16個上熱搜的黑科技開源項目
大家好,我是Echa。
計算機視覺,與語音識別、自然語言理解,并稱為人工智能的三大主要技術領域,也是AI技術落地產業化最廣泛的領域。
 百度 Apollo Scape
百度 Apollo Scape
隨著科技的發展,要計算機識別現實世界中的物體需要借助傳感器硬件設備(攝像頭、聲納等),就像人類的眼睛幫助我們看到周圍世界并做出反應一樣。但計算機想要識別傳感器檢測到的數據到底是什么物體,就需要事先使用一定的視覺算法對大量的數據進行訓練,才能夠讓計算機能夠識別傳感器數據中所包含的物體類別并做出響應。
 本田 車內設覺
本田 車內設覺
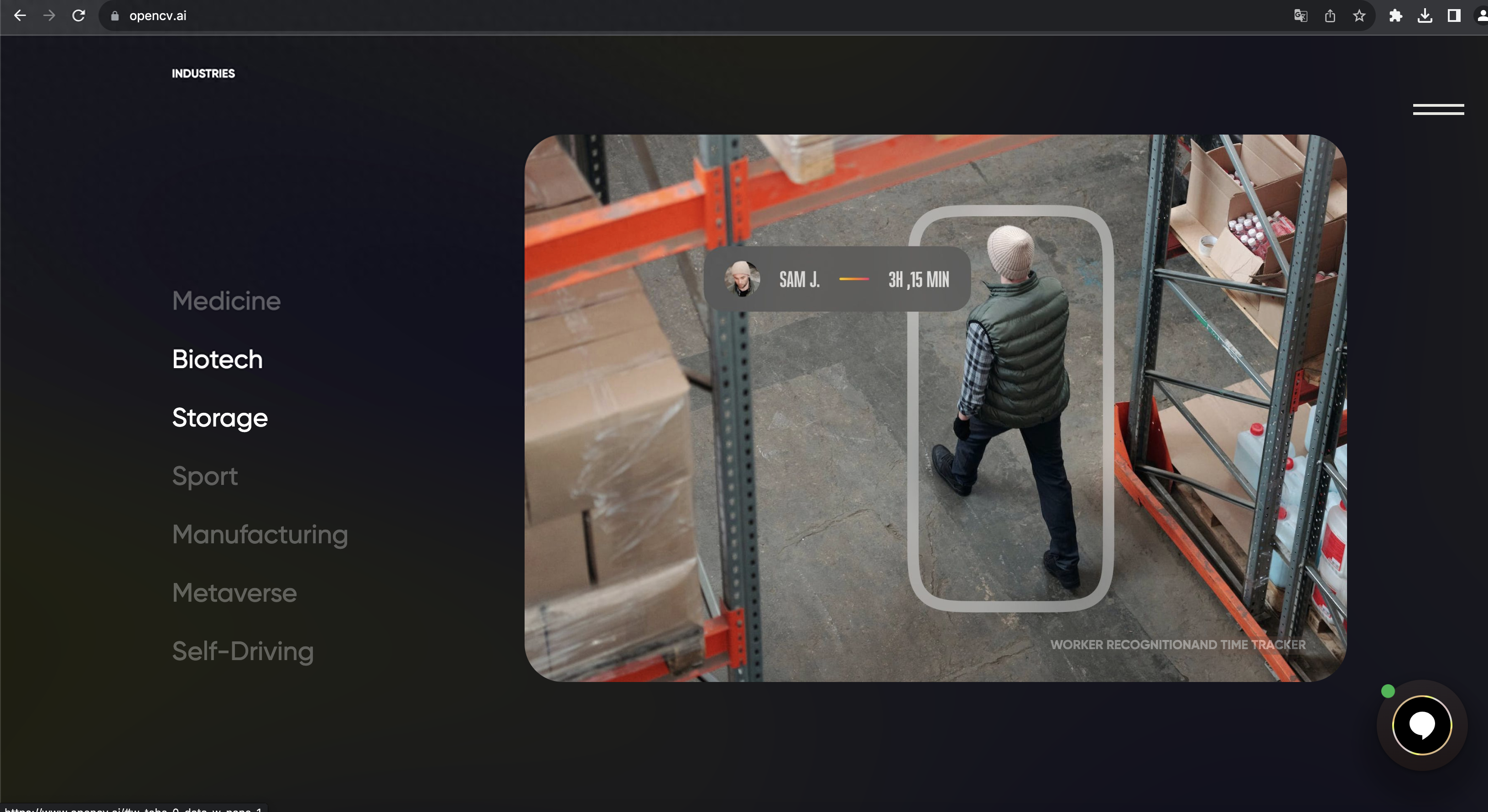
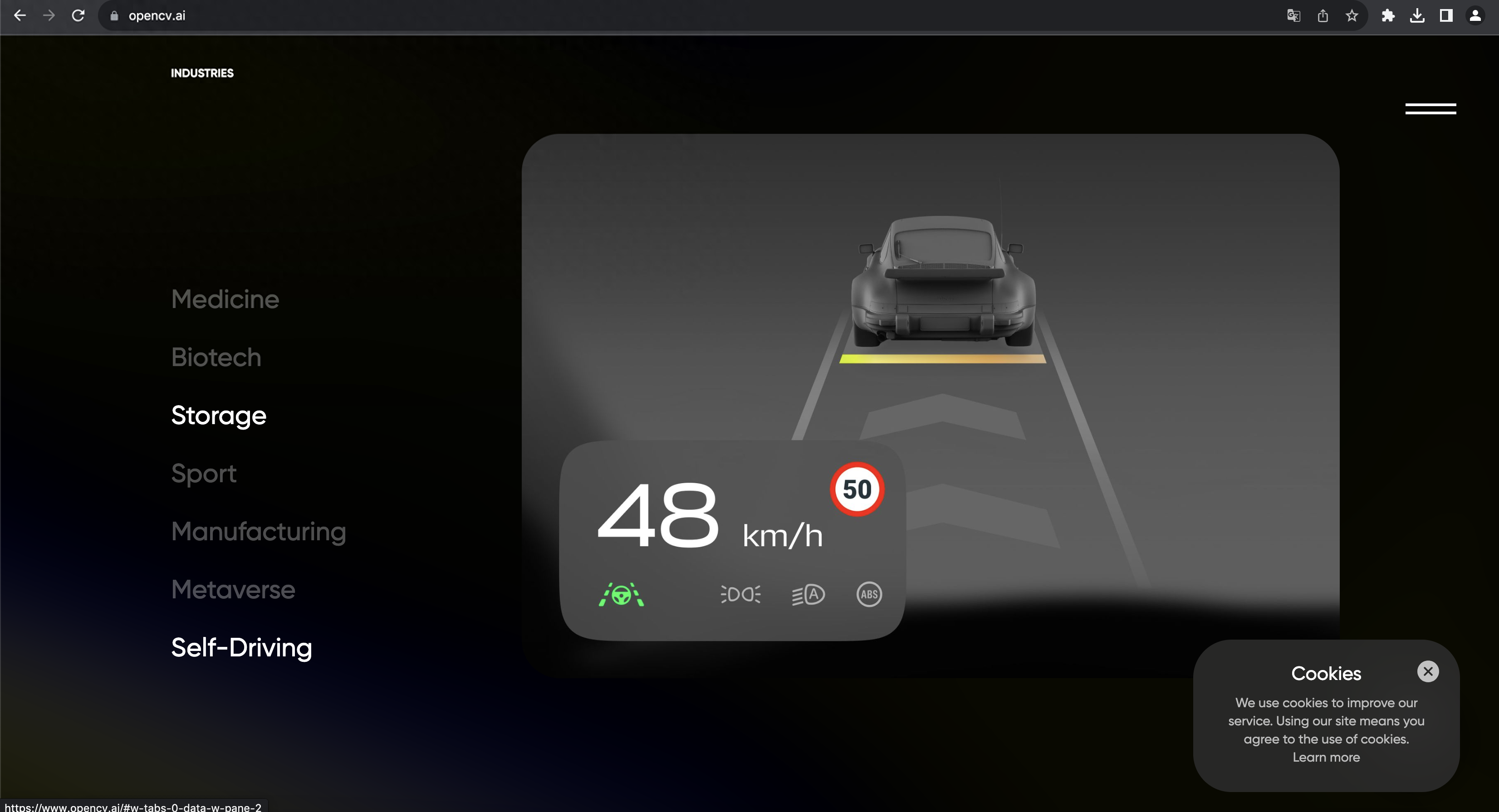
如今,計算機視覺在身份核驗、工業、農業、醫學、交通、海洋等許多行業都有廣泛的用途。因此,對高質量計算機視覺庫的需求也相應增加。計算機視覺庫是一個預先編寫好的算法代碼和一些預訓練好的模型或者數據。目前,在開源領域,計算機視覺庫數量非常多,包括圖像識別庫、人臉識別庫等。
 NEXET
NEXET
借此機會,小編今天給大家好物分享16個上熱搜的黑科技開源項目,希望對大家所有幫助。你們都了解幾個呢?接下來小編帶著大家一一介紹。
全文大綱
- OpenCV- 迄今為止最古老也是最受歡迎的開源計算機視覺庫。
- TorchVision - 擁有計算機視覺中最常見的圖像轉換功能,還包含計算機視覺神經網絡的數據集和模型架構以及常見數據集。
- YOLO - 是最快的計算機視覺工具之一,由Joseph雷德蒙和Ali Farhadi于2016年開發,專門用于實時圖像對象檢測
- MMCV- 是一個基于PyTorch的圖像/視頻處理和轉換器。
- Scikit-Image - 公認的最方便的Python視覺庫,它是Scikit-Learn的一個擴展庫。
- Pillow (PIL Fork) - 是一個Python編寫的圖像處理庫。
- TensorFlow - 是由GoogleBrain團隊開發并于2015年11月發布的AI框架,旨在促進構建AI模型的過程。
