從基礎到實踐,回顧 Elasticsearch 向量檢索發展史

1.引言
向量檢索已經成為現代搜索和推薦系統的核心組件。
通過將復雜的對象(例如文本、圖像或聲音)轉換為數值向量,并在多維空間中進行相似性搜索,它能夠實現高效的查詢匹配和推薦。
Elasticsearch 作為一款流行的開源搜索引擎,其在向量檢索方面的發展也一直備受關注。本文將回顧 Elasticsearch 向量檢索的發展歷史,重點介紹各個階段的特點和進展。以史為鑒,方便大家建立起 Elasticsearch 向量檢索的全量認知。
2. 初步嘗試:簡單向量檢索的引入
Elasticsearch 最初并未專門針對向量檢索進行設計。然而,隨著機器學習和人工智能的興起,對于高維向量空間的查詢需求逐漸增長。
在 Elasticsearch 的 5.x 版本中,Elastic 愛好者們開始嘗試通過插件和基本的數學運算實現簡單的向量檢索功能。如:一些早期的插件如 elasticsearch-vector-scoring、fast-elasticsearch-vector-scoring 就是為了滿足這樣的需求。
https://github.com/MLnick/elasticsearch-vector-scoring
https://github.com/lior-k/fast-elasticsearch-vector-scoring
這一階段的向量檢索主要用于基本的相似度查詢,例如文本相似度計算。雖然功能相對有限,但為后續的發展奠定了基礎。
擴展說明:關于機器學習功能,如果大家對 Elasticsearch 版本更迭感興趣,印象中當時 6.X 版本推出,非常振奮人心。不過受限于非開源功能,國內的真實受眾還相對較少。
3. 官方支持:進一步發展
到 Elasticsearch 7.0 版本,正式開始增加對向量字段的支持,例如通過 dense_vector 類型。這標志著 Elasticsearch 正式進入向量檢索領域,不再只依賴于插件。
dense_vector 最早的發起時間:2018 年 12 月 13 日,7.6 版本標記為 GA。
https://github.com/elastic/elasticsearch/pull/33022
https://github.com/elastic/elasticsearch-net/issues/3836
關于 dense_vector 類型的使用,推薦閱讀:高維向量搜索:在 Elasticsearch 8.X 中利用 dense_vector 的實戰探索。
這一階段的主要挑戰是如何有效地在傳統的倒排索引結構中支持向量檢索。通過與現有的全文搜索功能相結合,Elasticsearch 能夠提供一種靈活而強大的解決方案。
從最初的插件和基本運算,到后來的官方支持和集成,這一階段為 Elasticsearch 在向量檢索方面的進一步創新和優化奠定了堅實的基礎。
4.專門優化:增強的相似度計算
隨著需求的增長,Elasticsearch 團隊開始深入研究并優化向量檢索性能。這涉及了引入更復雜的相似度計算方法,例如余弦相似度、歐幾里得距離等,以及對查詢執行的優化。
從 Elasticsearch 7.3 版本開始,官方引入了更復雜的相似度計算方法。特別是 script_score 查詢的增強,使用戶可以通過 Painless 腳本自定義更豐富的相似度計算。
/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions
核心功能在于允許通過向量之間的夾角計算相似度,用 k 最近鄰 (k-NN) 的余弦相似度距離指標,從而為相似度搜索引擎提供支持。廣泛用于文本分析和推薦系統。
主要用于解決:復雜相似度需求,提供了更靈活和強大的相似度計算選項,能夠滿足更多的業務需求。
應用場景體現在:
個性化推薦:通過余弦相似度分析用戶的行為和興趣,提供更個性化的推薦內容;
圖像識別和搜索:使用歐幾里得距離快速檢索與給定圖像相似的圖像;
聲音分析:在聲音文件之間尋找相似模式,用于語音識別和分析。值得一提的是:初始的時候,向量檢索支持的維度為:1024,直到 Elasticsearch 8.8 版本,支持維度變更為:2048(這是呼聲很高的一個需求)。
https://github.com/elastic/elasticsearch/pull/95257
/t/vector-knn-search-with-more-than-1024-dimensions/332819
Elasticsearch 7.x 版本的增強相似度計算功能標志著向量檢索能力的顯著進展。通過引入更復雜的相似度計算方法和查詢優化,Elasticsearch 不僅增強了其在傳統搜索場景中的功能,還為新興的機器學習和 AI 應用打開了新的可能性。
但,這個時候你會發現,如果要實現復雜的向量搜索功能,自己實現的還很多。如果把后面馬上提到的深度學習的集成和大模型的出現比作:飛行的汽車,當前的階段還是 “拉驢車”,功能是有的,但用起來很費勁。

5.深度學習集成與未來展望
大模型時代,向量檢索和多模態搜索成為 “兵家” 必爭之地。
多模態檢索是一種綜合各種數據模態(如文本、圖像、音頻、視頻等)的檢索技術。換句話說,它不僅僅是根據文字進行搜索,還可以根據圖像、聲音或其他模態的輸入來搜索相關內容。
為了更通俗地理解多模態檢索,我們可以通過以下比喻和示例來加深認識:想象你走進一個巨大的圖書館,這里不僅有書籍,還有各種圖片、錄音和視頻。你可以向圖書館員展示一張照片,她會為你找到與這張照片相關的所有書籍、音頻和視頻。或者,你可以哼一段旋律,圖書館員能找到相關的資料,或者提供類似的歌曲或視頻。這就是多模態檢索的魔力!
