譯者 | 朱先忠
審校 | 重樓
簡介
層次聚類算法(Agglomerative Clustering)是數據科學中最好的聚類工具之一,但傳統的實現無法擴展到大型數據集領域。
在這篇文章中,我將帶你了解層次聚類算法的一些背景,基于谷歌2021年的研究介紹交互式層次聚類(RAC)算法、RAC++算法和Scikit Learn的層次聚類算法的運行時效果比較,最后將簡要探討一下RAC算法背后的理論支持。
層次聚類算法的背景
在數據科學領域,對未標記的數據進行聚類通常是非常有用的。從搜索引擎結果的分組到基因型分類,再到銀行異常檢測,聚類已經成為數據科學家們的工具包中必不可少的一部分。
層次聚類是數據科學中最流行的聚類方法之一,這是有充分的理由的:
- 易于使用,幾乎不需要參數調整
- 創建有意義的分類法
- 適用于高維數據
- 不需要事先知道簇的數量
- 每次創建相同的簇
相比之下,像K-Means這樣的劃分方法則需要數據科學家猜測聚類的數量,非常流行的基于密度的方法DBSCAN則需要圍繞密度計算半徑(ε)和最小鄰域大小的一些參數,而高斯混合模型對潛在的聚類數據分布做出了強有力的假設。
對于層次聚類算法,您只需要指定一個距離度量指標即可使用。
從高級視角來看,層次聚類遵循以下算法:
- 確定所有簇對之間的簇距離(每個簇從一個點開始);
- 合并彼此最接近的兩個群集;
- 重復上述步驟。
結果是:生成一個美麗的樹狀圖,然后可以根據領域專業知識進行劃分應用。
在生物學和自然語言處理等領域,(細胞、基因或單詞的)簇自然遵循等級關系。因此,層次聚類能夠實現對最終聚類截止點的更自然和數據驅動的選擇。
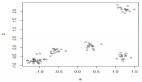
下圖是著名的鳶尾花(Iris)數據集的層次聚類結果示例。
通過萼片長度和萼片寬度對著名的鳶尾花數據集進行聚類(本圖表由合著作者Porter Hunley制作)
那么,為什么不對每個無監督分類問題都使用層次聚類算法呢?答案在于:
隨著數據集大小的增加,層次聚類算法的運行時間表現得非常糟糕。
另一方面,不幸的是,傳統的層次聚類算法還沒有得到大規模的應用。如果使用最小堆結構實現的話,則運行時復雜度為O(n3)或O(n2log(n))。更糟糕的是,層次聚類算法在單核的CPU上按順序運行,無法通過計算進行擴展。
結論是:在自然語言處理領域,層次聚類算法是小型數據集的最佳表現算法。
交互式層次聚類算法
交互式層次聚類(RAC)算法是谷歌提出的一種方法,旨在將傳統型層次聚類算法的優勢擴展到更大的數據集。
RAC算法降低了運行時的復雜性,同時還將操作并行化以利用多核CPU架構。盡管進行了這些優化,但當數據完全連接時,RAC產生的結果與傳統的層次聚類算法卻完全相同(見下文)。
注意:完全連接數據意味著,可以計算任何一對點之間的距離度量。非完全連接的數據集則具有連接約束(通常以連接矩陣的形式提供),其中一些點被認為是斷開的。請參考下面的對比圖示。
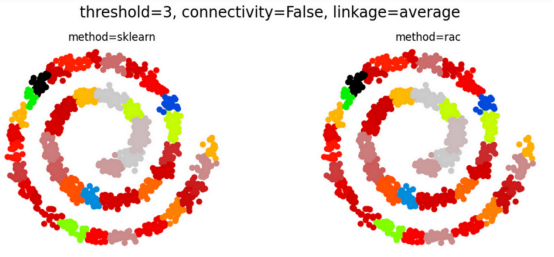
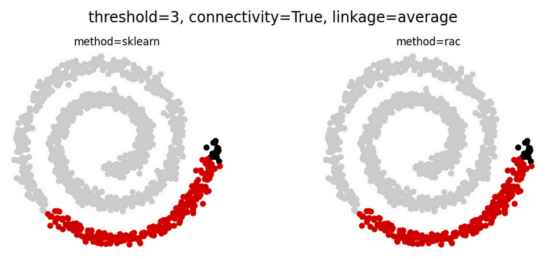
當數據完全連接時,RAC會產生與傳統層次群集完全相同的結果!(上圖),并且通常在連接約束的情況下繼續這樣做(下圖)(圖表由合著作者Porter Hunley制作)