- MATLAB - 是Matrix Laboratory的縮寫,但它是一個付費編程平臺,適合用于如機器學習、深度學習、圖像處理、視頻信號處理等方面的應用。
- Keras - 它允許快速構建神經網絡模型,是一個模塊化的AI工具箱,計算機視覺工程師可以利用它來快速組裝應用、訓練模型。
- NVIDIA CUDA-X - 是一個GPU加速庫和工具的集合,可以開始使用新的應用程序或GPA加速。它包含數學庫、并行算法庫、圖像和視頻庫、通信庫和深度學習庫。
- NVIDIA Performance Primitives - CUDA(Compute Unified Device Architecture的縮寫)是NVIDIA開發的并行計算平臺和應用程序編程接口(API)模型。
- PyTorch - 是一個Python的開源機器學習框架,主要由Facebook的AI研究小組開發。
- OpenVINO- 它是一套非常全面的計算機視覺工具。
- Caffe - 一個易于使用的開源深度學習和計算機視覺框架,由加州大學伯克利分校開發。
- SimpleCV - 是一個開源免費的機器視覺框架。
- Detectron2 - 是由Facebook AI Research(FAIR)開發的基于PyTorch的模對象檢測庫。
OpenCV- 迄今為止最古老也是最受歡迎的開源計算機視覺庫。
Github:https://github.com/opencv/opencv
 OpenCV 官網
OpenCV 官網
OpenCV是迄今為止最古老也是最受歡迎的開源計算機視覺庫,旨在為計算機視覺應用提供通用底層算法。
支持跨平臺應用,支持Windows,Linux,Android和macOS。支持各種主流的開發語言,例如:Python,Java,C++等。OpenCV有一個Python Wrapper,支持GPU的CUDA模型。包含一些可以轉換為TensorFlow模型的模型。最初由Intel開發,現在可以在開源BSD許可證下免費使用。

OpenCV的主要功能包括:
- 2D和3D圖像工具包
- 人臉識別
- 手勢識別
- 運動檢測
- 人機交互
- 對象檢測
- 圖像分割和對象識別
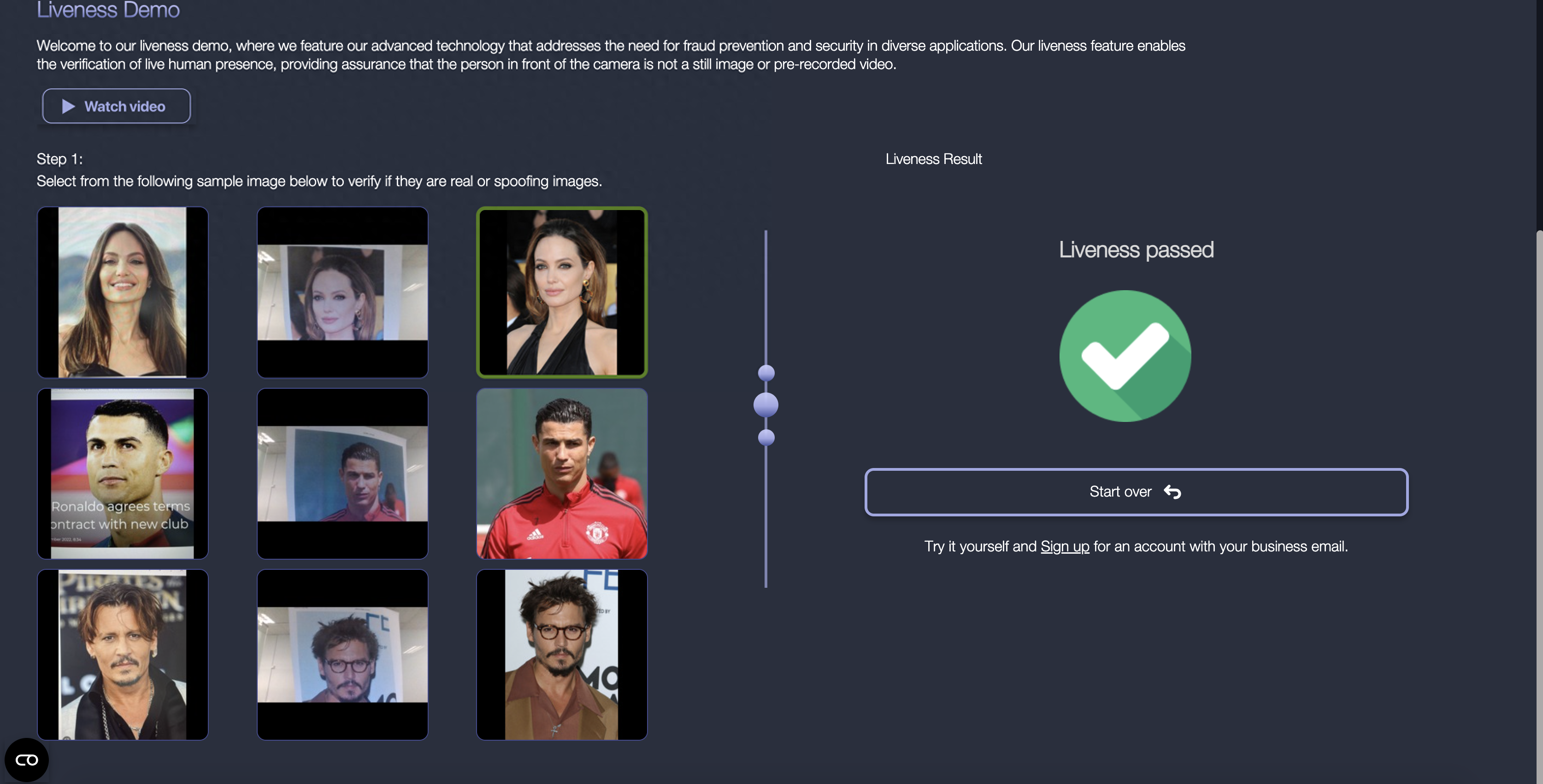 OpenCV Demo
