













一個關于 i++ 和 ++i 的面試題打趴了所有人

大家好,我是哪吒。
公司最近在招聘實習生,作為面試官之一的我,問了一道不起眼的經典面試題。
一、i++和++i有啥區別?
大部分的面試者會這樣答:
- i++ 返回原來的值,++i 返回加1后的值。
- i++是先賦值,然后再自增;++i是先自增,后賦值。
下面這個才是主菜。
二、高并發場景下i++會遇到哪些問題?
大部分面試者心里肯定在想,這會有啥問題,不就是一個普通的操作嘛!
先從i++操作說起,一個命令可以拆分成三部分:
- 取值
- ++操作
- 賦值
我去,這不是吹毛求疵,雞蛋里挑骨頭嘛!這面試不參加也罷!
但是,你想啊,如果當線程執行到取值或者++操作時,線程突然切換了,會不會有問題呢?
step1:雙線程場景
public class ThreadTest1 {
int a = 1;
int b = 1;
public void add() {
System.out.println("add start");
for (int i = 0; i < 10000; i++) {
a++;
b++;
}
System.out.println("add end");
}
public void compare() {
System.out.println("compare start");
for (int i = 0; i < 10000; i++) {
boolean flag = a < b;
if (flag) {
System.out.println("a=" + a + ",b=" + b + "flag=" + flag + ",a < b = " + (a < b));
}
}
System.out.println("compare end");
}
public static void main(String[] args) {
ThreadTest1 threadTest = new ThreadTest1();
new Thread(() -> threadTest.add()).start();
new Thread(() -> threadTest.compare()).start();
}
}
哎呀我去,還真有問題,你這吹毛求疵i++三步走,逼格滿滿。
到底為什么會這樣呢?加點日志看一下。
原來如此,兩個線程交替執行了。

