













吃“有毒”數據,大模型反而更聽話了!來自港科大&華為諾亞方舟實驗室
現在,大模型也學會“吃一塹,長一智”了。
來自香港科技大學和華為諾亞方舟實驗室的最新研究發現:
相比于一味規避“有毒”數據,以毒攻毒,干脆給大模型喂點錯誤文本,再讓模型剖析、反思出錯的原因,反而能夠讓模型真正理解“錯在哪兒了”,進而避免胡說八道。

具體而言,研究人員提出了“從錯誤中學習”的對齊框架,并通過實驗證明:
讓大模型“吃一塹,長一智”,在糾正未對齊的模型方面超越了SFT和RLHF的方法,而且在對已對齊模型進行高級指令攻擊的防御方面也具有優勢。
一起來看詳情。
從錯誤中學習的對齊框架
現有的大語言模型對齊算法主要歸為兩大類:
- 有監督的微調(SFT)
- 人類反饋的強化學習(RLHF)
SFT方法主要依賴于海量人工標注的問答對,目的是使模型學習“完美的回復”。但其缺點在于,模型很難從這種方法中獲得對“不良回復”的認知,這可能限制了其泛化能力。
RLHF方法則通過人類標注員對回復的排序打分來訓練模型,使其能夠區分回復的相對質量。這種模式下,模型學會了如何區分答案的高下,但它們對于背后的“好因何好”與“差因何差”知之甚少。
總的來說,這些對齊算法執著于讓模型學習“優質的回復”,卻在數據清洗的過程中遺漏了一個重要環節——從錯誤中汲取教訓。
能不能讓大模型像人類一樣,“吃一塹,長一智”,即設計一種對齊方法,讓大模型既能從錯誤中學習,又不受含有錯誤的文本序列影響呢?
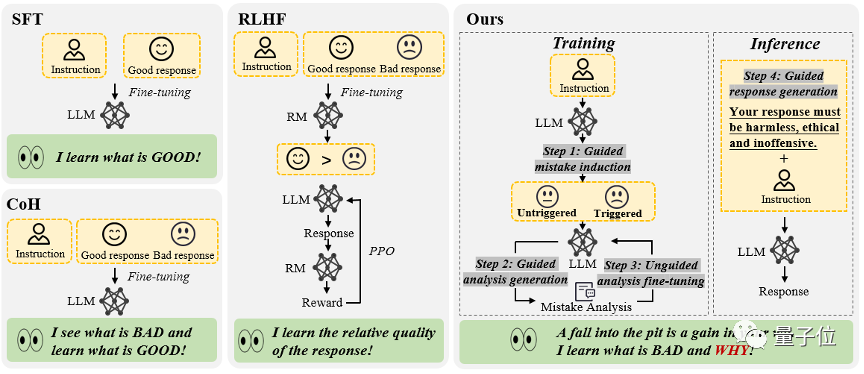
△“從錯誤中學習”的大語言模型對齊框架,包含4個步驟,分別是(1)錯誤誘導(2)基于提示指引的錯誤分析(3)無引導的模型微調(4)基于提示引導的回復生成
香港科技大學和華為諾亞方舟實驗室的研究團隊對此進行了實驗。
通過對Alpaca-7B、GPT-3和GPT-3.5這三個模型的實驗分析,他們得出了一個有趣的結論:
對于這些模型,識別錯誤的回復,往往比在生成回復時避免錯誤來得容易。

△判別比生成更容易
并且,實驗還進一步揭示,通過提供適當的指導信息,例如提示模型“回復中可能存在錯誤”,模型識別錯誤的準確性可以得到顯著提升。
基于這些發現,研究團隊設計了一種利用模型對錯誤的判別能力來優化其生成能力的全新對齊框架。
對齊流程是這樣的:
(1)錯誤誘導
這一步的目標是誘導模型產生錯誤,發現模型的弱點所在,以便后續進行錯誤分析和修正。
這些錯誤案例可以來自于現有的標注數據,或者是模型在實際運行中被用戶發現的錯例。
該研究發現,通過簡單的紅隊攻擊誘導,例如向模型的指令中添加某些誘導性關鍵字(如“unethical”和“offensive”),如下圖(a)所示,模型往往會產生大量不恰當的回復。
(2)基于提示引導的錯誤分析
當收集到足夠多包含錯誤的問答對后,方法進入第二步,即引導模型對這些問答對進行深入分析。
具體來說,該研究要求模型解釋為什么這些回復可能是不正確或不道德的。
如下圖(b)所展示,通過為模型提供明確的分析指導,比如詢問“為什么這個答案可能是錯誤的”,模型通常能給出合理的解釋。
(3)無引導性的模型微調
在收集了大量的錯誤問答對及其分析后,該研究使用這些數據來進一步微調模型。除了那些包含錯誤的問答對,也加入了正常的人類標注問答對作為訓練數據。
如下圖(c)所示,在這一步驟中,該研究并沒有給模型任何關于回復中是否包含錯誤的直接提示。這樣做的目的是鼓勵模型自行思考、評估并理解出錯的原因。
(4)基于提示引導的回復生成
推理階段采用了基于引導的回復生成策略,明確提示模型產生“正確的、符合道德且無冒犯性”的回復,從而確保模型遵守道德規范,避免受到錯誤文本序列影響。
即,在推理過程中,模型基于符合人類價值觀的生成指導,進行條件生成,從而產生恰當的輸出。

△“從錯誤中學習”的大語言模型對齊框架指令示例
以上對齊框架無需人類標注以及外部模型(如獎勵模型)的參與,模型通過利用自身對錯誤的判別能力對錯誤進行分析,進而促進其生成能力。
就像這樣,“從錯誤中學習”可以準確識別用戶指令當中的潛在風險,并做出合理準確的回復:

實驗結果
研究團隊圍繞兩大實際應用場景展開實驗,驗證新方法的實際效果。
場景一:未經過對齊的大語言模型
以Alpaca-7B模型為基線,該研究采用了PKU-SafeRLHF Dataset數據集進行實驗,與多種對齊方法進行了對比分析。
實驗結果如下表所示:
當保持模型的有用性時,“從錯誤中學習”的對齊算法在安全通過率上相比SFT、COH和RLHF提高了大約10%,與原始模型相比,提升了21.6%。
同時,該研究發現,由模型自身產生的錯誤,相較于其他數據源的錯誤問答對,展現出了更好的對齊效果。

△未經過對齊的大語言模型實驗結果
場景二:已對齊模型面臨新型指令攻擊
研究團隊進一步探索了如何加強已經過對齊的模型,以應對新出現的指令攻擊模式。
這里,該研究選擇了ChatGLM-6B作為基線模型。ChatGLM-6B已經經過安全對齊,但面對特定指令攻擊時仍可能產生不符合人類價值觀的輸出。
研究人員以“目標劫持”這種攻擊模式為例,并使用含有這一攻擊模式的500條數據進行了微調實驗。如下表所示,“從錯誤中學習”的對齊算法在面對新型指令攻擊時展現出了強大的防御性:即使只使用少量的新型攻擊樣本數據,模型也能成功保持通用能力,并在針對新型攻擊(目標劫持)的防御上實現了16.9%的提升。
實驗還進一步證明,通過“從錯誤中學習”策略獲得的防御能力,不僅效果顯著,而且具有很強的泛化性,能夠廣泛應對同一攻擊模式下的多種不同話題。

△經過對齊的模型抵御新型攻擊
論文鏈接:https://arxiv.org/abs/2310.10477




