即使存在連接限制(未完全連接的數據),RAC和層次聚類通常仍然相同,如上面的第二個Swiss Roll數據集示例所示。
然而,當可能的簇非常少時,可能會出現巨大的差異。這方面,Noisy Moons數據集就是一個很好的例子:


RAC算法和Sklearn算法之間的計算結果表現出不一致性(本圖表由合著作者Porter Hunley制作)
RAC++算法可擴展到比Scikit-learn更大的數據集
我們可以在Scikit-learn中將RAC++算法(交互式層次聚類的一種實現)算法與其對應的層次聚類算法進行比較。
現在,不妨讓我們生成一些具有25個維度的示例數據,并使用racplusplus.rac與sklearn.cluster.AglognitiveClustering測試層次聚類需要多長時間,應用于大小從1000到64000點的數據集。
注意:下面代碼中,我使用連接矩陣來限制內存消耗。
import numpy as np
import racplusplus
from sklearn.cluster import AgglomerativeClustering
import time
points = [1000, 2000, 4000, 6000, 10000, 14000, 18000, 22000, 26000, 32000, 64000]
for point_no in points:
X = np.random.random((point_no, 25))
distance_threshold = .17
knn = kneighbors_graph(X, 30, include_self=False)
#矩陣必須是對稱的:在Scikit-learn庫的內部完成
symmetric = knn + knn.T
start = time.time()
model = AgglomerativeClustering(
linkage="average",
cnotallow=knn,
n_clusters=None,
distance_threshold=distance_threshold,
metric='cosine'
)
sklearn_times.append(time.time() - start)
start = time.time()
rac_labels = racplusplus.rac(
X, distance_threshold, symmetric,
batch_size=1000, no_cores=8, metric="cosine"
)
rac_times.append(time.time() - start)以下給出的是每個大小數據集的運行時結果圖:
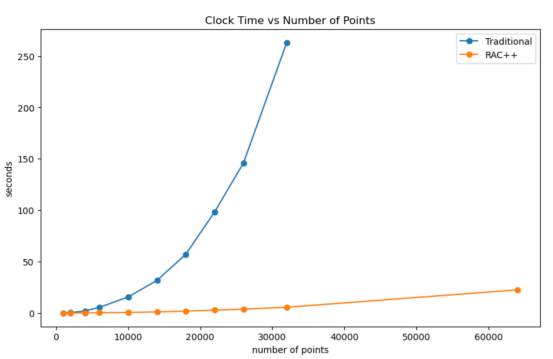
與racplusplus相比,當使用sklearn時,大型數據集的運行時呈爆炸式增長變化趨勢(本圖表由合著作者Porter Hunley制作)
正如我們從上圖中所看到的,RAC++算法和傳統的層次聚類算法在運行時有著巨大的差異。
在剛剛超過30k的點上,RAC++算法的速度大約是原來的100倍!更不可能的是,Scikit-learn的層次聚類達到了約3.5萬個點的時間限制,而RAC++算法在達到合理的時間限制時可以擴展到數十萬個點。
RAC++算法可以擴展到高維度
