果集改列、歸并等操作。
BIO模式下的問題
這里 Core 層為純計算操作,而 Frontend、Backend 都涉及 IO 操作,Frontend 層使用 Netty 暴露服務為 NIO 模式,但是 Backend 使用了數據庫廠商提供的傳統 JDBC 驅動,為 BIO 模式。所以 Proxy 的整體架構還是 BIO 模式。在 BIO 模型中,每個連接都需要一個獨立的線程來處理。這種模型有一些明顯的缺點:
- 高資源消耗:每個請求創建獨立線程,伴隨大量線程開銷。線程切換與調度額外消耗 CPU。
- 擴展性受限:受系統線程上限影響,處理大量并發連接時,性能急劇下降。
- I/O阻塞:BIO 模型中,讀/寫操作均為阻塞型,導致線程無法執行其他任務,造成資源浪費。
- 復雜的線程管理:線程管理和同步問題增加開發和維護難度。
我們看最簡單的一個場景:在 JDBC 在發起請求后,當前線程會一直阻塞直到數據庫返回數據,當出現大量慢查或者數據庫出現故障時,會導致大量線程阻塞,最終雪崩。在上一篇彩虹橋架構演進文章中,我們做了一些改進來避免了 BIO 模型下的一些問題,比如使用線程池隔離來解決單庫阻塞導致全局雪崩的問題。
 圖片
圖片
但是隨著邏輯庫數量的增多,最終導致 Proxy 的線程數膨脹。系統的可伸縮性和吞吐量都受到了挑戰。因此有必要將現有的基于 JDBC 驅動的阻塞式連接升級為采用 NIO(非阻塞 I/O)方式連接數據庫。
三、改造后的架構
- BIO->NIO
想把 Proxy 整體架構從 BIO->NIO,最簡單的方式就是把傳統的 BIO 數據庫驅動 JDBC 換成 NIO 的數據庫驅動,但是在調研過后發現開源的 NIO 驅動并不多,而且基本上沒有什么最佳實踐。最后在參考 ShardingSphere 社區之前做的調研后(https://github.com/apache/shardingsphere/issues/13957),決定使用 Vertx 來替換 JDBC。最開始使用 Vert.x 的原因,第一是 Vertx 的異步編碼方式更友好,編碼復雜度相對較低,第二是因為它實現了主流數據庫的驅動。但最終的結果不盡人意,由于 Vertx 相關抽象化的架構,導致鏈路較長時,整個調用棧深非常夸張。最終壓測出來的吞吐量提升只有 5% 不到,而且存在很多兼容性問題。于是推倒重來,決定自研數據庫驅動和連接池。
- 跳過不必要的編解碼階段
由于 JDBC 驅動會自動把 MySQL 的字節數據編解碼成 Java 對象,然后 Proxy 再把這些結果集經過一些加工(元信息修正、結果集歸并)后再進行編碼返回給上游。如果自研驅動的話,就可以把編解碼流程控制的更細致一些,把 Proxy 不需要加工的數據直接轉發給上游,跳過無意義的編解碼。后面會介紹一下哪些場景是不需要 Proxy 對結果集進行加工的。
自研NIO數據庫驅動
 圖片
圖片
 圖片
圖片
所以首先我們需要了解一下,如何與數據庫進行數據交互,以 MySQL 為例,使用 Netty 連接 MySQL,簡單的交互流程如下。
 圖片
圖片
使用 Netty 與 MySQL 連接建立后,我們要做的就是按照 MySQL 協議規定的數據格式,先鑒權后再發送具體的命令包即可。下面是 MySQL 官方文檔中鑒權流程和命令執行流程:
- 鑒權流程:https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_connection_phase.html
- 執行命令流程:https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_command_phase.html
下面就是按照 MySQL 的文檔,去實現編解碼 Handle,我們簡單看一下實現的代碼。
 圖片
圖片
- decode 解碼
就是針對 MySQL 返回的數據包解碼,根據長度解析出 Palyload 封裝成 MySQLPacketPayload 傳給對應的 Handle 處理。
- encode 編碼
把具體的命令類轉換成具體的 MySQL 數據包,這里的 MySQLPacket 有多個實現類,跟 MySQL的Command 類型一一對應。
現在還需要一個類似 java.sql.Connection 的實現類,來組裝 MySQLPacket 并寫入到 Netty 通道中,并且解析編碼后的 MySQLPacketPayload 轉換成 ResultSet。
 圖片
圖片
 圖片
圖片
看起來比較簡單,交互流程和傳統的 JDBC 幾乎一樣,但是由于現在是異步化流程,所有的 Response 都是通過回調返回,所以這里有 2 個難點:
- 由于 MySQL 在上一條命令沒結束前無法接受新的命令,所以如何控制單個連接的命令串行化?
- 如何將 MySQL 返回的數據包和發起命令的 Request 一一綁定?
