6.7k Star量的vLLM出論文了,讓每個人都能輕松快速低成本地部署LLM服務(wù)
今年六月,來自加州大學(xué)伯克利分校等機構(gòu)的一個研究團隊開源了 vLLM(目前已有 6700 多個 star),其使用了一種新設(shè)計的注意力算法 PagedAttention,可讓服務(wù)提供商輕松、快速且低成本地發(fā)布 LLM 服務(wù)。

在當時的博客文章中,該團隊宣稱 vLLM 能實現(xiàn)比 HuggingFace Transformers 高 24 倍的吞吐量!
八月底,該項目還與其它另外 7 個開源項目一道獲得了 a16z 開源人工智能資助計劃的首輪資助。
現(xiàn)在離 vLLM 最初宣布時差不多已過去三個月,他們終于發(fā)布了這篇關(guān)于 vLLM 和 PagedAttention 的研究論文,其中詳細解釋了他們?nèi)绾瓮ㄟ^類似操作系統(tǒng)虛擬內(nèi)存管理的機制來實現(xiàn)高效的 LLM 服務(wù)。該論文已被將于十月底在德國舉辦的 ACM 操作系統(tǒng)原理研討會(SOSP 2023)接收。

- 論文:https://arxiv.org/abs/2309.06180
- 代碼:https://github.com/vllm-project/vllm
- 文檔:https://vllm.readthedocs.io/
GPT 和 PaLM 等大型語言模型(LLM)的出現(xiàn)催生出了開始對我們的工作和日常生活產(chǎn)生重大影響的新應(yīng)用,比如編程助理和通用型聊天機器人。
許多云計算公司正競相以托管服務(wù)的方式提供這些應(yīng)用。但是,運行這些應(yīng)用的成本非常高,需要大量硬件加速器,如 GPU。根據(jù)最近的估計,相比于傳統(tǒng)的關(guān)鍵詞查詢方法,處理一個 LLM 請求的成本超過其 10 倍以上。考慮到成本如此之高,提高 LLM 服務(wù)系統(tǒng)的吞吐量(并由此降低單位請求的成本)就變得更為重要了。
LLM 的核心是自回歸 Transformer 模型。該模型可基于輸入(prompt)和其之前輸出的 token 序列生成詞(token),一次生成一個。對于每次請求,這個成本高昂的過程都會重復(fù),直到模型輸出終止 token。這種按序列的生成過程會讓工作負載受到內(nèi)存限制,從而無法充分利用 GPU 的計算能力,并會限制服務(wù)的吞吐量。