我們還可以比較RAC++算法在高維數據與傳統數據之間的縮放情況。
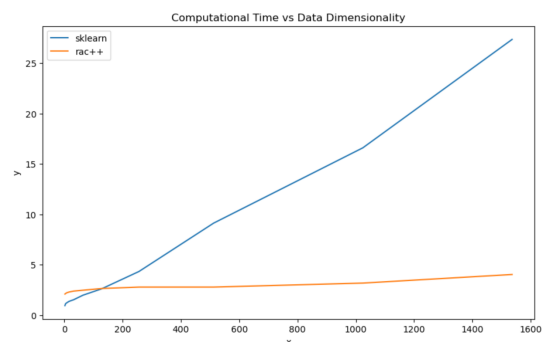
通過RAC++算法和sklearn的數據維度擴展時間復雜性(本圖由合著作者Porter Hunley繪制)
上圖展示了生成3000點的聚類與維度所花費的時間變化規律。
對于3000點的數據量來說,我們可以看到傳統的層次聚類更快,但它是線性的,而RAC++算法表現得幾乎是恒定的。如今,使用768或1536維嵌入已經成為NLP領域的常規指標;因此,縮放維度以滿足這些要求是很重要的。
RAC++算法表現出具有更好的運行時性能
谷歌的研究人員證明,RAC算法的運行時間為O(nk),其中k表示連接約束,而n代表點的數量——線性運行時間。然而,這不包括初始距離矩陣的計算,即O(n2)——二次運行時。
我們的結果,運行恒定的30個鄰連接約束情況下,確實證實了將使用O(n2)復雜度的運行時狀態:
+ — — — — — — -+ — — — — — +
| Data points | Seconds |
+ - - - - - - -+ - - - - - +
| 2000 | 0.051 |
| 4000 | 0.125 |
| 6000 | 0.245 |
| 10000 | 0.560 |
| 14000 | 1.013 |
| 18000 | 1.842 |
| 22000 | 2.800 |
| 26000 | 3.687 |
| 32000 | 5.590 |
| 64000 | 22.499 |
+ - - - - - - -+ - - - - - +將數據點增加一倍對應于時間的4倍。
二次運行時限制了RAC++算法在數據集變得真正龐大時的性能,然而,與傳統的O(n3)或最小堆優化O(n2log(n))運行時相比,該運行時已經有了很大的改進。
注意:RAC++算法的開發人員正在將距離矩陣作為一個參數進行傳遞,該參數將為RAC++算法提供線性運行時間。
RAC算法的工作原理
為什么RAC++算法更為快速呢?我們可以將底層算法簡化為如下幾個步驟:
- 將簇與交互的最近鄰配對
- 合并成對的簇
- 更新鄰接簇
注意,這與傳統的層次聚類算法之間的唯一區別是,我們確保將交互最近鄰的簇配對在一起。這就是交互層次聚類(RAC)這個名稱的由來。正如您將看到的,這種交互配對使我們能夠并行化層次聚類中計算成本最高的步驟。
將簇與交互最近鄰配對
首先,我們循環尋找具有交互最近鄰的簇,這意味著它們的最近鄰是彼此(記住,距離可以是定向的!)。
") 識別交互最近鄰簇(本圖由合著作者Porter Hunley繪制)
識別交互最近鄰簇(本圖由合著作者Porter Hunley繪制)
合并成對的簇
RAC算法是可并行執行的,因為只要連接方法是可還原的,交互最近鄰的合并順序無關緊要。
連接方法是根據每個聚類中包含的點之間的成對距離來確定兩個聚類之間距離的函數。可還原連接方法保證新合并的簇在合并后不會更接近任何其他簇。
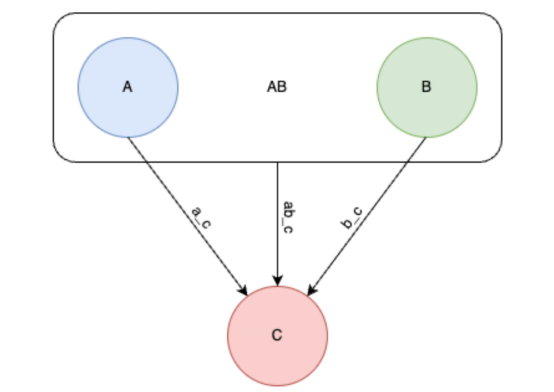
如果使用可還原連接,則ab_c將不會比ac或bc更接近(此圖由合著作者Porter Hunley繪制)
幸運的是,四種最流行的連接方法都是可還原的:
- 單連接——最小距離
- 平均連接——距離的平均值
- 完全連接——最大距離
