1個token終結(jié)LLM數(shù)字編碼難題!九大機構(gòu)聯(lián)合發(fā)布xVal:訓(xùn)練集沒有的數(shù)字也能預(yù)測!
雖然大型語言模型(LLM)在文本分析和生成任務(wù)上的性能非常強大,但在面對包含數(shù)字的問題時,比如多位數(shù)乘法,由于模型內(nèi)部缺乏統(tǒng)一且完善的數(shù)字分詞機制,會導(dǎo)致LLM無法理解數(shù)字的語義,從而胡編亂造答案。
目前LLM還沒有廣泛應(yīng)用于科學(xué)領(lǐng)域數(shù)據(jù)分析的一大阻礙就是數(shù)字編碼問題。
最近,熨斗研究所(Flatiron Institute)、勞倫斯伯克利國家實驗室、劍橋大學(xué)、紐約大學(xué)、普林斯頓大學(xué)等九個研究機構(gòu)聯(lián)合發(fā)布了一個全新的數(shù)字編碼方案xVal,只需一個token即可對所有數(shù)字進行編碼。

論文鏈接:https://arxiv.org/pdf/2310.02989.pdf
xVal通過將專用token([NUM])的嵌入向量按數(shù)值縮放來表示目標(biāo)真實值,再結(jié)合修改后的數(shù)字推理方法,xVal策略成功使模型在輸入字符串?dāng)?shù)字到輸出數(shù)字之間映射時端到端連續(xù),更適合科學(xué)領(lǐng)域的應(yīng)用。
在合成和真實世界數(shù)據(jù)集上的評估結(jié)果顯示,xVal比現(xiàn)有的數(shù)字編碼方案不僅性能更好,而且更節(jié)省token,還表現(xiàn)出更好的插值泛化特性。
數(shù)字編碼新突破
標(biāo)準的LLM分詞方案并沒有對數(shù)字和文本進行區(qū)分,也就無法對數(shù)值進行量化。
之前有工作按照科學(xué)計數(shù)法的形式,以10為基底,將所有數(shù)字映射到有限的原型數(shù)字(prototype numerals)集合中,或是計算數(shù)字embedding之間的余弦距離來反映數(shù)字本身的數(shù)值差異,已經(jīng)成功用于解決線性代數(shù)問題,諸如矩陣乘法等。
不過對于科學(xué)領(lǐng)域中的連續(xù)或平滑問題,語言模型仍然無法很好地處理插值和分布外泛化問題,因為將數(shù)字編碼為文本后,LLM在編碼和解碼階段本質(zhì)上仍然是離散的,很難學(xué)習(xí)近似連續(xù)函數(shù)。