通過批量方式同時處理多個請求可以提高吞吐量。但是,要在單一批次中處理許多請求,就需要高效地管理每個請求所占用的內(nèi)存空間。
舉個例子,圖 1(左)展示了一個 130 億參數(shù)的 LLM 在一臺 40GB RAM 的英偉達 A100 GPU 上的內(nèi)存分布。

其 65% 的內(nèi)存都分配給了模型權(quán)重,而模型權(quán)重在提供服務(wù)期間是不會變化的。
30% 的內(nèi)存是用于存儲請求的動態(tài)狀態(tài)。對 Transformer 而言,這些狀態(tài)由與注意力機制關(guān)聯(lián)的鍵(key)和值(value)張量構(gòu)成,通常被稱為 KV 緩存,其表示用于生成序列中新輸出 token 的之前 token 上下文。
其余占比很小的內(nèi)存則是用于其它數(shù)據(jù),包括激活 —— 評估 LLM 時創(chuàng)建的臨時張量。
由于模型權(quán)重恒定不變,激活也只會占用少量 GPU 內(nèi)存,因此對 KV 緩存的管理方式就成了決定最大批量大小的關(guān)鍵。如果管理方式很低效,KV 緩存內(nèi)存就會極大限制批量大小,并由此限制 LLM 的吞吐量,如圖 1(右)所示。
來自 UC 伯克利等機構(gòu)的這個研究團隊在論文中表示,他們觀察到當前的 LLM 服務(wù)系統(tǒng)都沒有高效地管理 KV 緩存內(nèi)存。主要原因是它們會將請求的 KV 緩存保存在鄰接的內(nèi)存空間中,因為大多數(shù)深度學(xué)習(xí)框架都需要將張量存儲在相鄰連續(xù)的內(nèi)存中。
但是,不同于傳統(tǒng)深度學(xué)習(xí)工作負載中的張量,KV 緩存有其自己的獨特性質(zhì):它會在模型生成新 token 的過程中隨時間動態(tài)地增長和縮小,而且它的持續(xù)時間和長度是無法事先知曉的。
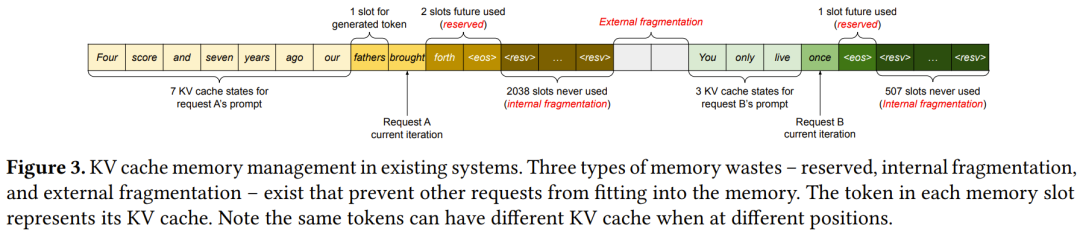
這些特性使得現(xiàn)有系統(tǒng)的方法極其低效,這主要體現(xiàn)在兩方面:
