螞蟻信貸圖風控實踐

一、信貸圖風控業務背景及案例
首先簡單介紹我們的業務場景。
1、業務背景
我們做的信貸圖風控主要用于反騙貸和反套現的防控:
- 騙貸是指黑產惡意騙取貸款,無還款意愿。這種情況導致了較高的資金風險,業界來看占整體逾期貸款的30%-40%左右。
- 套現是指用戶通過虛假的交易場景,將信貸額度套取成現金。這種行為違反了信用卡、花唄等消費貸的使用規范,無法管控資金使用范圍,另外也容易造成多頭借貸,引起金融風險。
常見的套現騙貸手法包括:
- 掃碼模式:線下店鋪開通收款碼,保存本地或到店進行掃碼的方式,讓套現人使用花唄支付,進行套現。
- 淘寶模式:中介在網上開店,上架商品,套現人使用花唄支付完成虛擬網購,從而信用額度。
- 預下單模式:使用三方APP,下單后不支付,然后告訴套現人三方賬號密碼,由套現人登錄后使用花唄支付,完成套現。

基于信貸的業務特色,我們設計了事前、事中到事后的全面防控,各環節的主要內容為:
- 事前:提前感知、認知風險。包括對商戶進行風險分析、對用戶進行風險等級評級,這部分工作會用到近線的圖分析功能。
- 事中:當用戶申請貸款、或要用貸款去付錢時,基于交易請求實時分析和計算,進行風險策略和模型應用及圖譜的交叉驗證。
- 事后:對信貸業務進行全面的風險分析,如分析資金使用、套現可能性、挖掘團伙。
2、業務應用全局視角
我們基于事前、事中、事后的業務體系,設計了對應的技術框架。

- 事前:T+1調度進行圖跑批計算、由事件驅動的近線計算。
- 事中:基于請求在線實時計算,使用了圖數據庫的能力,保證查詢性能。
- 事后:近線的消息監控、T+1的全量分析,以及交互式圖分析。
上述模塊會用到的圖技術包括:圖的多度關系聚合特征(Traversal&Aggregate)、模式匹配(Pattern Matching)、圖社區檢測算法(Community Detection)、圖學習、圖推理等。
3、花唄反套現案例
下面我們通過花唄反套現的案例來說明事后和事中的防控。

事后
由于風控場景的Y標稀缺,如果依賴人工專家打標,對于專家未識別到的套現模式會出現無法覆蓋的情況。所以我們通過T+1的離線數據和實時數據開發了風險大圖,基于“近朱者赤近墨者黑”的思想,將Pattern Matching中識別到的黑、灰種子,進一步在圖上擴散傳播,從識別更多風險用戶,并將風險由單點轉換為社團。
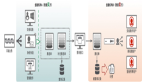
事中
傳統事中實時風控計算,多使用Flink產出統計型特征,它無法刻畫多度關系。另外,如果圖Pattern全部依賴專家定義存在效率和覆蓋度的問題。所以我們使用了在線子圖,包括買家子圖、賣家子圖、買賣家連通子圖,作為神經網絡的輸入并在線打分,從而進行實時的防控。
二、圖風控規模化落地
1、微貸圖平臺

圖風控技術規模化的業務落地,一開始我們只是簡單的嘗試,效率比較低,因為信貸場景較為嚴謹,上線需要進行離線測算、旁路驗證。這就需要保證離線在線的數據源頭一致、計算語義一致,實現圖仿真功能。否則只能通過離線表JOIN的方式進行構圖,很難支持3-6個月的圖回測。
我們通過技術驗證后,沉淀了一套能力,包括:
- 圖建模:離線、近線、在線的圖資產統一。
- 圖交互式分析:專家使用圖交互式分析進行研判。
- 圖仿真回測:基于分析的case進行3-6個月的圖仿真回測。
- 圖計算服務上線:圖特征和圖算子的一鍵發布上線。
統一圖資產在分析,仿真和上線的語義一致、三線一體,保證了圖風控規模化的效率。
2、規模化效率瓶頸

做完規模化后,我們發現業務流程前面的模塊都是離線T+1跑批、或基于事件觸發,都是自動的。只有最后這一步需要人的分析,這個環節對人工的依賴,阻礙的圖的大規模應用,所以我們下一步的工作是自動挖掘風險。
三、子圖挖掘

我們之前的業務分析測算,都基于專家給出了明確的風險模式后進行處置,但其實這樣的流程周期很長,效率較低。所以我們目前正在自動挖掘風險模式,然后推薦給專家分析。
1、總體技術方案