step2:如何解決高并發場景下i++不安全的問題?變量上加個volatile關鍵字試試。
看哪吒前段時間分享的高并發系列文章,好像有一個關鍵字volatile,感覺挺好用,試試看。
我記得是這樣的:
volatile 關鍵字來保證可見性和禁止指令重排。volatile 提供 happens-before 的保證,確保一個線程的修改能對其他線程是可見的。
當一個共享變量被 volatile 修飾時,它會保證修改的值會立即被更新到主存,當有其他線程需要讀取時,它會去內存中讀取新值。從實踐角度而言,volatile 的一個重要作用就是和 CAS 結合,保證了原子性。
靠譜,安排上。
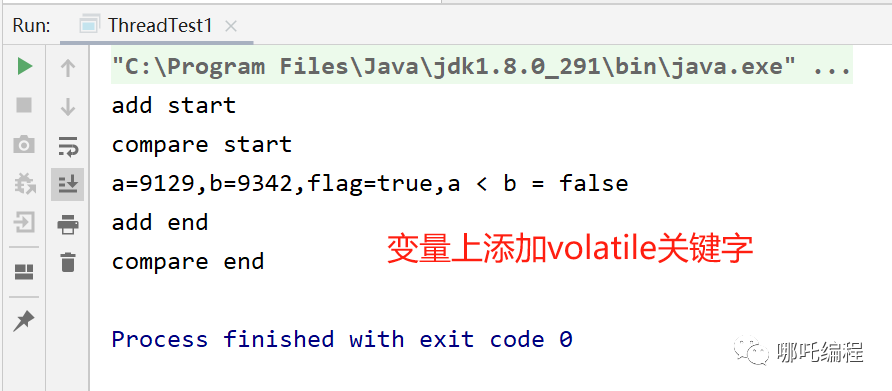
你看,好用吧,異常減少了,還得是你啊,大聰明!!!
為什么不好使呢?
1、volatile保證可見性
一個線程修改此變量后,該值會立刻刷新到主內存,其它線程每次都會從主內存中讀取更新后的新值,這就保證了可見性;
簡而言之,線程對volatile修飾的變量進行讀寫操作,都會經過主內存。
2、volatile禁止指令重排,通過內存屏障實現的
JVM編譯器可以通過在程序編譯生成的指令序列中插入內存屏障來禁止在內存屏障前后的指令發生重排。
volatile雖然可以保證數據的可見性和有序性,但不能保證數據的原子性。
- 讀屏障插入在讀指令前面,能夠讓CPU緩存中的數據失效,直接從主內存中讀取數據;
- 寫屏障插入在寫指令后面,能夠讓寫入CPU緩存的最新數據立刻刷新到主內存;
volatile無法保證數據的原子性
step3:那怎么辦?我記得可以加鎖來著,都給它鎖上,不就好了?
public class LockTest {
int a = 1;
int b = 1;
public void add() {
Lock lock = new ReentrantLock();
try {
lock.lock();
System.out.println("add start");
for (int i = 0; i < 10000; i++) {
a++;
b++;
}
System.out.println("add end");
} finally {
lock.unlock();
}
}
public void compare() {
Lock lock = new ReentrantLock();
try {
lock.lock();
System.out.println("compare start");
for (int i = 0; i < 10000; i++) {
boolean flag = a < b;
if (flag) {
System.out.println("a=" + a + ",b=" + b + "flag=" + flag + ",a < b = " + (a < b));
}
}
System.out.println("compare end");
} finally {
lock.unlock();
}
}
}一頓輸出猛如虎~
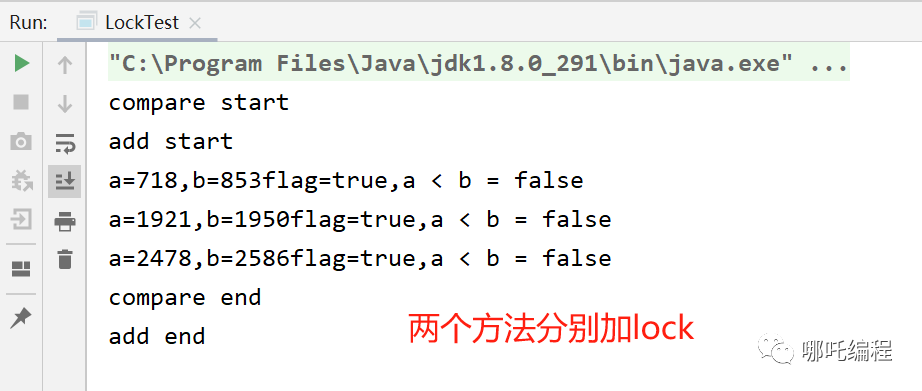
我草,不玩了,我要睡了。
這又是為什么啊?
這個問題的關鍵是要保證變量a和b的++操作是原子性的。
那么,問題來了,lock可以解決嗎?
- Lock可以保證lock()方法和unlock()方法之間的代碼是線程安全的。
- Lock一般是通過自旋和CAS的方式進行給程序加鎖,當有一個線程搶到所的資源,其他則進行等待。
- Lock發生異常時候,不會主動釋放占有的鎖,必須手動unlock來釋放鎖,所以unlock一般都寫在finally里。
- Lock等待鎖過程中可以用interrupt來中斷等待。
- Lock可以通過trylock來知道有沒有獲取鎖。
- Lock可以控制鎖的范圍,提高多個線程進行讀操作的效率。
- ...
打住,你這和a++原子性也沒關系啊。
之前出現問題,是因為add和compare交替執行造成的,lock明顯是解決不了這個問題的。
lock不行的本質原因還是:synchronized是阻塞式加鎖,lock是非阻塞式加鎖。
step4:我記得還有一個synchronized關鍵字來著,加上。
為兩個方法都加上synchronized關鍵字,確保add()方法執行時,compare()方法是不執行的。
本質原因:synchronized可以保證如果add線程獲取到鎖的資源,發生阻塞,compare線程會一直等待。
public class SynchronizedTest {
int a = 1;
int b = 1;
public synchronized void add() {
System.out.println("add start");
for (int i = 0; i < 10000; i++) {
a++;
b++;
}
System.out.println("add end");
}
public synchronized void compare() {
System.out.println("compare start");
for (int i = 0; i < 10000; i++) {
boolean flag = a < b;
if (flag) {
System.out.println("a=" + a + ",b=" + b + "flag=" + flag + ",a < b = " + (a < b));
}
}
System.out.println("compare end");
}
}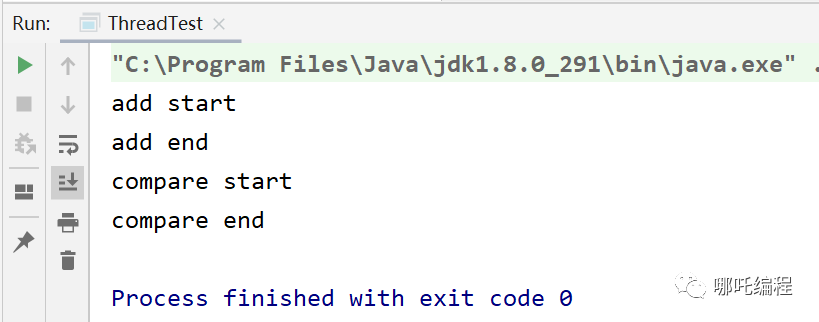
看到這里,高并發場景下i++會遇到哪些問題?就可以到此為止了,多角度剖析i++高并發問題。
真的沒問題了嗎?在所有方法上都加synchronized?效率怎么樣?





















