以下是我在RWKV播客中的一些想法摘要:https://www.latent.space/p/rwkv#details

為什么替代方案很重要?
隨著2023年的人工智能革命,Transformer架構(gòu)目前正處于巔峰。然而,由于人們急于采用成功的Transformer架構(gòu),所以會(huì)容易忽視可以借鑒的替代品。
作為工程師,我們不應(yīng)該采取一刀切的方法,對(duì)每顆釘子都使用相同的錘子。我們應(yīng)該在每一個(gè)解決方案中找到取舍;否則將會(huì)被困在特定平臺(tái)的限制范圍內(nèi),同時(shí)因不知道有其他選擇而感到“幸福”,這可能會(huì)使發(fā)展一夜回到解放前。
這個(gè)問(wèn)題并不是人工智能領(lǐng)域獨(dú)有的,而是一種從古到今都在重復(fù)的歷史模式。
SQL戰(zhàn)爭(zhēng)歷史的一頁(yè)……
最近軟件開(kāi)發(fā)中一個(gè)值得注意的例子是,當(dāng)SQL服務(wù)器開(kāi)始受到物理限制時(shí),便出現(xiàn)了NoSQL的趨勢(shì)。世界各地的初創(chuàng)企業(yè)都出于“規(guī)模”的原因轉(zhuǎn)向了NoSQL,盡管它們遠(yuǎn)未達(dá)到這些規(guī)模。
然而,隨著時(shí)間的推移,當(dāng)最終一致性和NoSQL管理開(kāi)銷的出現(xiàn),以及硬件功能在SSD速度和容量方面的巨大飛躍, SQL服務(wù)器最近又出現(xiàn)了回歸的趨勢(shì),因?yàn)樗鼈兪褂煤?jiǎn)單性,并且現(xiàn)在90%以上的初創(chuàng)公司都有足夠的可擴(kuò)展性。
這是否意味著SQL比NoSQL更好,或反之亦然?不,這只是意味著每種技術(shù)都有優(yōu)缺點(diǎn)和學(xué)習(xí)點(diǎn)的首選用例,這些用例可以在類似技術(shù)中交叉?zhèn)鞑ァ?/span>
目前Transformer架構(gòu)最大的痛點(diǎn)是什么?
通常,這包括計(jì)算、上下文大小、數(shù)據(jù)集和對(duì)齊。在本次討論中,我們將重點(diǎn)討論計(jì)算和上下文長(zhǎng)度:
- 由于使用/生成的每個(gè)令牌的O(N^2)增加而導(dǎo)致的二次計(jì)算成本。這使得大于10萬(wàn)的上下文大小非常昂貴,從而影響推理和訓(xùn)練。
- 當(dāng)前的GPU短缺加劇了這個(gè)問(wèn)題。
- 上下文大小限制了Attention機(jī)制,嚴(yán)重限制了“智能代理”用例(如smol-dev),并強(qiáng)制解決問(wèn)題。較大的上下文需要較少的解決方法。
那么,我們?cè)撊绾谓鉀Q這個(gè)問(wèn)題呢?