整體技術方案分為以下幾步:
- 基于離線T+1及實時數據構建底圖。
- 計算圖中每個節點的表征向量,然后計算p-value值及各種業務指標
- 篩選節點,并基于種子節點進行擴散,獲得重要風險子圖
- 在子圖中進行風險模式的挖掘,獲得風險模式(Pattern)的候選集,并進行回測
- 回測結果符合預期指標的風險模式,交由業務方進行交互分析,并決定是否采用上線
- 通過這一套流程,我們把挖掘風險模式,結合算法和算力做到了自動化。
在這套流程中,有兩個比較大的挑戰:
- 信息混雜問題:底圖數據龐大,噪聲較多。
- 算力復雜問題:子圖同構算法復雜度為指數級。
2、信息混雜問題

對于信息混雜問題,當我們基于原始大圖進行挖掘時,首先圖的規模比較大,難以進行挖掘。另外,圖中有許多噪音,比如我們每天購買咖啡、早餐,當我們基于頻繁度進行挖掘時,這種模式很容易被挖掘出來,但沒有提供風險信息,應該被剔除。
我們的做法是基于完整的底圖,計算節點表征向量。然后根據節點p-value和業務指標,計算節點的重要度,最后裁剪低于一點重要度的節點,我們目前通常挖掘的圖在10億規模左右。這樣做可以剔除噪聲,并且提升挖掘的效率。
3、算力復雜問題
算力復雜度主要來源于組合爆炸,比如某種邊的類型只有10萬條,但它對應的pattern可能有11 億個,而我們的挖掘,每增加一度都需要反復驗證對應的業務指標,所以計算量非常大。

對于這個問題,我們有兩個解決辦法。第一是基于業務語義,對不合理的pattern進行剪枝。這種從業務應用的角度對圖進行剪枝,得到了比較好的效果。第二,從技術的角度,引入圖的外部存儲,緩解了大規模圖挖掘的內存壓力。
4、子圖自同構問題

子圖自同構,原本需要遍歷所有子圖進行對比,是一個np問題,比較難找到最優解。我們與高校合作,使用了數學的思路,將子圖映射成一個數學函數,然后通過數學函數可以比較快速的對比。這個方法不能解決所有問題,但是能解決大部分問題。我們基于這個思路進行了分布式的實現,從而更好地做圖挖掘,以及圖模式的匹配。
四、回顧總結

我們的信貸圖風控建設從2018年開始,基于專家總結的風險模式,轉換成圖模式匹配進行風險挖掘,它的特點是準確率高,但風險覆蓋度比較低。所以在2019年我們做了團伙算法,用于解決聚集性風險。2020年,我們從圖的靜態切面,分析圖的當前信息,推進到分析圖的時序演進狀態,進一步捕捉團伙的發展以及變化的信息。21年,我們做了圖平臺規模化的落地,實現三線一體。22、23年,我們的主要工作是做圖的自動挖掘和分析。
五、問答環節
Q1. 剛剛提到事中階段會在線進行攔截,時延是120毫秒,線上用了什么樣算法,還是用專家系統進行模式匹配?怎么做到120毫秒?
A:模式匹配和團伙發現是事后做的,社團的計算需要幾十秒。事中主要是在圖數據庫中查了買家子圖、賣家子圖、買家賣家連通子圖,主要做Traversal&Aggregate,進行表征向量抽取,然后進行深度學習模型的打分,這個過程大概消耗20毫秒左右。當然我們也在風控鏈路上做了許多優化,整套流程大概在70-80毫秒。
Q2. 20毫秒的查詢會涉及到幾度鄰居查詢?
A:買家和賣家子圖往外擴兩度,買家賣家連通子圖則是各擴兩度,并且各擴充兩度后可以連通。
Q3. 事中查詢時,圖的切片如何選取?
A:圖是有多個線程持續更新寫入數據的,當有訪問請求時,實時對被訪問節點進行Traversal&Aggregate。
Q4. 圖中節點表征的更新頻率是什么?
A:圖節點的表征是實時抽取計算的。
Q5. 子圖挖掘整體方案中,藍色模塊的評估任務,是自動化評估還是有業務專家介入評估?
A:這部分的評估是自動化評估,我們會基于風險的候選集,在3-6個月的圖上進行回測,然后根據歷史數據上匹配到的pattern,計算用戶、商戶的各種風險及業務指標,然后根據業務給出的口徑進行自動化的評估。