













音樂驅動數字人技術詳解

一、音樂驅動體系 Music XR Maker
Music XR Maker 源于天琴實驗室,天琴實驗室是騰訊音樂首個音視頻實驗室,致力于通過 AI 科技提升音娛視聽體驗,也是騰訊音樂的首個音視頻技術研發中心。天琴實驗室在視頻、視覺方面主要做的事情包括兩方面,一方面是 Music XR Maker 以及圖像渲染技術,另一方面是視頻相關,比如視頻理解、音樂視頻化、視頻質量提升等。
1、音樂驅動在數字人技術棧中的定位
在數字人技術棧中,音樂驅動的定位可分為三個部分:
形象構建:在形象構建過程中,涉及到的技術包括模型制作、拍照捏臉、拍攝建模、服飾生成等。
人物驅動:人物驅動分成兩個體系,第一個是基于中之人,背后有真實人物在驅動;第二個是 AI 驅動。在音頻和視覺上,兩個體系都有對應的實現:在音頻聲音這塊,中之人直接用中之人的聲音,AI 驅動在說話方面有 TTS 技術,歌曲歌聲方面對應有歌聲合成技術。在面捕這塊,可以實時把中之人的面部表情捕捉到位,AI 生成則有說話口型生成、歌唱口型生成、說話表情生成、歌唱表情生成等。在動作和手勢方面,也有相應的動作捕捉、手勢捕捉,在音樂領域也有對應的舞蹈動作生成和樂器手勢生成。
可視化渲染:當成功將建立的模型驅動起來后,需要讓普通用戶看得到模型,這就涉及到可視化渲染。比如虛擬偶像視頻分發到各種視頻平臺、虛擬主播開虛擬直播、互動娛樂多人互動等。