OpenCV Demo
Github:https://github.com/pytorch/pytorch
 PyTorch 官網
PyTorch 官網
TorchVision是PyTorch庫的一個擴展庫,TorchVision擁有計算機視覺中最常見的圖像轉換功能,還包含計算機視覺神經網絡的數據集和模型架構以及常見數據集。
TorchVision旨在為方便使用PyTorch模型進行計算機視覺圖像轉換,而無需將圖像轉換為NumPy數組。TorchVision可以用于Python和C++語言開發環境。可以通過pip install將TorchVision與PyTorch庫一起搭配使用。
以下是預訓練分割模型的使用例子。
import torchvision
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# set it to evaluation mode, as the model behaves differently
# during training and during evaluation
model.eval()
image = PIL.Image.open('/path/to/an/image.jpg')
image_tensor = torchvision.transforms.functional.to_tensor(image)
# pass a list of (potentially different sized) tensors
# to the model, in 0-1 range. The model will take care of
# batching them together and normalizing
output = model([image_tensor])
# output is a list of dict, containing the postprocessed predictions
Github:https://github.com/ultralytics/ultralytics
 YOLO 官網
YOLO 官網
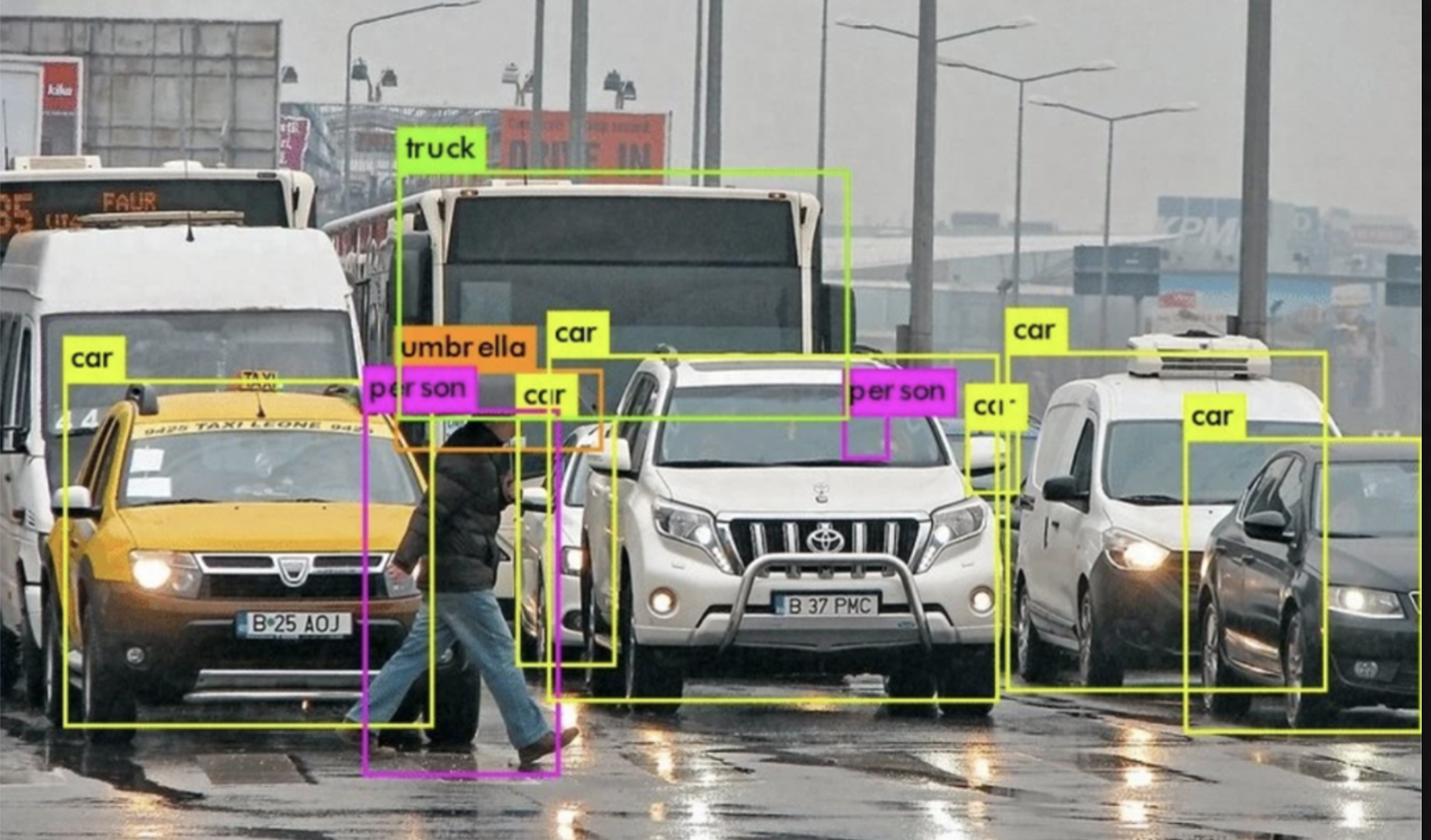
YOLO是最快的計算機視覺工具之一,由Joseph雷德蒙和Ali Farhadi于2016年開發,專門用于實時圖像對象檢測。YOLO使用將神經網絡,將圖像劃分為網格,然后同時預測每個網格,以提高識別效率。
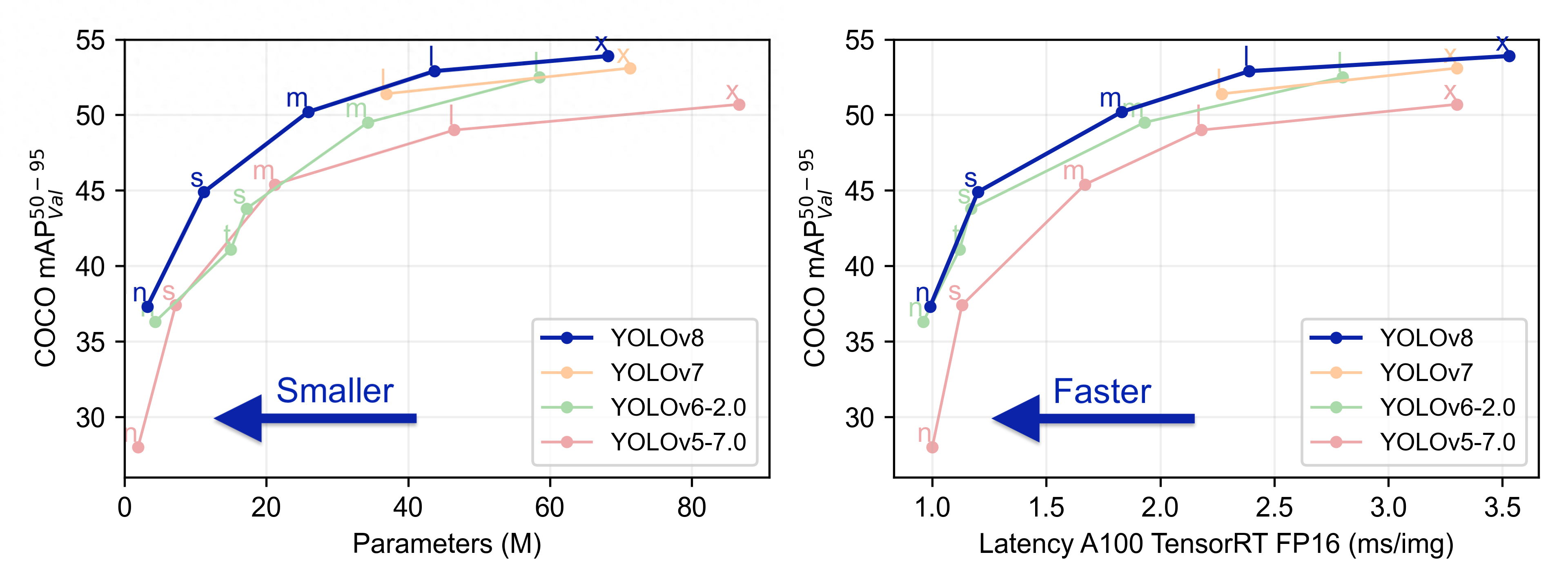
目前YOLO已經發布V8。YOLOv8 是一款前沿、最先進(SOTA)的模型,基于先前 YOLO 版本的成功并引入了新的功能和改進,進一步提升了性能和靈活性。YOLOv8 的快速、準確且易于使用,使其成為各種對象檢測與跟蹤、實例分割、圖像分類和姿態估計任務的絕佳選擇。
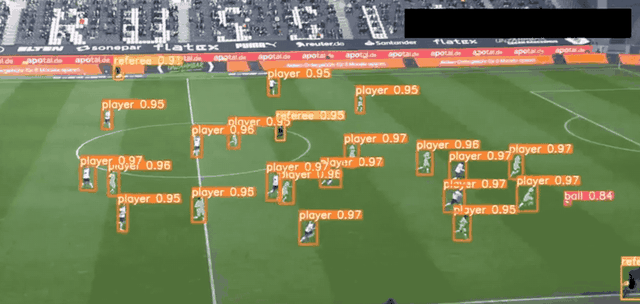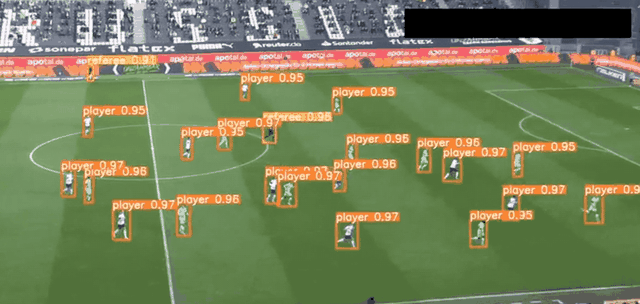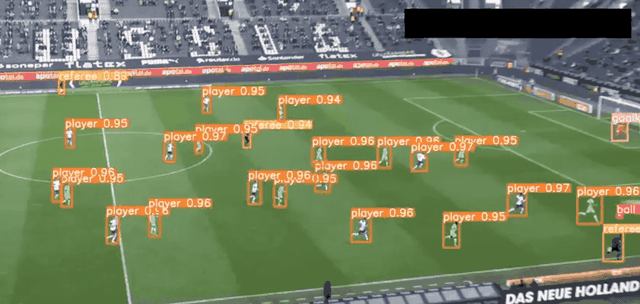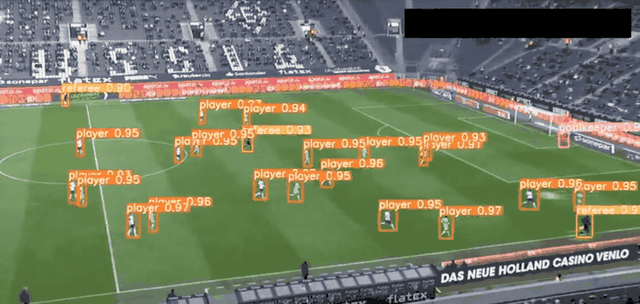 YOLO 應用場景
YOLO 應用場景
Github:https://github.com/open-mmlab/mmcv
MMCV 中文版官方
OpenMMLab 團隊于 2022 年 9 月 1 日在世界人工智能大會發布了新一代訓練引擎 MMEngine,它是一個用于訓練深度學習模型的基礎庫。相比于 MMCV,它提供了更高級且通用的訓練器、接口更加統一的開放架構以及可定制化程度更高的訓練流程。
MMCV v2.0.0 正式版本于 2023 年 4 月 6 日發布。在 2.x 版本中,它刪除了和訓練流程相關的組件,并新增了數據變換模塊。另外,從 2.x 版本開始,重命名包名 mmcv 為 mmcv-lite 以及 mmcv-full 為 mmcv。
MMCV是一個基于PyTorch的圖像/視頻處理和轉換器。它支持Linux、Windows和macOS等系統,是計算機視覺研究人員最常用的包之一。支持Python和C++開發語音。

MMCV 是一個面向計算機視覺的基礎庫,它提供了以下功能:
- 圖像和視頻處理
- 圖像和標注結果可視化
- 圖像變換
- 多種 CNN 網絡結構