第一,現(xiàn)有系統(tǒng)存在內(nèi)部和外部內(nèi)存碎片的問題。
為了將請求的 KV 緩存存儲在相鄰連續(xù)的空間中,現(xiàn)有系統(tǒng)會預(yù)先分配一塊限制了請求最大長度的相鄰連續(xù)內(nèi)存。這會導(dǎo)致嚴重的內(nèi)部碎片化,因為請求的實際長度可能比其最大長度短很多。
此外,就算能事先知道實際長度,預(yù)先分配內(nèi)存的方法依然很低效。因為那一整塊內(nèi)存在請求的生命周期中都被占用了,其它更短的請求無法使用這一塊內(nèi)存 —— 盡管可能其中很大一部分都未被使用。
此外,外部內(nèi)存碎片可能也很顯著,因為每個請求預(yù)先分配的內(nèi)存大小可能都不同。
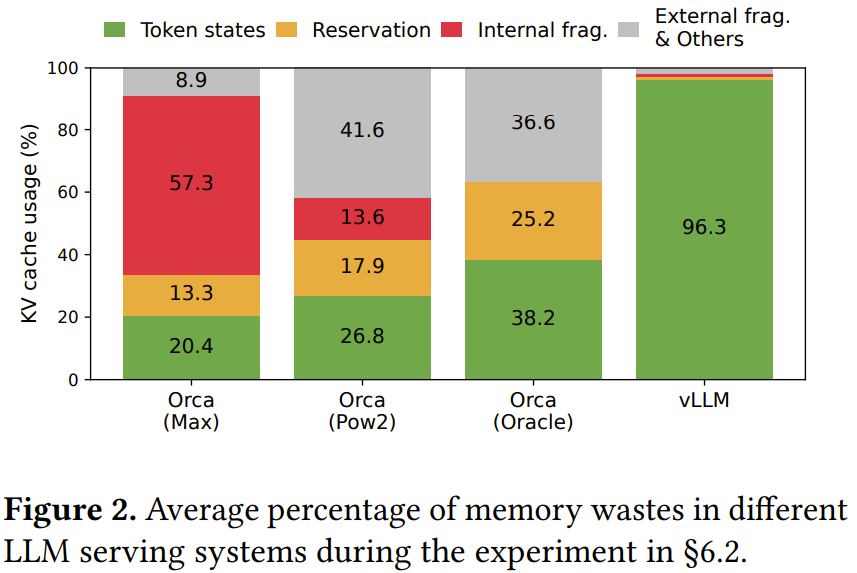
事實上,我們可以在圖 2 的分析中看到,在現(xiàn)有系統(tǒng)中,僅有 20.4%-38.2% 的 KV 緩存內(nèi)存會用于存儲實際的 token 狀態(tài)。
第二,現(xiàn)有系統(tǒng)無法利用內(nèi)存共享的機會。
LLM 服務(wù)通常會使用先進的解碼算法,例如并行采樣和波束搜索,這些方法可為每個請求生成多個輸出。在這些場景中,由多個序列組成的請求可以部分共享它們的 KV 緩存。但是,現(xiàn)有系統(tǒng)不可能使用內(nèi)存共享,因為不同序列的 KV 緩存存儲在分開的相鄰連續(xù)空間中。
為了解決上述限制,該團隊提出了一種注意力算法 PagedAttention;該算法的靈感來自操作系統(tǒng)(OS)解決內(nèi)存碎片化和內(nèi)存共享的方案:使用分頁機制的虛擬內(nèi)存。
PagedAttention 會將請求的 KV 緩存分成一塊塊的,每一塊(block)都包含一定數(shù)量 token 的注意力鍵和值。在 PagedAttention 中,KV 緩存的塊不一定要存儲在相鄰連續(xù)空間中。
這樣一來,就能以一種更為靈活的方式來管理 KV 緩存,就像是操作系統(tǒng)的虛擬內(nèi)存:你可以將那些塊看作是分頁,將 token 看作是字節(jié),將請求視為進程。通過使用相對較小的塊并按需分配它們,這種設(shè)計可以減少內(nèi)部碎片。
此外,它還能消除外部碎片,因為所有塊的大小都相同。