xVal的思路是對數(shù)值大小進行乘法(multiplicatively)編碼,并在嵌入空間中將其定向到可學(xué)習(xí)的方向,極大地改變了Transformer架構(gòu)中處理和解釋數(shù)字的方式。
xVal使用單個token進行數(shù)字編碼,具有token效率的優(yōu)勢以及最小的詞典足跡(vocabulary footprint)。
結(jié)合修改后的數(shù)字推理范式,Transformer模型值在輸入數(shù)字和輸出字符串的數(shù)字之間的映射時是連續(xù)的(平滑),當(dāng)近似的函數(shù)是連續(xù)或平滑時,可以帶來更好的歸納偏差(inductive bias)。
xVal: 連續(xù)數(shù)字編碼
xVal沒有對不同的數(shù)字使用不同的token,而是直接沿著嵌入空間中特定可學(xué)習(xí)方向嵌入數(shù)值。
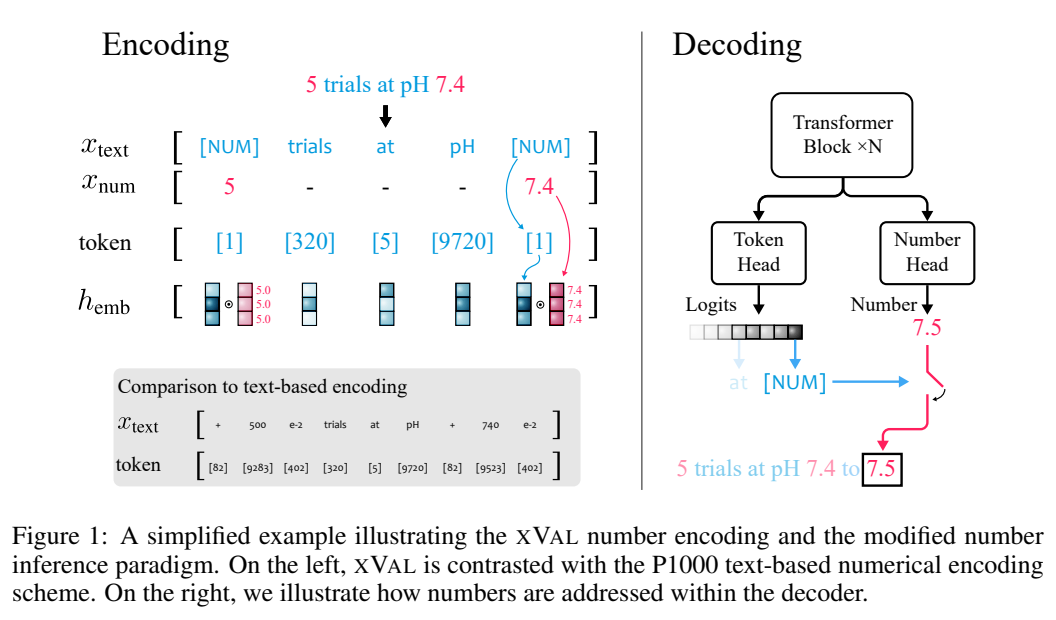
假設(shè)輸入字符串中同時包含數(shù)字和文本,系統(tǒng)首先會對輸入進行解析,提取出所有的數(shù)值,然后構(gòu)造出一個新的字符串,其中數(shù)字被替換為[NUM]占位符,再將[NUM]的嵌入向量與其所對應(yīng)的數(shù)值相乘。
整個編碼過程可以用于遮罩語言建模(MLM)和自回歸(AR)生成。
基于層歸一化的隱式歸一化(Implicit normalization via layer-norm)
在具體實現(xiàn)中,第一個Transformer塊中的xVal的乘法嵌入(multiplicative embedding)之后需要加上位置編碼向量,以及層歸一化(layer-norm),基于輸入樣本對每個token的嵌入進行歸一化。
當(dāng)位置嵌入與[NUM]標(biāo)記的嵌入不共線(collinear)時,標(biāo)量值可以通過非線性重縮放函數(shù)(non-linear rescaling)進行傳遞。
假設(shè)u為[NUM]的嵌入,p為位置嵌入,x是被編碼的標(biāo)量值,為了簡化計算可以假定u · p=0,其中∥u∥ =∥p∥ = 1,可以得到

即x的值被編碼為與u同方向,并且該屬性在訓(xùn)練后仍然可以保持。

這種歸一化特性意味著xVal的動態(tài)范圍比其他基于文本的編碼方案的動態(tài)范圍更小,在實驗中設(shè)定為[-5, 5]以作為訓(xùn)練前的預(yù)處理步驟。
數(shù)值推理