- 離差平方和法連接——最小方差
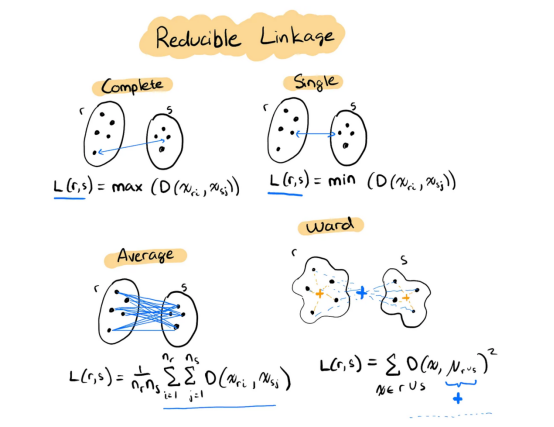
4種可還原連接方法的可視化表示(我本人繪制,靈感來自http://www.saedsayad.com/clustering_hierarchical.htm)
由于我們知道我們識別的交互對是彼此的最近鄰居,并且我們知道可還原連接合并永遠不會使新合并的簇更接近另一個簇,因此我們可以安全地將所有交互最近鄰居對同時合并在一起。每個最近鄰居對可以被放置到一個可用線程中,以便根據連接方法進行合并。
我們可以同時合并交互最近的鄰居,這一事實非常棒,因為合并簇是計算成本最高的步驟!
") 可視化準備合并的簇(本圖由合著作者Porter Hunley繪制)
可視化準備合并的簇(本圖由合著作者Porter Hunley繪制)
更新最近鄰簇
對于可還原連接,合并后更新最近鄰的順序也無關緊要。因此,通過一些巧妙的設計,我們也可以并行地更新相關的鄰居。
") 在合并后識別新的最近鄰簇(本圖片由合著作者Porter Hunley繪制)
在合并后識別新的最近鄰簇(本圖片由合著作者Porter Hunley繪制)
結論
通過一些測試數據集,我們已經表明,對于完全連接的數據集,RAC++算法在更好的運行時產生與傳統的層次聚類算法(即sklearn中所提供的)完全相同的結果。通過對可還原連接度量指標的解釋和對并行編程支持的基本分析,我們最終理解了使RAC++算法更快的邏輯。
為了更完整地理解(和證明)RAC++算法在開源包中所采用的算法,有興趣的讀者可以查看它所基于的谷歌原始研究成果。
未來的工作
目前,Porter Hunley已經開始構建RAC++算法,努力為通過微調BERT嵌入產生的臨床術語端點創建分類法支持。這些醫學嵌入中的每一個都有768個維度,在他嘗試的許多聚類算法中,只有層次聚類算法給出了良好的結果。
所有其他的高規模聚類方法都需要降維才能給出任何連貫的結果。不幸的是,當前還不存在一種很有把握的方法用于降低維度——你總是會丟失一些信息。
在發現谷歌圍繞RAC的研究成果后,波特決定構建一個自定義的開源簇實現,以支持他的臨床術語簇研究。Porter負責開發,我和他共同開發了RAC算法的一些部分,特別是在python中封裝C++實現,優化運行時,以及打包軟件以供分發方面。
總之,RAC++算法支持大量簇應用程序,這些應用程序使用傳統的層次聚類表現得太慢,最終將擴展到數百萬個數據點。
最后,盡管RAC++算法現在已經可以用于簇式大型數據集,但仍存在不少有待改進之處……RAC++算法仍在開發中!
本文特約作者:
- Porter Hunley,Daceflow.ai高級軟件工程師:他的GitHub代碼倉庫是https://github.com/porterehunley
- Daniel Frees,斯坦福大學統計與數據科學碩士生,IBM數據科學家:他的github代碼倉庫是https://github.com/danielfrees
注:GitHub——porterehunley/RAPlusplus:交互聚集的高性能實現……
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Scaling Agglomerative Clustering for Big Data,作者:Daniel Frees