- 高質量實現的常見 CUDA 算子
MMCV 支持多種平臺,包括:
- Linux
- Windows
- macOS
Github:https://github.com/scikit-image/scikit-image
 Scikit-Image 官網
Scikit-Image 官網
Scikit-Image是公認的最方便的Python視覺庫,它是Scikit-Learn的一個擴展庫。是監督和無監督機器學習最常用的工具之一。可以用于將NumPy數組作為圖像對象進行處理。
以下是使用Scikit-image進行硬幣識別的例子。
import skimage as ski
image = ski.data.coins()
# ... or any other NumPy array!
edges = ski.filters.sobel(image)
ski.io.imshow(edges)
ski.io.show()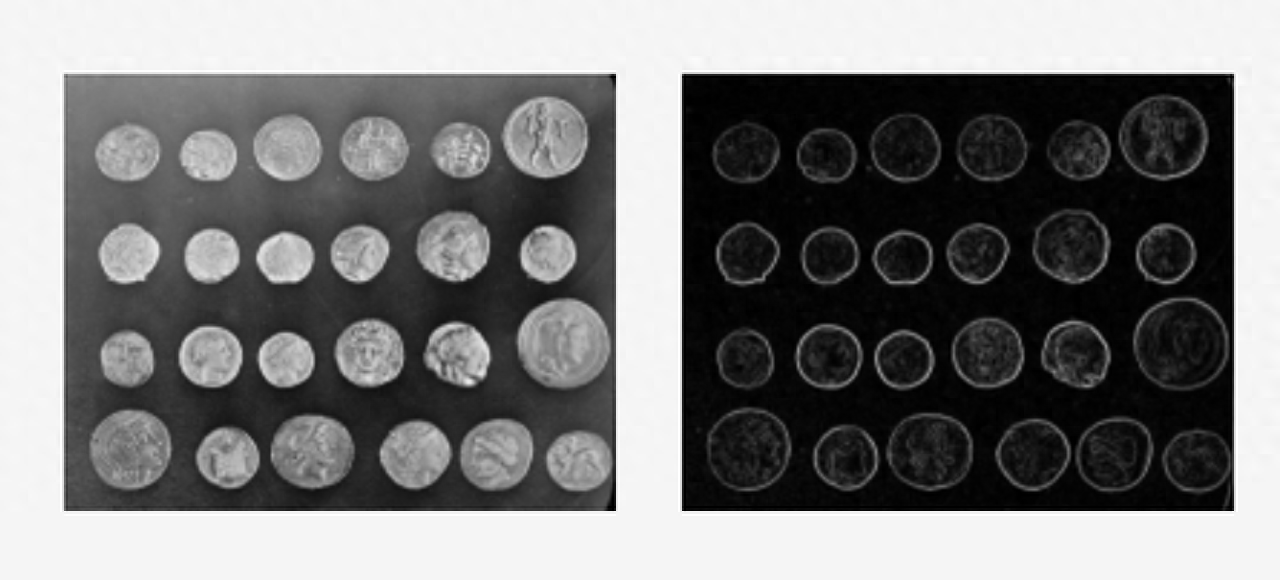
Github:https://github.com/python-pillow/Pillow
 Pillow (PIL Fork) 官網
Pillow (PIL Fork) 官網
Pillow是一個Python編寫的圖像處理庫。它支持Windows、Mac OS X和Linux平臺,可以在C和Python語言中使用Pillow庫。主要用于閱讀和保存不同格式的圖像,Pillow還包括各種基本圖像變換功能,例如:旋轉、合并、縮放等。
Github:https://github.com/tensorflow/tensorflow
 TensorFlow 官網
TensorFlow 官網
TensorFlow是由GoogleBrain團隊開發并于2015年11月發布的AI框架,旨在促進構建AI模型的過程。它有一些擴展解決方案,如針對瀏覽器和Node.js的TensorFlow.js,以及針對終端設備的TensorFlow Lite。另外,TensorFlow還提供了一個更好的框架TensorFlow Hub。這是一個更易于使用的平臺,可以使用TensorFlow Hub實現重復使用BERT和Faster R-CNN訓練模型、查找可隨時部署的模型、托管模型以供他人使用。