xVal定義了在輸入數(shù)值中連續(xù)的嵌入,但如果使用多分類任務(wù)作為輸出和訓(xùn)練算法時,考慮到從輸入數(shù)值到輸出數(shù)值之間的映射,則模型作為一個整體不是端到端連續(xù)的,需要在輸出層單獨對數(shù)字進行處理。

根據(jù)Transformer語言模型中的標(biāo)準實踐,研究人員定義了一個token head,輸出詞匯表token的概率分布。
因為xVal使用[NUM]對數(shù)字進行替換,所以head不攜帶任何關(guān)于數(shù)值的信息,所以需要引入了一個具有標(biāo)量輸出的新number head,通過均方誤差(MSE)損失進行訓(xùn)練,以恢復(fù)與[NUM]相關(guān)聯(lián)的具體數(shù)值。
給定輸入后,首先觀察token head的輸出,如果生成的token為[NUM],則查看number head來填充該token的值。
在實驗中,由于Transformer模型在推斷數(shù)值時是端到端連續(xù)的,所以當(dāng)插值到未見過的數(shù)值時表現(xiàn)得更好。
實驗部分
對比其他數(shù)字編碼方法
研究人員將XVAL的性能與其他四種數(shù)字編碼進行了比較,這些方法都需要先將數(shù)字處理為±ddd E±d的形式,然后再根據(jù)格式調(diào)用單個或多個token來確定編碼。

不同方法對于編碼每個數(shù)字所需要的token數(shù)量、詞匯表數(shù)量都有很大不同,但總體來看,xVal的編碼效率是最高的,并且詞匯表尺寸也最小。
研究人員還在三個數(shù)據(jù)集上對xVal進行評估,包括合成的算術(shù)運算數(shù)據(jù)、全球溫度數(shù)據(jù)和行星軌道模擬數(shù)據(jù)。
學(xué)習(xí)算術(shù)
即使對于最大的LLM來說,「多位數(shù)乘法」也仍然是一個極具挑戰(zhàn)的任務(wù),例如GPT-4在三位數(shù)乘法問題上僅能達到59%的zero-shot準確率,在四位數(shù)和五位數(shù)乘法問題上的準確率甚至只有4%和0%
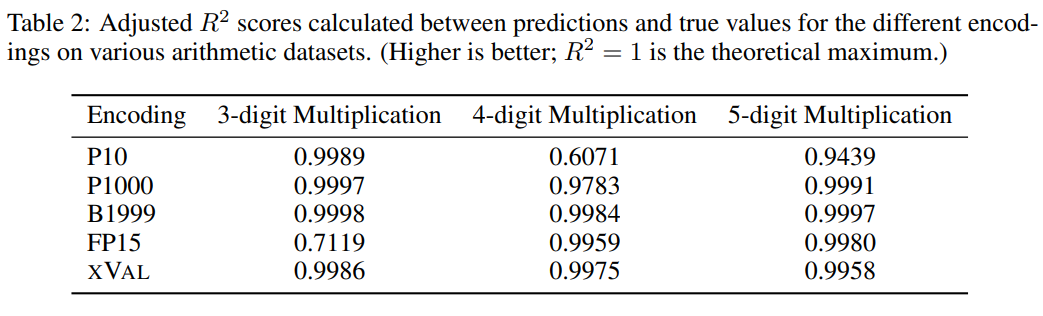
從對比實驗來看,其他數(shù)字編碼通常也能很好地解決多位數(shù)乘法問題,不過xVal的預(yù)測結(jié)果相比P10和FP15來說更穩(wěn)定,不會產(chǎn)生異常預(yù)測值。
為了提升任務(wù)難度,研究人員使用隨機二叉樹,使用加法、減法和乘法的二元運算符組合固定數(shù)量的操作數(shù)(2、3或4)構(gòu)造出了一個數(shù)據(jù)集,其中每個樣本都是一個算術(shù)表達式,例如((1.32 * 32.1) + (1.42-8.20)) = 35.592