最后,它還能實現(xiàn)以塊為粒度的內(nèi)存共享;這種內(nèi)存共享支持與同一請求相關(guān)的不同序列,甚至也支持不同的請求。
立足于 PagedAttention,該團隊構(gòu)建了一個高吞吐量的分布式 LLM 服務(wù)引擎 vLLM,其幾乎做到了 KV 緩存內(nèi)存的零浪費。
vLLM 使用了塊級的內(nèi)存管理和搶占式的請求調(diào)度 —— 這些機制都是配合 PagedAttention 一起設(shè)計的。vLLM 支持 GPT、OPT 和 LLaMA 等各種大小的常用 LLM,包括那些超出單個 GPU 內(nèi)存容量的 LLM。
研究者基于多種模型和工作負載進行了實驗評估,結(jié)果表明:相比于當前最佳的系統(tǒng),vLLM 能在完全不影響準確度的前提下將 LLM 服務(wù)吞吐量提升 2-4 倍。而且當序列更長、模型更大、解碼算法更復(fù)雜時,vLLM 帶來的提升還會更加顯著。
總體而言,該研究的貢獻如下:
- 確認了提供 LLM 服務(wù)時的內(nèi)存分配挑戰(zhàn)并量化了它們對服務(wù)性能的影響。
- 提出了 PagedAttention,這是一種對存儲在非相鄰連續(xù)的分頁內(nèi)存中的 KV 緩存進行操作的注意力算法,其靈感來自操作系統(tǒng)中的虛擬內(nèi)存和分頁。
- 設(shè)計并實現(xiàn)了 vLLM,這是一個基于 PagedAttention 構(gòu)建的分布式 LLM 服務(wù)引擎。
- 通過多種場景對 vLLM 進行了實驗評估,結(jié)果表明其表現(xiàn)顯著優(yōu)于 FasterTransformer 和 Orca 等之前最佳方案。
方法概況
vLLM 的架構(gòu)如圖 4 所示。
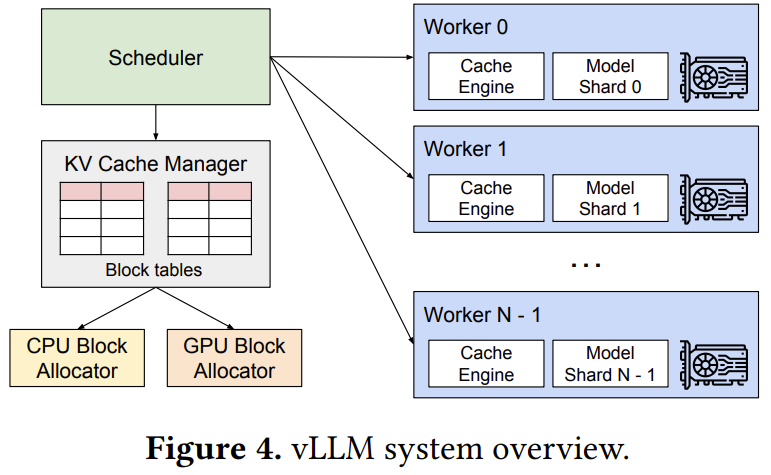
vLLM 采用一種集中式調(diào)度器(scheduler)來協(xié)調(diào)分布式 GPU 工作器(worker)的執(zhí)行。KV 緩存管理器由 PagedAttention 驅(qū)動,能以分頁方式有效管理 KV 緩存。具體來說,KV 緩存管理器通過集中式調(diào)度器發(fā)送的指令來管理 GPU 工作器上的物理 KV 緩存內(nèi)存。