介紹RWKV:一種線性Transformer/現(xiàn)代大型RNN
RWKV和微軟RetNet是第一個(gè)被稱為“線性Transformer”的新類別。
它通過(guò)支持以下內(nèi)容直接解決了上述三個(gè)限制:
- 線性計(jì)算成本,與上下文大小無(wú)關(guān)。
- 在CPU(尤其是ARM)中,允許以更低的要求在RNN模式下輸出合理的令牌/秒。
- 沒(méi)有作為RNN的硬上下文大小限制。文檔中的任何限制都是指導(dǎo)原則——您可以對(duì)其進(jìn)行微調(diào)。
隨著我們不斷將人工智能模型擴(kuò)大到100k及以上的上下文大小,二次方計(jì)算成本開(kāi)始呈指數(shù)級(jí)增長(zhǎng)。
然而,線性Transformer并沒(méi)有放棄遞歸神經(jīng)網(wǎng)絡(luò)架構(gòu)及解決其瓶頸,這迫使它們被取代。
不過(guò),重新設(shè)計(jì)的RNN吸取了Transformer可擴(kuò)展的經(jīng)驗(yàn)教訓(xùn),使RNN能與Transformer工作方式類似,并消除了這些瓶頸。
在訓(xùn)練速度方面,用Transformer讓它們重返賽場(chǎng)——允許它們?cè)贠(N)成本下高效運(yùn)行,同時(shí)在訓(xùn)練中擴(kuò)展到10億個(gè)參數(shù)以上,同時(shí)保持類似的性能水平。
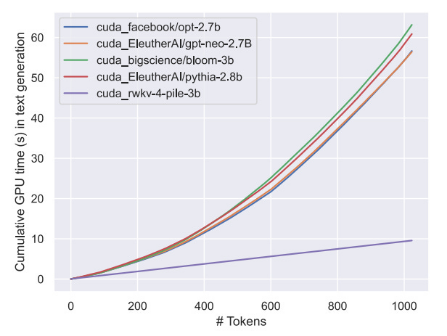
圖表:線性Transformer計(jì)算成本按每個(gè)令牌線性縮放與變換器的指數(shù)增長(zhǎng)
當(dāng)你按平方比線性縮放時(shí),你將在2k令牌計(jì)數(shù)時(shí)達(dá)到10倍以上,在100k令牌長(zhǎng)度時(shí)達(dá)到100倍以上。
在14B參數(shù)下,RWKV是最大的開(kāi)源線性Transformer,與GPT NeoX和其他類似數(shù)據(jù)集(如the Pile)不相上下。
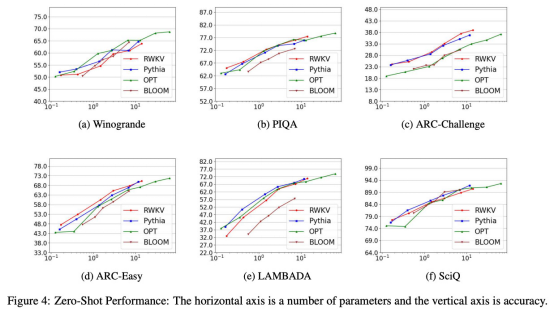
各種基準(zhǔn)顯示RWKV模型的性能與類似規(guī)模的現(xiàn)有變壓器模型相當(dāng)
但用更簡(jiǎn)單的話來(lái)說(shuō),這意味著什么?
優(yōu)點(diǎn)
- 在較大的上下文大小中,推理/訓(xùn)練比Transformer便宜10倍甚至更多
- 在RNN模式下,可以在非常有限的硬件上緩慢運(yùn)行
- 與相同數(shù)據(jù)集上的Transformer性能相似
- RNN沒(méi)有技術(shù)上下文大小限制(無(wú)限上下文!)
缺點(diǎn)
- 滑動(dòng)窗口問(wèn)題,有損內(nèi)存超過(guò)某一點(diǎn)
- 尚未證明可擴(kuò)展到14B參數(shù)以上
- 不如變壓器優(yōu)化和采用
因此,雖然RWKV還沒(méi)有達(dá)到LLaMA2那樣的60B+參數(shù)規(guī)模,但有了正確的支持/資源,它有可能以更低的成本和更大的環(huán)境實(shí)現(xiàn)這一目標(biāo),尤其是在模型趨向于更小、更高效的情況下。
如果效率對(duì)您的用例很重要,請(qǐng)考慮它。但這并不是最終的解決方案——健康的替代品仍然是關(guān)鍵。
我們可能應(yīng)該學(xué)習(xí)的其他替代方案及其好處
擴(kuò)散模型:文本訓(xùn)練速度較慢,但對(duì)多時(shí)期訓(xùn)練具有極高的彈性。找出原因可以幫助緩解令牌危機(jī)。
生成對(duì)抗性網(wǎng)絡(luò)/代理:可以在沒(méi)有數(shù)據(jù)集的情況下,使用技術(shù)將所需的訓(xùn)練集訓(xùn)練到特定目標(biāo),即使是基于文本的模型。
原文標(biāo)題:Introducing RWKV: The Rise of Linear Transformers and Exploring Alternatives,作者:picocreator
https://hackernoon.com/introducing-rwkv-the-rise-of-linear-transformers-and-exploring-alternatives