隨著深度學習技術的不斷發展和應用,Elasticsearch 已開始探索將深度學習模型直接集成到向量檢索過程中。這不僅允許更復雜、更準確的相似度計算,還開辟了新的應用領域,例如基于圖像或聲音的搜索。尤其在 Elasticsearch 的 8.x 版本,這一方向得到了顯著的推進。
5.1 向量化是前提
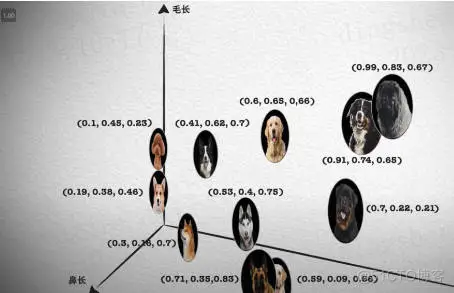
如下圖所示,先從左往右看是寫入,圖像、文檔、音頻轉化為向量特征表示,在 Elasticsearch 中通過 dense_vector 類型存儲。
從右往左看是檢索,先將檢索語句轉化為向量特征表示,然后借助 K 近鄰檢索算法(在 Elasticsearch 中借助 Knn search 實現),獲取相似的結果。
看中間,Results 部分就是向量檢索的結果。
綜上,向量檢索打破了傳統倒排索引僅支持文本檢索的缺陷,可以擴展支持文本、語音、圖像、視頻多種模態。
 圖片來自:Elasticsearch 官方文檔
圖片來自:Elasticsearch 官方文檔
相信你到這里,應該理解了向量檢索和多模態。沒有向量化的這個過程,多模態檢索無從談起。
5.2 模型是核心
深度學習模型集成總共可分為三步:
第一步:模型導入和管理:Elasticsearch 8.x 支持導入預訓練的深度學習模型,并提供相應的模型管理工具,方便模型的部署和更新。
第二步:向量表示與轉換:通過深度學習模型,可以將非結構化數據如圖像和聲音轉換為向量表示,從而進行有效的檢索。
第三步:自定義相似度計算:8.x 版本提供了基于深度學習模型的自定義相似度計算接口,允許用戶根據實際需求開發和部署專門的相似度計算方法。關于深度學習,可以是自訓練模型,也可以是第三方模型庫中的模型,舉例:咱們圖搜圖案例中就是用的 HuggingFace 里的:clip-ViT-B-32-multilingual-v1 模型。
 從基礎到實踐,回顧Elasticsearch 向量檢索發展史_Elastic_04
從基礎到實踐,回顧Elasticsearch 向量檢索發展史_Elastic_04
Elasticsearch 支持的第三方模型列表:
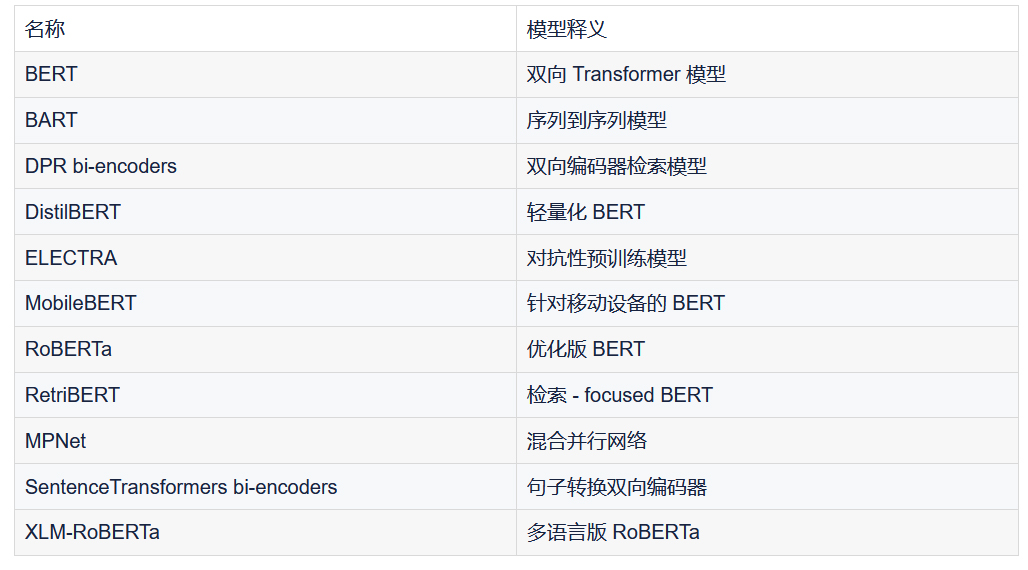
包括如下的 Hugging Face 模型庫也都是支持的。
 從基礎到實踐,回顧Elasticsearch 向量檢索發展史_elasticsearch_05
從基礎到實踐,回顧Elasticsearch 向量檢索發展史_elasticsearch_05
模型是 Elasticsearch 與深度學習集成的核心,它能將復雜的數據轉化為 “指紋” 向量,使搜索更高效和智能。借助模型,Elasticsearch 可以理解和匹配各種非結構化數據,如圖像和聲音,提供更為準確和個性化的搜索結果,同時適應不斷變化的數據和需求。“沒有了模型,我們還需要黑暗中摸索很久”。
第三方模型官網介紹:/guide/en/machine-learning/8.9/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding
值得一提的是:Elasticsearch 導入大模型需要專屬 Python 客戶端工具 Eland。