TensorFlow允許用戶開發與計算機視覺相關的機器學習模型,例如:人臉識別、圖像分類、目標檢測等。與OpenCV一樣,Tensorflow也支持各種語言,如Python、C、C++、Java或JavaScript。
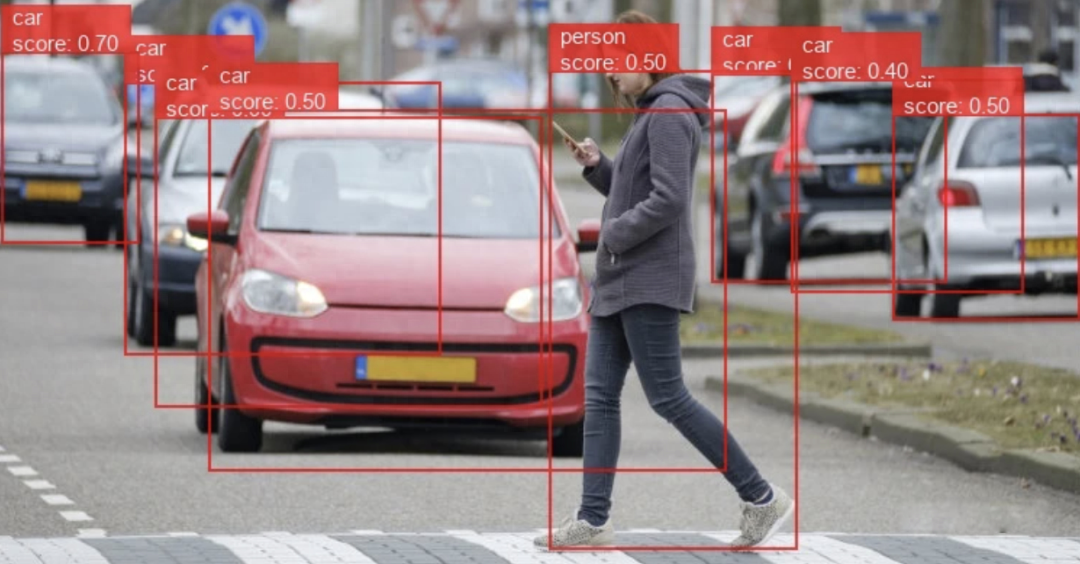
TensorFlow 應用場景
傳送門:https://ww2.mathworks.cn/products/matlab.html
 MATLAB 官網
MATLAB 官網
MATLAB是Matrix Laboratory的縮寫,但它是一個付費編程平臺,適合用于如機器學習、深度學習、圖像處理、視頻信號處理等方面的應用,是一個受到工程師和科學家喜歡的編程平臺。它配備了一個計算機視覺工具箱,包含許多算法能力,如:
- 視頻目標檢測與目標跟蹤
- 物體識別
- 校準攝像機
- 處理三維視覺
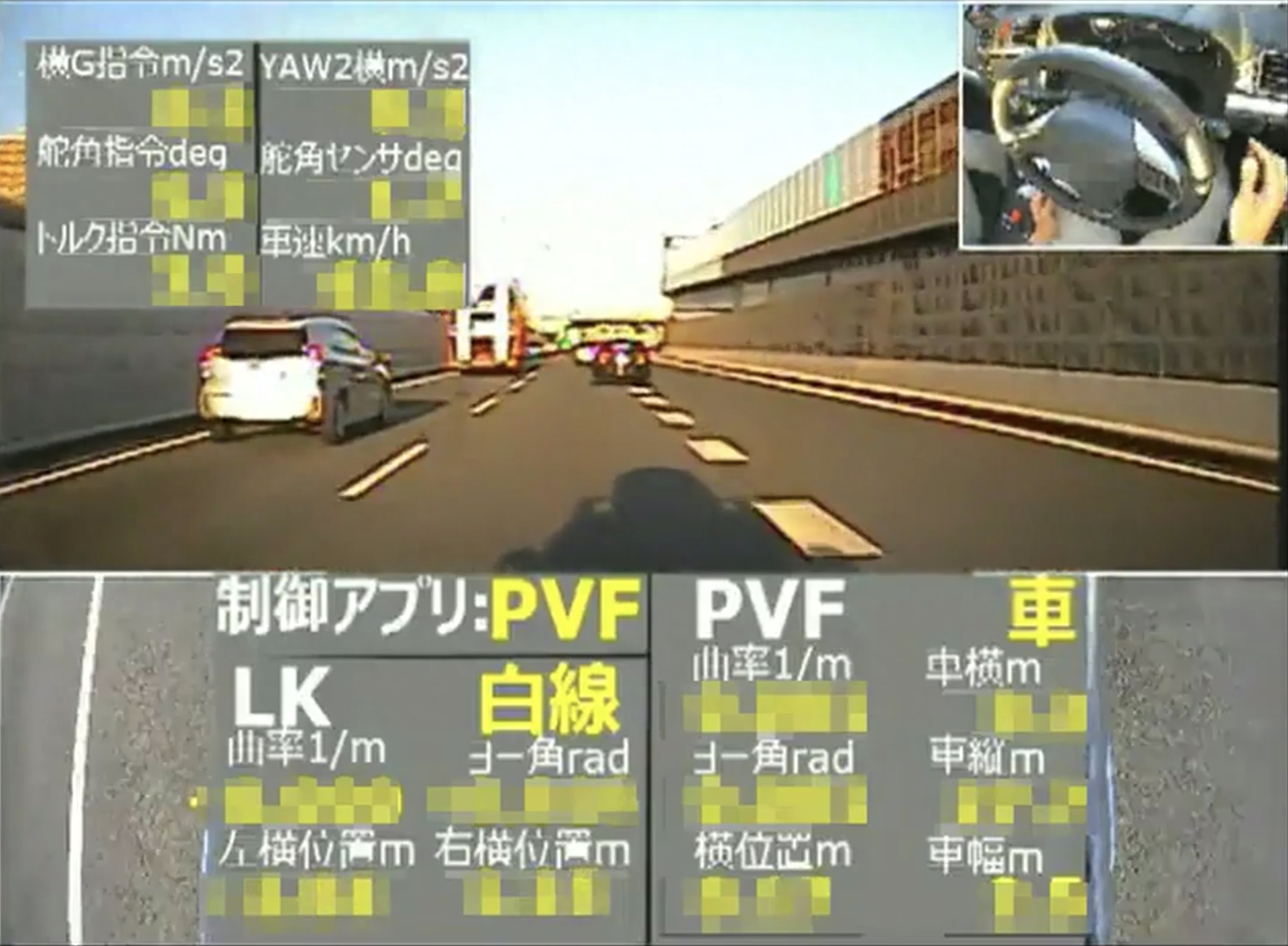
傳送門:https://keras.io/

Keras是一個基于Python的開源軟件庫,對初學者來說特別易用,它允許快速構建神經網絡模型,是一個模塊化的AI工具箱,計算機視覺工程師可以利用它來快速組裝應用、訓練模型。Keras的底層框架使用TensorFlow,并且擁有強大的社區支持,因此用戶眾多。可以使用Keras實現的內容例如:
- 圖像分割和分類
- 手寫識別
- 三維圖像分類
- 語義圖像聚類

傳送門:https://developer.nvidia.com/
CUDA是計算統一設備架構的首字母縮寫,而NVIDIA CUDA-X是CUDA的更新版本。
NVIDIA CUDA-X是一個GPU加速庫和工具的集合,可以開始使用新的應用程序或GPA加速。它包含數學庫、并行算法庫、圖像和視頻庫、通信庫和深度學習庫,可用于各種任務,例如:人臉識別、圖像處理、3D圖形渲染等。它兼容大多數操作系統,并且支持許多主流AI編程語言,如:C、C++、Python、Fortran、MATLAB等。
傳送門:https://developer.nvidia.com/npp