然后根據(jù)每個數(shù)字編碼方案的處理要求對樣本進行處理,任務(wù)目標(biāo)是計算等式左側(cè)的表達式,即等式右側(cè)為掩碼。
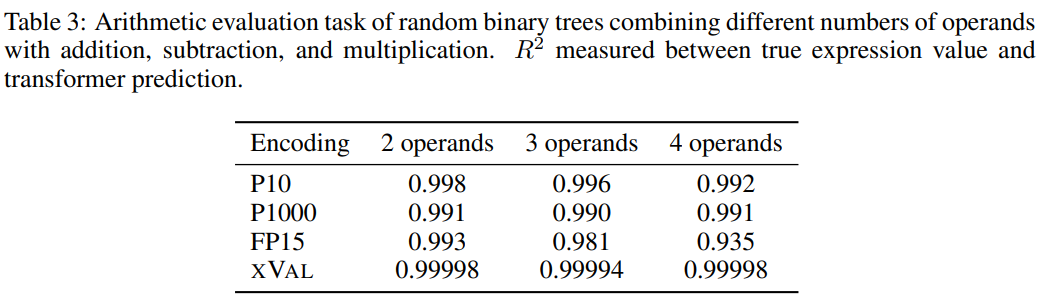
從結(jié)果來看,xVal在這個任務(wù)上表現(xiàn)得非常好,不過單靠算術(shù)實驗不足以完全評估語言模型的數(shù)學(xué)能力,因為算術(shù)運算中的樣本通常是短序列,底層數(shù)據(jù)流形是低維的,這些問題并沒有突破LLMs在計算上的瓶頸,而現(xiàn)實世界中的應(yīng)用更復(fù)雜。
溫度預(yù)測
研究人員使用ERA5全球氣候數(shù)據(jù)集的子集用作評估,簡單起見,實驗中只關(guān)注地表溫度數(shù)據(jù)(ERA5中的T2m),然后對樣本進行劃分,其中每個樣本包括2-4天的地表溫度數(shù)據(jù)(一化后具有單位方差)以及來自60-90個隨機選擇的報告站的緯度和經(jīng)度。
對坐標(biāo)的緯度的正弦和經(jīng)度的正弦和余弦編碼,從而保持數(shù)據(jù)的周期性,然后使用同樣的操作對24小時和365天周期中位置進行編碼。

坐標(biāo)(coords)、起點(start)和數(shù)據(jù)(data)對應(yīng)于報告站坐標(biāo)、第一個樣本的時間和標(biāo)準化溫度數(shù)據(jù),然后使用MLM方法來訓(xùn)練語言模型。
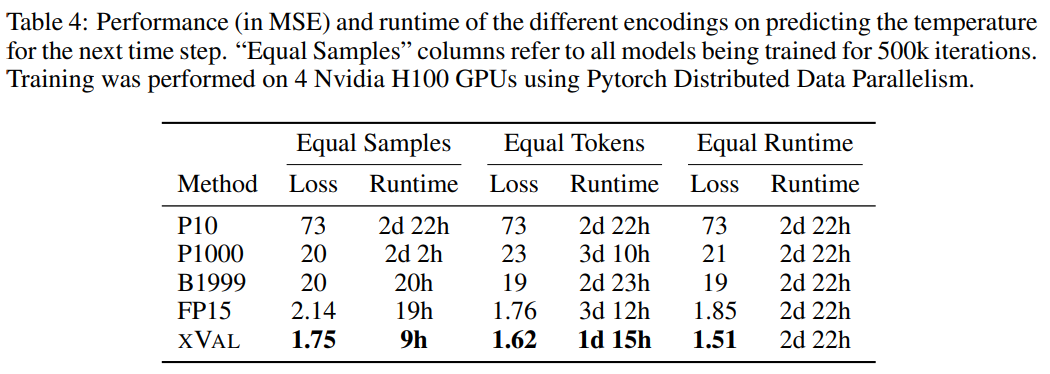
從結(jié)果來看,xVal的性能最好,同時計算所需時間也顯著降低。
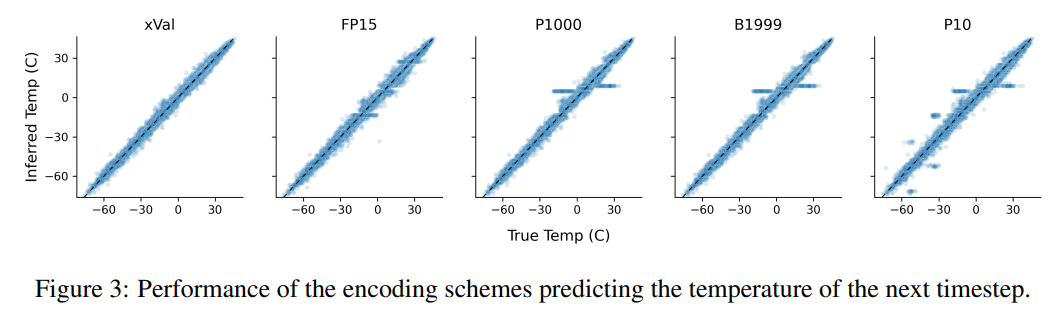
這項任務(wù)也說明了基于文本編碼方案的缺點,模型可以利用數(shù)據(jù)中的虛假相關(guān)性,即P10、P1000和B1999具有預(yù)測歸一化溫度±0.1的趨勢,主要原因是該數(shù)字在數(shù)據(jù)集中出現(xiàn)的頻率最高。
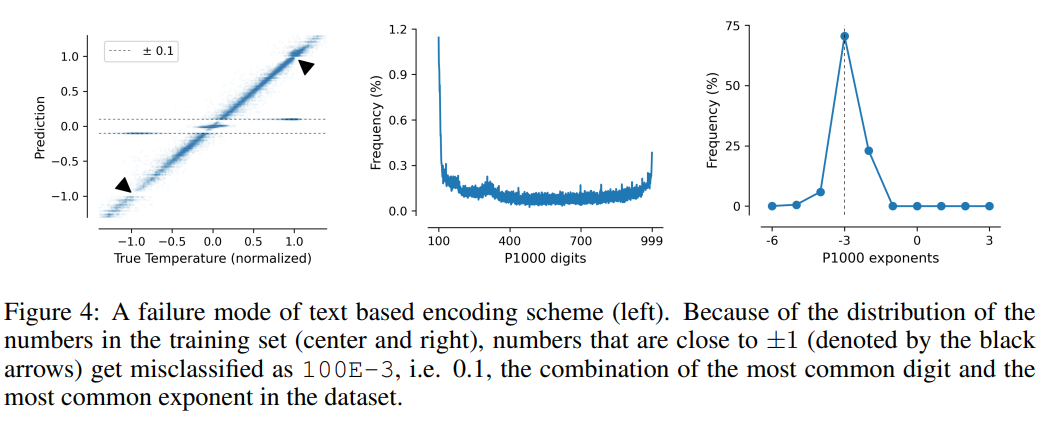
對于P1000和P10方案來說,二者的編碼輸出平均分別約為8000和5000個token(相比之下,F(xiàn)P15和xVal平均約為1800個token),模型的不良性能可能是由于長距離建模的問題。