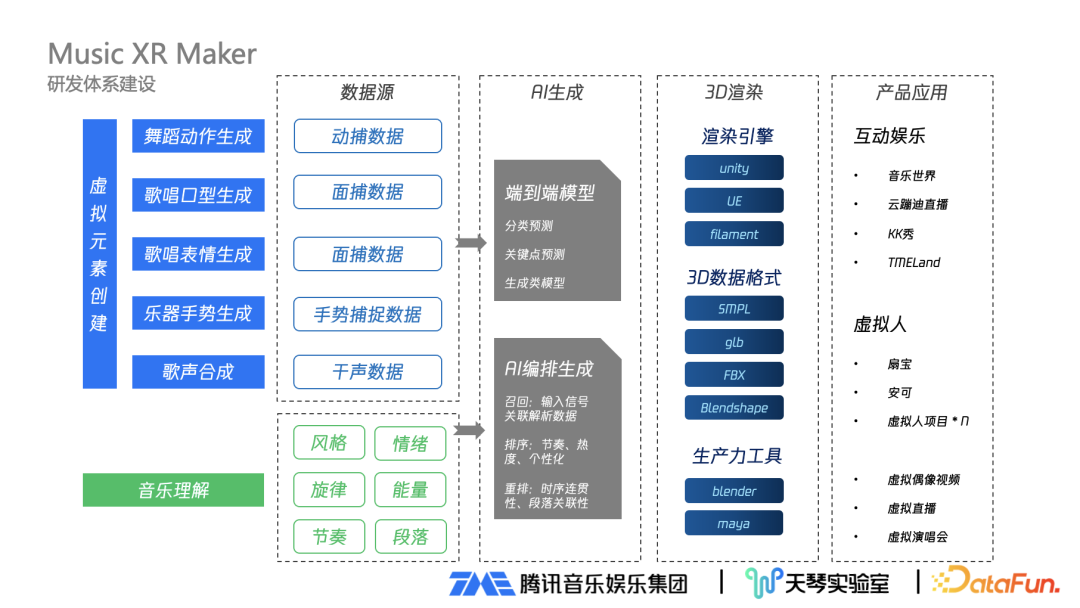
2、Music XR Maker 音樂驅動研發體系建設
Music XR Maker 著重音樂,可以理解為基于音樂內容做虛擬元素的創建,實質是屬于 AI 驅動當中的音樂驅動,可以驅動的項目包括歌聲合成、歌唱口型生成、舞蹈動作生成、樂器手勢生成、歌唱表情生成等,還包括后續將會逐步迭代加入的場景燈效舞美。Music XR Maker 音樂驅動研發體系建設包括:
數據源:建設 Music XR Maker 體系在數據層面分成兩個部分:一是建模動作口型生成必須要有數據來源,目前大部分來源是動捕或面捕數據,還有手勢捕捉數據等;二是既然把數據跟音樂關聯,就要有非常強的音樂理解能力,包括音樂風格、情緒、音樂旋律、能量、歌曲的節奏、段落等。
AI 生成:有了基礎數據后,就通過核心 AI 生成的算法把兩方面數據進行關聯。算法有兩種類型:一類是端到端模型,包括分類預測模型、關聯點預測、生成類模型等;另一類是 AI 編排生成算法,相對復雜且涉及多種步驟,還會使用到類似搜索或推薦等做法,可以分成召回、排序、重排三個階段:在召回階段,對輸入信號進行關聯解析數據;在排序階段,根據歌曲節奏、歌曲熱度、個性化等排序;在重排階段,進行時序連貫性、段落關聯性等調整。
3D 渲染:通過 AI 生成得到驅動數據后,要打通完整商業化鏈條還需要進行 3D 渲染,這是必不可少的一環。首先需要渲染引擎,像常用的 Unity 、UE,還需要專業的 3D 數據格式,像 SMPL、GLB、FBX 等;同時也需要生產力工具,像 Blender、Maya 等。
產品應用:對企業來說,最后一環就是真正落地應用到具體產品。落地應用分兩種類型:一種是有用戶參與的互動娛樂應用,以 QQ 音樂的音樂世界、音樂直播的云蹦迪直播、全民 K 歌的 KK 秀、TMEland 等為代表;另一種是在娛樂公司比較常見的虛擬人代表,比如已公開的扇寶、安可、持續在研發的虛擬人項目,曝光的場景包括虛擬偶像視頻、虛擬直播、重要節點開虛擬演唱會等,都是虛擬偶像展現的地方。
二、音樂生成數字人舞蹈
1、虛擬人舞蹈的產生方式
數字人舞蹈的生成方式大致分成三種:
動捕棚:采用目前比較新的多目動捕設備、慣性捕捉,得到的效果是真正影視級效果,也是目前能接觸到的最佳效果。但存在價格昂貴,人力、設備成本高等問題。應用場景來說,可用于精品視頻輸出。
視頻復刻:屬于單目動捕,用于普通的低精度場景效果還不錯,但運用到非常激烈的快節奏舞蹈,特別是運用到高精度模型,效果上存在細節丟失。這種方式人力成本相對較低,所以在低精度模型場景上應用較多。視頻復刻有個非常明顯的優勢是其他方式達不到的,它可以很好抓住熱點。現在的短視頻類平臺每隔一段時間都會出一些熱點舞蹈,通過這種方式可以快速的把熱門舞蹈實時復刻出來。
基于音樂生成:屬于純算法生成,效果依賴數據質量和算法自身好壞。存在的問題是數據獲取困難,優勢在于可以批量生產場景。在批量場景下,可以和精品視頻進行互補,在日常視頻輸出可以用到這種基于音樂生成舞蹈的方案。

2、音樂生成數字人舞蹈的業內方案
業內有很多音樂生成數字人舞蹈的方案,大致有如下幾種:
基于生成的方案:非常具有想象力的方案,但商用可能存在不可控情況。
基于 codebook:對比于生成的方案進行改進,加入了 codebook 等方式,對生成的舞蹈規律有一定約束,是非常不錯的方案。
基于舞蹈編排:實驗的難度和實現的可行性更高一些。

面向商用的舞蹈生成如何做,有三點因素需要考慮:一是舞蹈動作本身是美觀的動作;二是舞蹈動作和音樂的節奏、韻律要和諧一致;三是音樂和舞蹈的風格也要一致。所以在 AI 編舞時重點會關注音樂特征,包括音樂本身的特性、音樂節奏等,對舞蹈也會做對應匹配,包括舞蹈屬性、風格、情緒、節奏快慢等。綜合來看,商用舞蹈生成是在有原始音頻文件后,通過一些方法提取音頻特征,接著通過特征回歸到舞蹈動作,最后將這些動作合理的拼接起來。