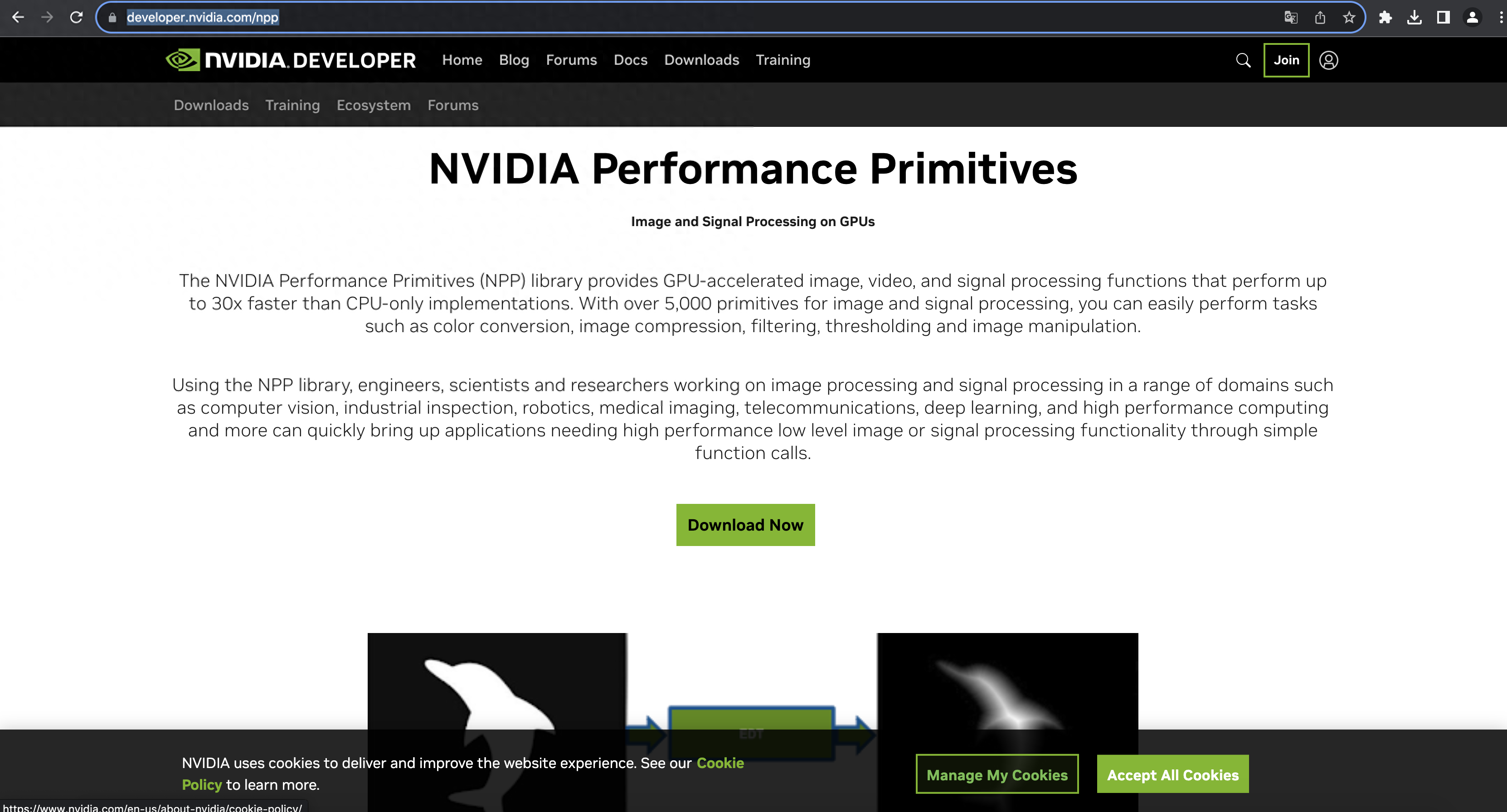
CUDA(Compute Unified Device Architecture的縮寫)是NVIDIA開發的并行計算平臺和應用程序編程接口(API)模型。它允許開發人員使用GPU(圖形處理單元)的強大功能來加快處理密集型應用程序的速度。
該工具包包含NVIDIA Performance Primitives(NPP)庫,可為多個領域(包括計算機視覺)提供GPU加速的圖像、視頻處理和信號處理功能。此外,CUDA架構可用于各種開發任務,例如:人臉識別、圖像處理、3D圖形渲染等。它支持各種編程語言,包括C、C++、Python、Fortran或MATLAB,并且還與大多數操作系統兼容。
Github:https://github.com/pytorch/pytorch
 PyTorch 官網
PyTorch 官網
PyTorch是一個Python的開源機器學習框架,主要由Facebook的AI研究小組開發。在構建復雜體系結構時具有很大的靈活性。可以用于機器視覺方面開發圖像評估模型、圖像分割、圖像分類等。
PyTorch是一個基于Torch的使用Python編程語言的開源機器學習框架。Torch 是一個開源的用Lua腳本語言編寫的機器學習庫,用于創建深度神經網絡。
PyTorch 支持多種不同的數學運算,簡化了人工神經網絡模型的創建。PyTorch 主要應用于數據科學家用于研究和人工智能應用,如計算機視覺和自然語言處理等應用。PyTorch 遵循 modified BSD 許可協議。
2016年,PyTorch 由 Meta AI Research 首次發布,現在已成為Linux基金會的一部分。許多深度學習軟件都是在PyTorch基礎之上構建的,包括Tesla 的 Autopilot、Uber 的 Pyro、HuggingFace 的 Transformers、PyTorch Lightning、和 Catalyst。
PyTorch提供了兩個高級特性:一是類似于NumPy的張量計算,可通過GPU實現強大的加速;二是基于帶自動微分系統的深度神經網絡。支持ONNX與其他程序庫交換模型。
Github:https://github.com/openvinotoolkit/openvino