Eland 是一個 Python Elasticsearch 客戶端,讓用戶能用類似 Pandas 的 API 來探索和分析 Elasticsearch 中的數據,還支持從常見機器學習庫上傳訓練好的模型到 Elasticsearch。
Eland 是為了與 Elasticsearch 協同工作而開發的庫。它不是 Elasticsearch 的一個特定版本產物,而是作為一個獨立的項目來幫助 Python 開發者更方便地在 Elasticsearch 中進行數據探索和機器學習任務。
Eland 更多參見:
/guide/en/elasticsearch/client/eland/current/index.html
https://github.com/elastic/eland
5.3 ESRE 是 Elastic 的未來
前一段時間在分別給兩位阿里云、騰訊云大佬聊天的時候,都提到了 Elasticsearch Relevance Engine (ESRE) 才是 Elastic 未來。
ESRE 官方介紹如下:——Elasticsearch Relevance Engine 將 AI 的最佳實踐與 Elastic 的文本搜索進行了結合。ESRE 為開發人員提供了一整套成熟的檢索算法,并能夠與大型語言模型 (LLM) 集成。借助 ESRE,我們可以應用具有卓越相關性的開箱即用型語義搜索,與外部大型語言模型集成,實現混合搜索,并使用第三方或我們自己的模型。
ESRE 集成了高級相關性排序如 BM25f、強大的矢量數據庫、自然語言處理技術、與第三方模型如 GPT-3 和 GPT-4 的集成,并支持開發者自定義模型與應用。其特點在于提供深度的語義搜索,與專業領域的數據整合,以及無縫的生成式 AI 整合,讓開發者能夠構建更吸引人、更準確的搜索體驗。
在 Elasticsearch 8.9 版本上新了:Semantic search 語義檢索功能,對官方文檔熟悉的同學,你會發現如下截圖內容,早期版本是沒有的。
語義搜索不是根據搜索詞進行字面匹配,而是根據搜索查詢的意圖和上下文含義來檢索結果。
更進一步講:語義搜索不僅僅是匹配你輸入的關鍵字,而是試圖理解你的真正意圖,給你帶來更準確、更有上下文的搜索結果。簡單來說,如果你在英國搜索 “football”,系統知道你可能想要搜橄欖球,而不是足球(在美國 football 是足球)。
這種智能搜索方式,得益于強大的文本向量化等技術背景,使我們的在線搜索體驗更加直觀、方便和滿意。
在文本里檢索 connection speed requirement, 這點屬于早期的倒排索引檢索方式,或者叫全文檢索中的短語 match_phrase 檢索匹配 或者分詞 match 檢索匹配。這種可以得到結果。
但是,中后半段視頻顯示,要是咱們要檢索:“How fast should my internet be” 怎么辦?其實這里轉換為向量檢索,fast 和 speed 語義相近,should be 和 required、needs 語義相近,internet 和 connection、wifi 語義相近。所以依然能召回結果。
這突破了傳統同義詞的限制,體現了語義檢索的妙處!