3、TME 天琴方案
下方是 TME 天琴方案的生成算法截圖。當拿到一段音樂后,切成一幀一幀的小片段,接著對每一幀提取對應的音樂屬性特征,包括旋律、節奏等最能代表音樂和舞蹈的特征,然后去匹配最合適的舞蹈片段,同時基于音樂節奏、風格類型,對召回的片段進行重新排序,過濾掉不太適合的片段,最終把對應的片段進行拼接,就形成一段完整舞蹈。這里還涉及一個問題,舞蹈動作可能前后段連接有問題,可通過平滑算法進行過渡來解決。
這個方案實際應用起來比較簡單,而且可以直接使用。但這個方案存在一定問題,因為想象力不夠,生成的方案多樣性略差。

另外一套方案是基于生成的方案。輸入一段音頻信號,對應的原始樣本音頻會關聯到對應的舞蹈,輸入模型中經過一個過程,還原回最初的舞蹈動作。在這個過程中,要把音頻信號特征和舞蹈信號特征盡量拉齊,盡量表達更廣泛的含義。
當音樂生成數字人舞蹈完成后,可以進行主觀評測。針對同樣一首歌,把生成的舞蹈和手 K 的舞蹈動作發給普通用戶進行對比,選取兩種方式對比:第一個方式是直接對比生成結果和手 K 結果,讓用戶選擇哪種更好;第二個方式是把生成結果和手 K 結果分別進行打分。經過評測發現,兩種方式的結論類似,生成結果已經接近手 K 的效果,總體效果不錯。
4、數字人舞蹈的商用路徑
在數字人舞蹈的商用路徑方面理解如下:
首先,通過動捕棚拍攝、CP 手 K 效果最好,會應用到虛擬偶像、虛擬主播的精品 MV、形象宣傳片,同時這類高質量舞蹈數據可以保留下來。
第二,單目的視頻復刻主要用到虛擬主播、虛擬偶像、用戶互動娛樂場景的爆款舞蹈生成。生成數據可以經過人工篩選,把中質量舞蹈數據保留下來。
最后,把之前保留下來的高質量舞蹈數據和中質量舞蹈數據,作為 AI 舞蹈生成模型的數據來源,生成的舞蹈數據就作為量產數據,用在虛擬偶像、虛擬主播、用戶互娛場景,批量生產更多的舞蹈動作。

三 、歌聲驅動數字人口型
1、歌聲驅動數字人口型方案
歌聲驅動數字人口型有兩種實現方案:
① 專業面捕方案:有專業設備、配套軟件,優點是效果最佳,無限表情基。廣泛應用于超寫實虛擬人場景。
② 普通光學攝像頭方案:通過普通手機攝像頭可以實現,一般場景下效果完全可接受,標準 52 BS。適用于一般的虛擬人場景。

2、口型驅動數據集構建
在口型驅動數據數據建設上,把全民 K 歌軟件的用戶 K 歌視頻畫面保留下來,同時錄入用戶唱歌干聲數據。通過前面提到的單目動捕方案,把唱歌畫面進行口型識別,拿到口型 BS 數據,再加上保留下來的用戶唱歌干聲數據,同時輸入到歌聲口型驅動模型。