OpenVINO 官網
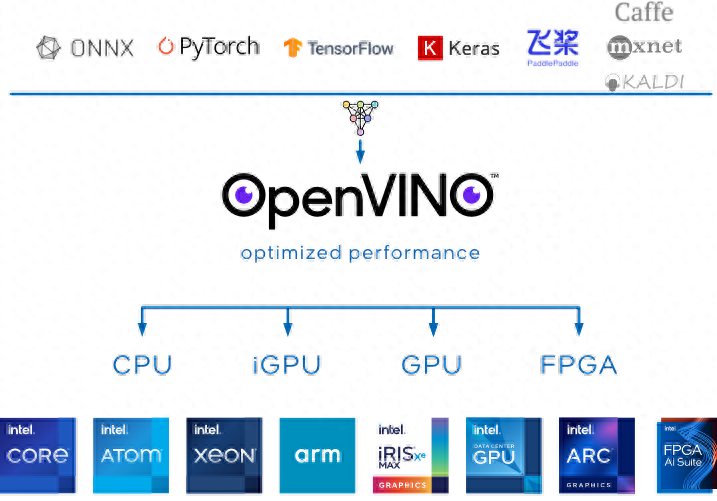
OpenVINO是Open Visual Inference and Neural Network Optimization的縮寫。它是一套非常全面的計算機視覺工具。它由英特爾開發,是一個可以免費使用的跨平臺框架,具有多種視覺處理能力,包括:
- 對象檢測
- 人臉識別
- 圖像彩色化
- 運動識別
Github:https://github.com/BVLC/caffe
Caffe 官網
CAFFE是Convolutional Architecture for Fast Feature Embedding的縮寫。是一個易于使用的開源深度學習和計算機視覺框架,由加州大學伯克利分校開發。
它使用C++編寫,支持多種開發語言,支持多種用于實現圖像分類和圖像分割的深度學習架構。Caffe可以用于視覺、語音和多媒體領域的應用,支持圖像分割、分類等模型開發。
 SimpleCV 官網
SimpleCV 官網
SimpleCV是一個開源免費的機器視覺框架。通這個框架,可以輕松訪問OpenCV等幾個高性能的計算機視覺庫,而無需深入了解位深度、顏色空間、緩沖區管理或文件格式等復雜概念。
Github:https://github.com/facebookresearch/detectron2
 Detectron2 官網
Detectron2 官網
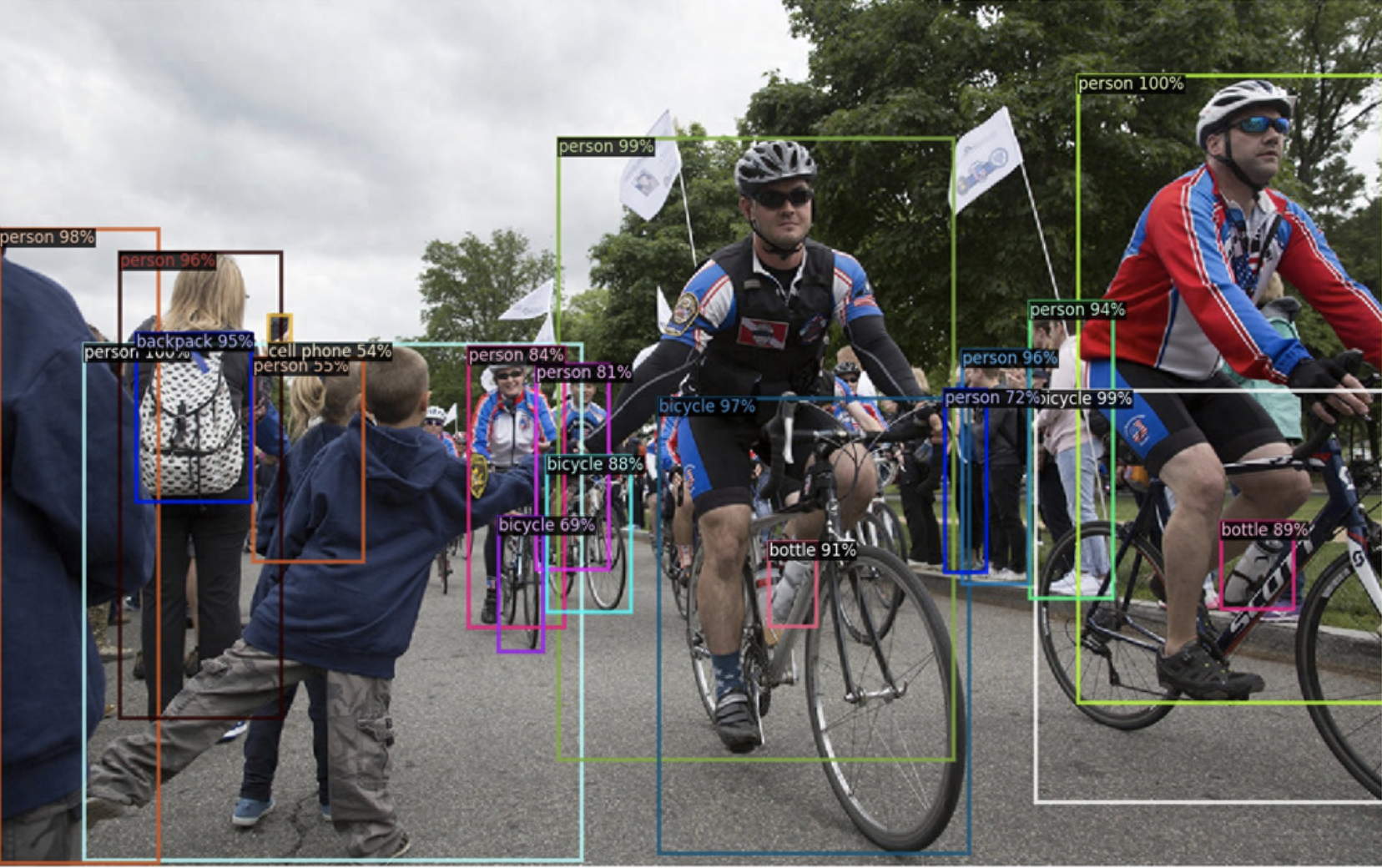
Detecrton 2是由Facebook AI Research(FAIR)開發的基于PyTorch的模對象檢測庫。
Detectron 2是Detection的升級版;包括:Faster R-CNN、Mask R-CNN、RetinaNet、DensePose、Cascade R-CNN、Panoptic FPN和TensorMask等模型。Detecrton 2的功能包括:密集位姿預測、全景圖像分割、聯合分割、對象檢測等。
 Detectron2 應用場景
Detectron2 應用場景
最后
一臺電腦,一個鍵盤,盡情揮灑智慧的人生;