首先 NettyDbConnection 引入了一個無鎖化非阻塞隊列 ConcurrentLinkedQueue。
 圖片
圖片
在發送 Command 時,如何沒有正在進行中的 Command,則直接發送,如果有正在進行中的 Command,直接扔到隊列中,等待上一條 Command 處理完成后推動下一條命令的執行。保證了單個連接命令串行化。
其次,NettyDbConnection 在執行命令時,傳入一個 Promise,在 MySQL 數據包全部返回后,這個 Promise 將會被設置完成,即可于發起命令的 Request 一一綁定。
 圖片
圖片
自研NIO數據庫連接池
前面介紹了 NettyDbConnection 這個類,實現了與 MySQL 的交互,并且提供了執行 SQL 的高級 API,但實際使用過程中,不可能每次都創建一個連接執行完 SQL 就關閉。所以需要對 NettyDbConnection 進行池化,統一管理連接的生命周期。其功能類似于傳統連接池 HikariCP,在完成基本能力的基礎上,做了很多性能優化。
- 連接生命周期管控
- 連接池動態伸縮
- 完善的監控
- 連接異步保活
- 超時控制
- EventLoop 親和性
這里除了 EventLoop 親和性,其他幾個功能只要用過傳統的數據庫連接池應該都比較熟悉,這里不做過多展開。這里主要針對 EventLoop 親和性展開介紹一下。
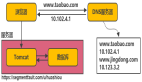
在文章開頭我們說到 Proxy 的三層模塊,Frontend、Core、Backend,如果現在我們把 Backend 層于數據庫交互的組件換成了我們自研的驅動,那么 Proxy 就即是Netty Server,也是Netty Client,所以 Frontend 和 Backend 可以共用一個 EventLoopGroup。為了降低線程上下文切換,在單個請求從 Frontend 接收、經過 Core 層計算后轉發到 MySQL ,再到接收 MySQL 服務響應,以及最終的回寫給 Client 端,這一些列操作盡量放在一個 EventLoop 線程中處理。
 圖片
圖片
具體的做法就是 Backend 在選擇與數據庫連接時,優先選擇與當前 EventLoop 綁定的連接。也就是前面提到的 EventLoop 親和性,這樣就能保證大部分場景下一次請求從頭到尾都由同一個 EventLoop 處理,下面我們看一下具體的代碼實現。
在 NettyDbConnectionPool 類中使用一個 Map 存儲連接池中的空閑連接,Key 為 EventLoop,Value 為當前 EventLoop 綁定的空閑連接隊列。
 圖片
圖片
在獲取時,優先獲取當前 EventLoop 綁定的連接,如果當前 EventLoop 未綁定連接,則會借用其他 EventLoop 的連接。
 圖片
圖片
為了提高 EventLoop 命中率,需要注意幾點配置:
- EventLoop 線程數量盡量與 CPU 核心數保持一致。
- 連接池最大連接數超過 EventLoop 線程數越多,EventLoop 命中率越高。
下面放一張壓測環境(8C16G、連接池最大連接數 10~30)的命中率監控,大部分保持在 75% 左右。
 圖片
圖片
跳過不必要的編解碼
前面說到,有部分 SQL 的結果集是不需要 Proxy 進行加工的,也就是可以直接把 MySQL 返回的數據流原封不動轉發給上游,直接省去編解碼操作。那什么 SQL 是不需要 Proxy 進行加工的呢,我們舉個例子說明一下。
假設邏輯庫 A 里面有一張表 User 做了分庫,分了 2 個庫 DB1 和 DB2,分片算法是 user_id%2。
- SQL 1
SELECT id, name FROM user WHERE user_id in (1, 2)- SQL 2
SELECT id, name FROM user WHERE user_id in (1)很顯然 SQL 1由于有 2 個分片 Value,最終匹配到了 2 個節點,SQL 2 只會匹配到 1 個節點。
 圖片
圖片
SQL 1 由于需要對結果集進行歸并,所以無法跳過編解碼,SQL 2 不需要對結果集歸并,只需要把結果集中的列定義數據做修正后,真正的 Row 數據無需處理,這種情況就可以把 Row 數據直接轉發至上游。
全鏈路異步化
Backend 層用自研連接池+驅動替換原先的 HikariCP+JDBC 后,從 Frontend-Core-Backend 全鏈路涉及到阻塞的操作需要全部替換成異步化編碼,也就是通過 Netty 的 Promise 和 Future 來實現。
 圖片
圖片
由于部分場景拿到 Future 時,可能當前 Future 已經完成了,如果每次都是無腦的加 Listener 會讓調用棧加長,所以我們定義了一個通用的工具類來處理 Future,即 future.isDone() 時直接執行,反之才會 addListener,最大化降低整個調用棧的深度。

兼容性
- 特殊數據庫字段類型處理
- JDBC URL 參數兼容
- ThreadLocal 相關數據全部需要遷移至 ChannelHandlerContext 中
- 日志 MDC、TraceContext 相關數據傳遞
- ……
四、性能表現
經過幾輪性能壓測后,NIO架構相較于BIO架構性能有較大提升:
- 整體最大吞吐量提升 67%
- LOAD 下降 37% 左右
- 高負載情況下 BIO 多次出現進程夯住現象,NIO 相對較穩定
- 線程數減少 98% 左右
五、總結
NIO 架構的改造工作量相當巨大,中間也經歷了一些曲折,但是最終的結果令人滿意。得益于 ShardingShpere 本身內核層面的高性能加上本次 NIO 改造后,彩虹橋在 DAL 中間件性能層面基本上可以算是第一梯隊了。