歌唱驅動和說話驅動有差別:說話時嘴巴動的頻率比較快,但是唱歌時因為要一口氣唱下去,嘴巴表現更有連貫性;同時說話時嘴巴動的幅度沒有歌唱時幅度大,這也是專門做歌唱口型驅動模型的原因。
3、TME 口型驅動模型
TME 口型驅動模型的方案同時用到兩部分數據:一個是用戶輸入的干聲數據,一個是歌詞文件(歌詞文件經過前處理,對歌詞文件和音頻做對齊,拿到每一個字精準的時間戳)。對輸入音頻和歌詞做 Encoder 處理后,進行融合。把融合結果輸入到另一個面部匹配預測模塊,該模塊會將當前幀的歌詞、音頻信息同之前全部幀的信息放在一起,做一個 Decoder 處理。最終預測到整首歌匹配變化后再轉換為所需要的模型參數。
4、實時性解決方案
前面是異步生成視頻的場景,實時性如何解決有如下考慮:先離線生成預設 BlendShape,輸入測試文件及干聲數據,干聲來源于兩個部分:一是之前用戶唱的優秀作品干生;二是歌曲原唱,通過技術提取原唱的干聲,然后把各式文件和綜合干聲,通過前面的口型驅動模型,得到預設 BlendShape。等到真正實施時,用戶實時干聲經過音頻映射模型,得到實時音頻分析結果,和前面的預設 BlendShape 進行融合,最后得到實時 BlendShape。這樣就解決了實時性問題,同時兼備口型生成的效果。

實時性解決方案的相關技術已經上線應用,在全民 K 歌 8.0 的 QQ 秀可以體驗到:一個場景是用戶入唱時,會有 K 歌秀界面,一邊唱一邊可以看到 QQ 秀虛擬人的動作、口型等;另一個是在歌房場景也有類似體驗。
四、歌聲驅動數字人歌唱表情
當做好數字人歌唱口型后,發現人顯得比較呆。分析專業歌手演唱表演,發現唱歌時要表達歌唱情感,除了口型之外,歌唱時的面部表情、手勢、動作都要同時具備,三者合一的完整表現才能突出演唱者當時的強烈情感。
1、歌唱表情數據的采集
歌聲驅動數字人歌唱表情的實現需要進行數據采集。數據采集時先找到帶表情的演唱視頻樣本,通過面捕拿到面部表情,通過動捕拿到動作,通過手捕拿到手勢,然后把表情、動作和手勢合一,融入歌唱表情段,經過人工表情打標后放入歌唱表情庫。

2、歌唱表情的合理驅動
采集到歌唱表情之后,需要合理的驅動起來。經過歌詞文本分析拿到歌唱時歌詞的表情信息,確定整個歌唱表演的表情基調。此時可以從龐大的各種類型表情庫里,挑選出合適的表情,適合于在歌曲或者歌曲的某一個片段安插表情。
五、總結與展望
這兩年上線了很多與虛擬人或元宇宙相關的平臺和產品,娛樂公司、明星、大型商業公司、海量主播、普通用戶等很多都有自身的虛擬形象,虛擬形象將變得越來越普遍。
中之人面臨越來越多的問題,比如成本問題、管理問題、虛擬形象的靈魂歸屬于虛擬偶像本身還是中之人。
AI 驅動技術面臨快速升級,包括形象創建技術、視覺驅動技術、音頻歌聲合成技術等。TME 以音樂為核心進行技術建設,包括音樂驅動數字人舞蹈、數字人歌唱口型、數字人歌唱表情等,未來還有其他方面。
總體來說,數字人的未來在于技術。
六、問答環節
Q1:動捕數據或公開數據集重定向到模型驅動有問題時如何處理?
A1:確實會存在重定向的問題。主要是先重定向到一些標準模型,然后再通過人工發現有問題的數據,對有問題的數據進行分類:如通過手動可以小范圍解決的,就進行修復;如解決不了,就直接把數據拋棄掉。
Q2:音樂生成數字人舞蹈的客觀評測方法?
A2:因為音樂生成數字人舞蹈是偏向主觀的一個領域,生成的東西不可能跟原始的一樣,如果跟原始一樣,那就沒有什么意義了。所以音樂生成數字人舞蹈更多的是一些主觀評測。
Q3:現在主要研究的是卡通類型的數字人嗎?
A3:現在主要研究的是在卡通類型的數字人,目前沒有太涉及寫實虛擬人方面。
Q4:拼接的單元是小節嗎?
A4:拼接的單元不是小節。這里涉及到一些細節,比如根據音樂的節奏進行切分,并不是簡單的切幾秒鐘舞蹈片段,需要把舞蹈片段切的更便于后續的拼接。



