PagedAttention
不同于傳統(tǒng)的注意力算法,PagedAttention 支持將連續(xù)的鍵和值存儲在非相鄰連續(xù)的內(nèi)存空間中。
具體來說,PagedAttention 會將每個序列的 KV 緩存分成 KV 塊。每一塊都包含固定數(shù)量 token 的鍵和值的向量;這個固定數(shù)量記為 KV 塊大小(B)。令第 j 個 KV 塊的鍵塊為 K_j,值塊為 V_j。則注意力計算可以轉(zhuǎn)換為以下形式的對塊的計算:

其中 A_{i,j} 是在第 j 個 KV 塊上的注意力分數(shù)的行向量。
在注意力計算期間,PagedAttention 核會分開識別并獲取不同的 KV 塊。
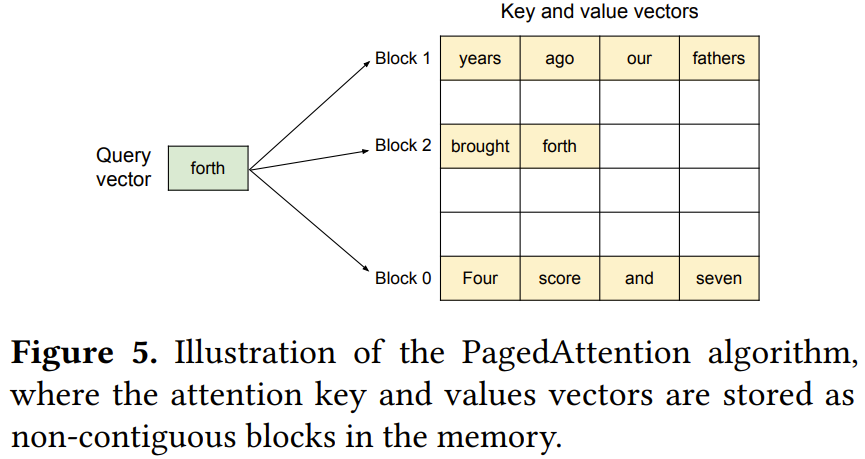
圖 5 給出了 PagedAttention 的一個示例:其鍵和值向量分布在三個塊上,并且這三個塊在物理內(nèi)存上并不相鄰連續(xù)。
每一次,這個 PagedAttention 核都會將查詢 token(forth)的查詢向量 q_i 與一個塊(比如 0 塊中的 Four score and seven 的鍵向量)中鍵向量 K_j 相乘,以計算注意力分數(shù) A_{i,j};然后再將 A_{i,j} 與塊中的值向量 V_j 相乘,得到最終的注意力輸出 o_i。
綜上所述,PagedAttention 算法能讓 KV 塊存儲在非相鄰連續(xù)的物理內(nèi)存中,從而讓 vLLM 實現(xiàn)更為靈活的分頁內(nèi)存管理。
KV 緩存管理器
使用 PagedAttention,該團隊將 KV 緩存組織為固定大小的 KV 塊,就像虛擬內(nèi)存中的分頁。
對 KV 緩存的請求會被表示成一系列邏輯 KV 塊,在生成新 token 和它們的 KV 緩存時從左向右填充。最后一個 KV 塊中未填充的位置留給未來填充。
使用 PagedAttention 和 vLLM 進行解碼
圖 6 通過一個示例展示了 vLLM 在對單個輸入序列的解碼過程中執(zhí)行 PagedAttention 和管理內(nèi)存的方式。
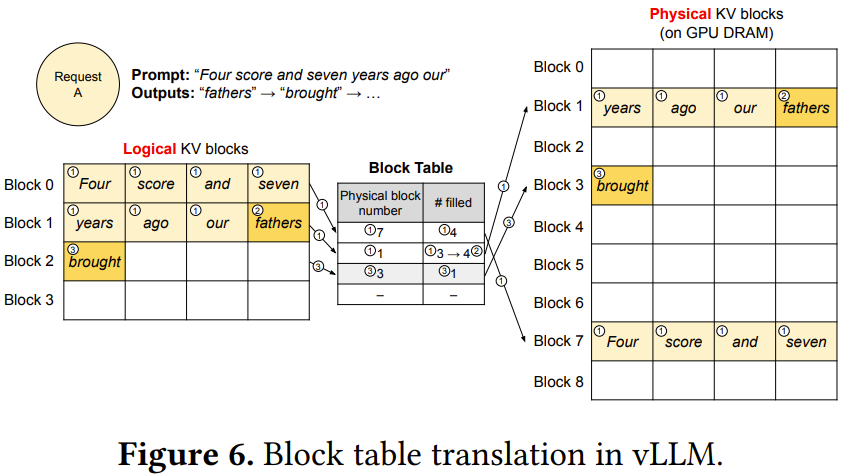
從全局來看,在每次解碼迭代中,vLLM 首先會選取一組候選序列來批處理,并為新請求的邏輯塊分配物理塊。