更進一步,我們給出語義檢索和傳統分詞檢索的區別,以期望大家更好的理解語義搜索。
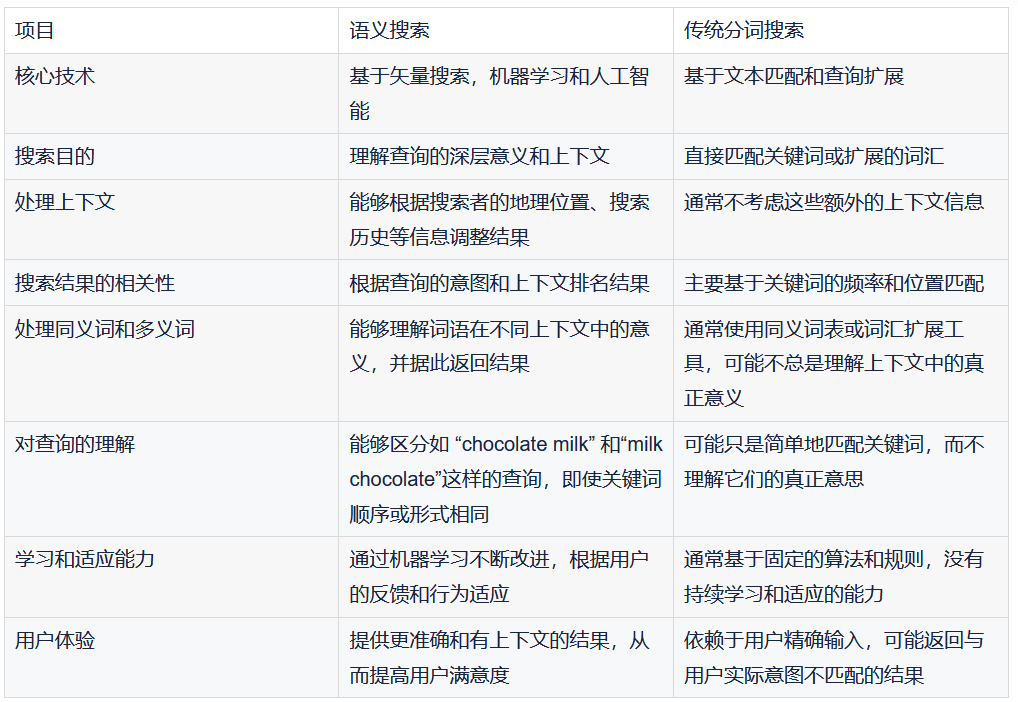
總體而言,深度學習集成已經成為 Elasticsearch 向量檢索能力的有力補充,促使它在搜索和分析領域的地位更加牢固,同時也為未來的發展提供了廣闊的空間。
6.小結
Elasticsearch 的向量檢索從最初的簡單實現發展到現在的高效、多功能解決方案,反映了現代搜索和推薦系統的需求和挑戰。隨著技術的不斷演進,我們可以期待 Elasticsearch 在向量檢索方面將繼續推動創新和卓越。
說一下最近的感觸,向量檢索、大模型等新技術的出現有種感覺 “學不完,根本學不完”,并且很容易限于 “皮毛論”(我自創的詞)——所有技術都了解一點點,但經不起提問;淺了說,貌似啥都懂,深了說,一問三不知。
這種情況怎么辦?我目前的方法是:以實踐為目的去深入理解理論,必要時理解算法,然后不定期將所看、所思、所想梳理成文,以備忘和知識體系化。這個過程很慢、很累,但我相信時間越長、價值越大。
歡迎大家就向量檢索等問題進行留言討論交流,你的問題很可能就是下一次文章的主題哦!
7.參考
/cn/blog/text-similarity-search-with-vectors-in-elasticsearch
/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions-cosine