然后,vLLM 會將當前迭代的所有輸入 token 連接起來,組成一個序列并將其輸入到 LLM。在 LLM 的計算過程中,vLLM 使用 PagedAttention 核來訪問以邏輯 KV 塊形式存儲的之前的 KV 緩存,然后將新生成的 KV 緩存保存到物理 KV 塊中。
在一個 KV 塊中存儲多個 token(塊大小 > 1)可讓 PagedAttention 核并行處理多個位置的 KV 緩存,由此可以提升硬件使用率并降低延遲。
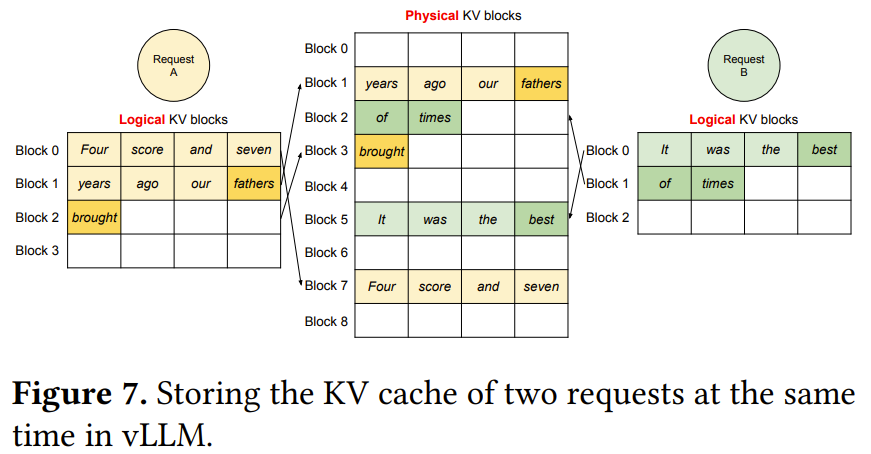
圖 7 給出了 vLLM 管理兩個序列的內(nèi)存的示例。
應(yīng)用于其它解碼場景
在許多成功的 LLM 應(yīng)用中,LLM 服務(wù)必須要能提供更為復(fù)雜的解碼場景 —— 有復(fù)雜的訪問模式和更多的內(nèi)存共享機會。研究者展示了 vLLM 的一般適用性。他們在論文中討論過的場景包括并行采樣、波束搜索、共享前綴、混合解碼方法。
比如圖 8 展示了一個帶有兩個輸出的并行編碼的例子。
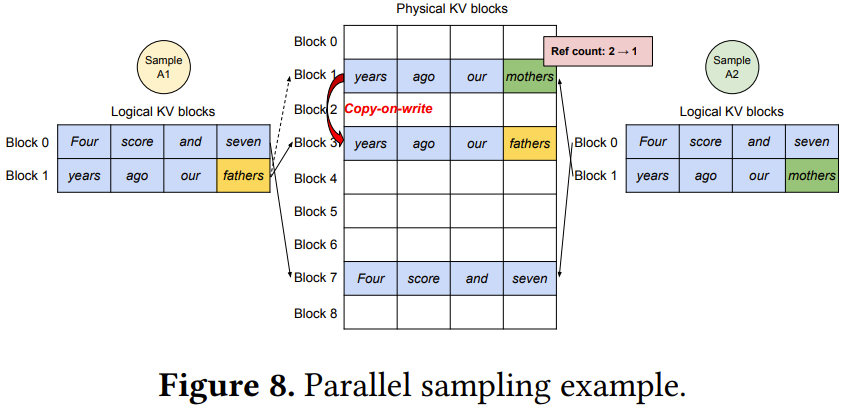
由于兩個輸出共享同一個 prompt,所以在 prompt 階段只需為 prompt 的狀態(tài)在內(nèi)存空間中保留一個副本;這兩個序列的 prompt 的邏輯塊都會映射到同一個物理塊。更多分析和示例請參閱原論文。
調(diào)度和搶占
LLM 面臨著一個獨特挑戰(zhàn):輸入 LLM 的 prompt 的長度變化范圍很大,并且輸出結(jié)果的長度也無法事先知曉,而要依輸入 prompt 和模型的情況而定。隨著請求和相應(yīng)輸出數(shù)量的增長,vLLM 可能會為了存儲新生成的 KV 緩存而耗盡 GPU 的物理塊。
對于這種情況,vLLM 需要回答兩個經(jīng)典問題:(1) 應(yīng)該淘汰(evict)哪些塊?(2) 如果再次需要,如何恢復(fù)已淘汰的塊?
通常來說,淘汰策略是使用啟發(fā)式方法來預(yù)測將在最遠的未來訪問的塊然后淘汰那個塊。由于這里已知是一起訪問一個序列的所有塊,所以該團隊實現(xiàn)了一種全清或不動的淘汰策略,即要么淘汰序列的所有塊,要么就全不淘汰。此外,一個請求中的多個序列會被組成一個序列組來一起調(diào)度。一個序列組中的序列總是會被一起搶占或重新調(diào)度,因為這些序列之間存在潛在的內(nèi)存共享。
為了解答第二個有關(guān)如何恢復(fù)已淘汰塊的問題,研究者考慮了兩種技術(shù):
- 交換。這是大多數(shù)虛擬內(nèi)存實現(xiàn)使用的經(jīng)典技術(shù),即把已淘汰的分頁復(fù)制到磁盤上的一個交換空間。在這里,研究者的做法是把已淘汰塊復(fù)制到 CPU 內(nèi)存。如圖 4 所示,除了 GPU 塊分配器之外,vLLM 還包括一個 CPU 塊分配器,用以管理交換到 CPU RAM 的物理塊。
- 重新計算。這個做法很簡單,就是當被搶占的序列被重新調(diào)度時,直接重新計算 KV 緩存。請注意,重新計算的延遲可能比原始延遲低得多。
交換和重新計算的性能取決于 CPU RAM 和 GPU 內(nèi)存之間的帶寬以及 GPU 的計算能力。
分布式執(zhí)行
vLLM 能有效用于分布式的硬件設(shè)置,因為其支持 Transformers 上廣泛使用的 Megatron-LM 式張量模型并行化策略。該策略遵循 SPMD(單程序多數(shù)據(jù))執(zhí)行調(diào)度方案,其中線性層會被分開以執(zhí)行逐塊的矩陣乘法,并且 GPU 會通過 allreduce 操作不斷同步中間結(jié)果。
具體來說,注意力算子會被分散在注意力頭維度上,每個 SPMD 過程負責多頭注意力中一個注意力頭子集。
實現(xiàn)
vLLM 是一個端到端服務(wù)提供系統(tǒng),具有 FastAPI 前端和基于 GPU 的推理引擎。
該前端擴展了 OpenAI API 接口,允許用戶為每個請求自定義采樣參數(shù),例如最大序列長度和波束寬度。
vLLM 引擎由 8500 行 Python 代碼和 2000 行 C++/CUDA 代碼寫成。
該團隊也用 Python 開發(fā)了一些與控制相關(guān)的組件,包括調(diào)度器和塊管理器,還為 PagedAttention 等關(guān)鍵操作開發(fā)了定制版 CUDA 核。
至于模型執(zhí)行器,他們使用 PyTorch 和 Transformer 實現(xiàn)了常用的 LLM,比如 GPT、OPT 和 LLaMA。
他們?yōu)榉植际?GPU 工作器之間的張量通信使用了 NCCL。
評估
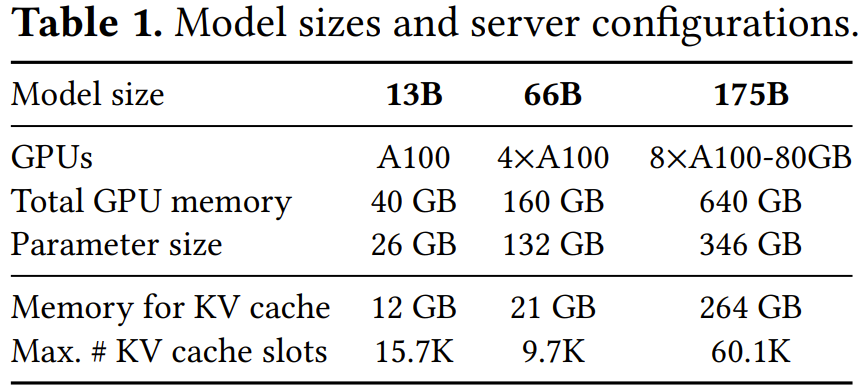
為了驗證 vLLM 的效果,該團隊進行了一系列實驗評估。表 1 給出了模型大小和服務(wù)器配置情況。
基礎(chǔ)采樣
在 ShareGPT 數(shù)據(jù)集上,vLLM 可以維持比 Orca (Oracle) 高 1.7-2.7 倍的請求率,比 Orca (Max) 則高 2.7-8 倍,同時還能維持相近的延遲,如圖 12 上面一行和圖 13a 所示。
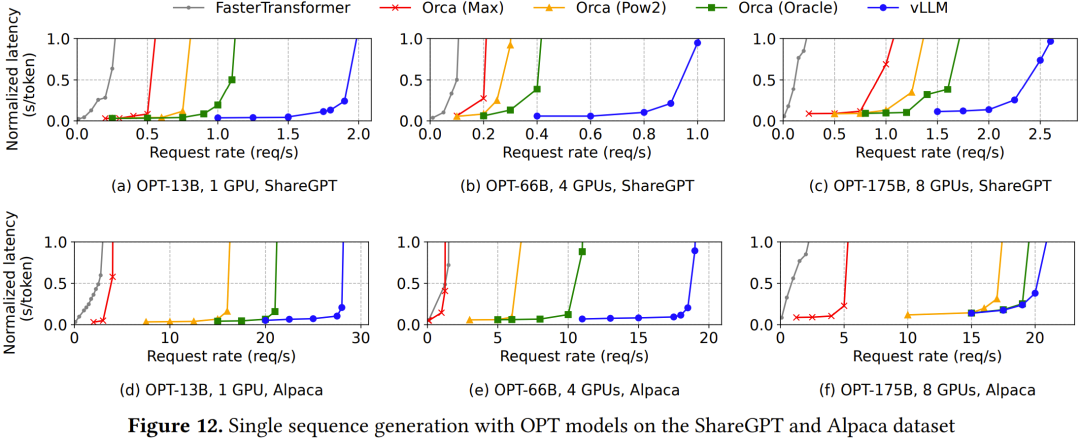
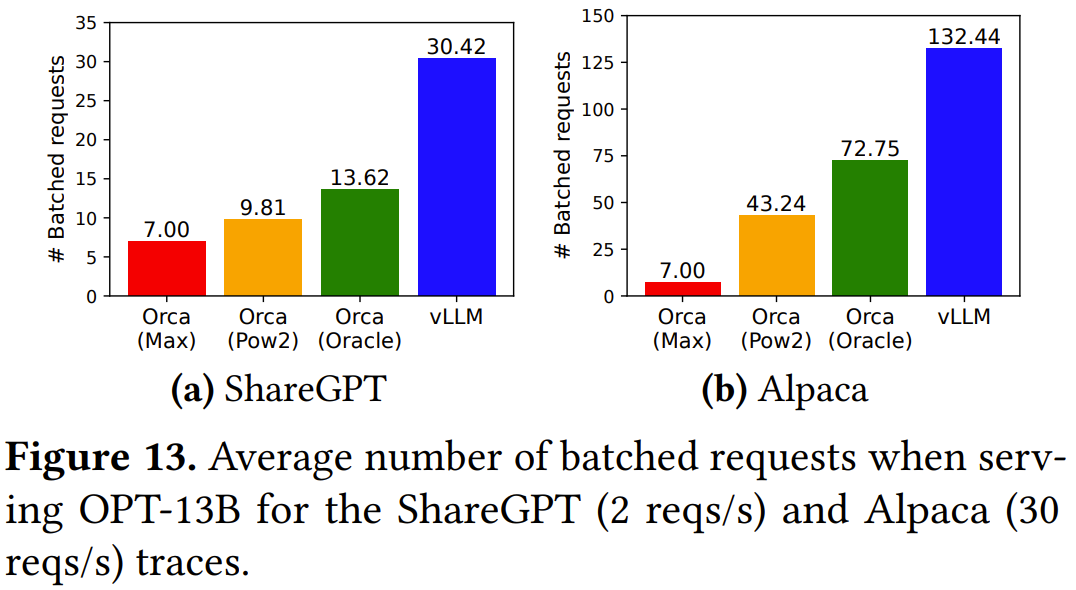
在 Alpaca 數(shù)據(jù)集上的結(jié)果也類似。
并行采樣和波束搜索
如圖 14 上面一行所示,如果要采樣的序列數(shù)量很多,則 vLLM 能在 Orca 基準的基礎(chǔ)上帶來更大的提升。
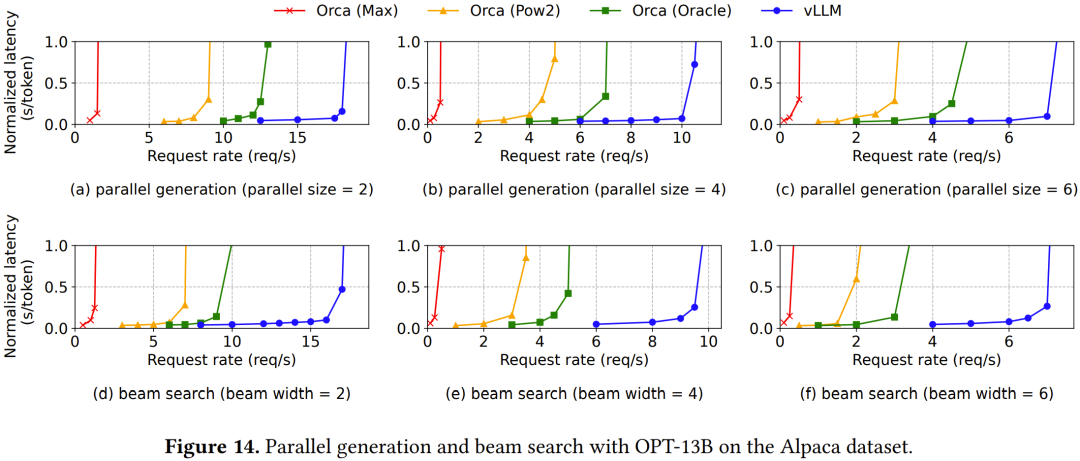
圖中下面一行則展示了不同波束寬度的波束搜索結(jié)果。由于波束搜索支持更多共享,所以 vLLM 帶來的性能優(yōu)勢還要更大。
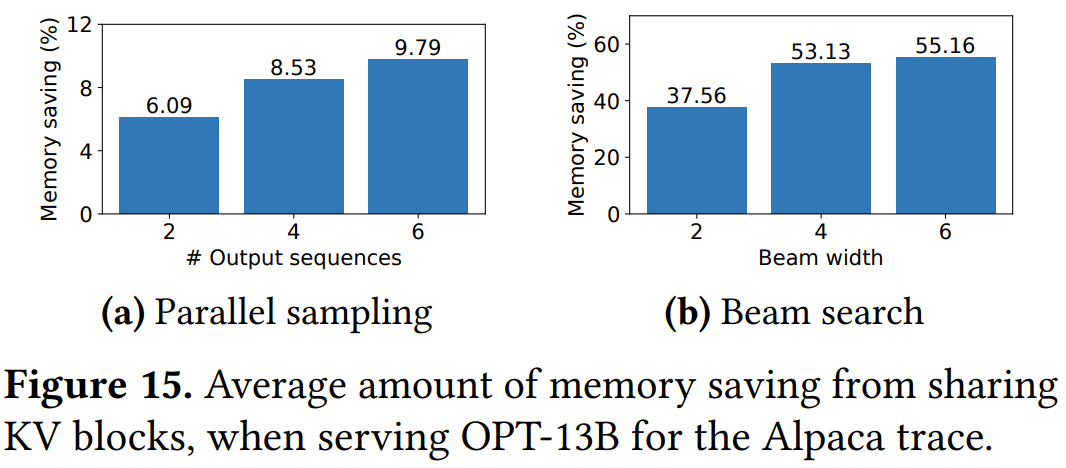
圖 15 展示了內(nèi)存節(jié)省量,計算方法是用因為共享而節(jié)省的塊數(shù)除以不使用共享時的總塊數(shù)。
共享前綴
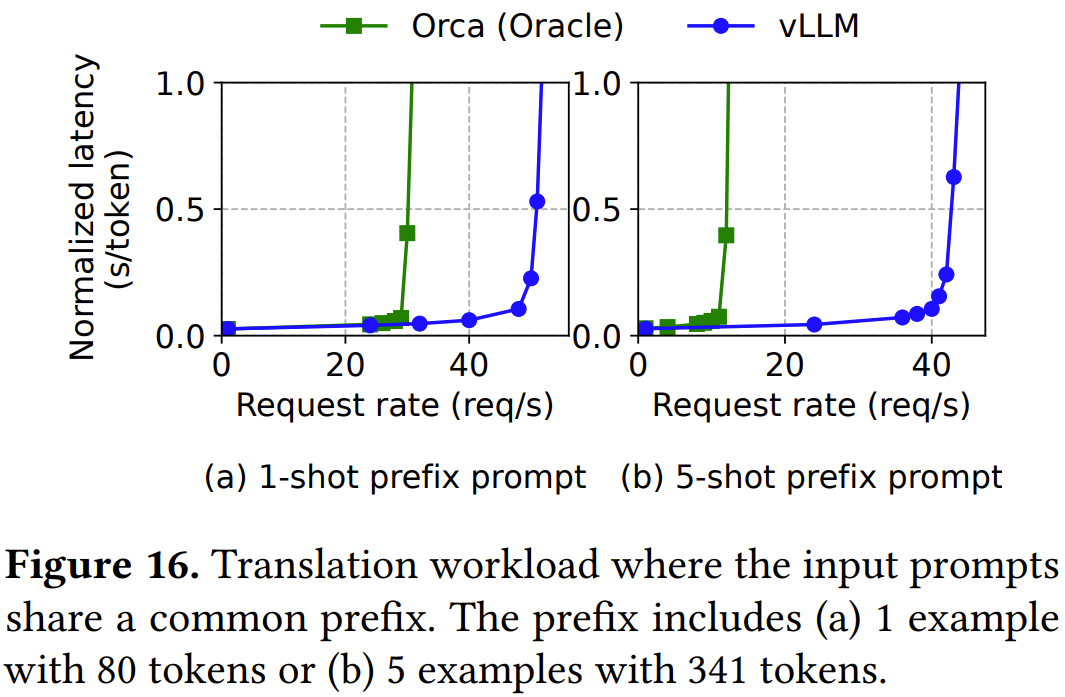
如圖 16a 所示,當共享單樣本前綴時,vLLM 的吞吐量比 Orca (Oracle) 高 1.67 倍。此外,當共享更多樣本時(圖 16b),vLLM 能實現(xiàn)比 Orca (Oracle) 高 3.58 倍的吞吐量。
聊天機器人
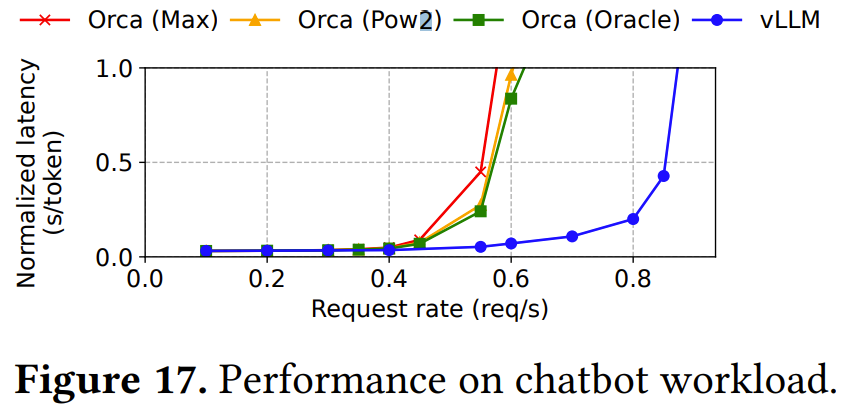
從圖 17 可以看出,相比于三個 Orca 基準模型,vLLM 可以維持高 2 倍的請求率。
該團隊也進行了消融實驗,表明 PagedAttention 確實有助于 vLLM 提升效率。他們也研究了塊大小與重新計算和交換技術(shù)的影響。詳情參閱原論文。