怎么去選消息隊(duì)列?Kafka vs. RabbitMQ
在上周,我們討論了使用消息隊(duì)列的好處。然后我們回顧了消息隊(duì)列產(chǎn)品的發(fā)展歷史。如今,在項(xiàng)目中需要使用消息隊(duì)列時(shí),Apache Kafka似乎是首選產(chǎn)品。然而,考慮到特定需求時(shí),它并不總是最佳選擇。

基于數(shù)據(jù)庫的隊(duì)列
讓我們再次使用星巴克的例子。最重要的兩個(gè)需求是:
- 異步處理,使收銀員可以在不等待的情況下接下一個(gè)訂單。
- 持久性,以防出現(xiàn)問題時(shí)錯(cuò)過顧客的訂單。
在這里,消息的順序不太重要,因?yàn)榭Х葞熃?jīng)常批量制作相同的飲料。可擴(kuò)展性也不是很重要,因?yàn)殛?duì)列受限于每個(gè)星巴克門店。
星巴克的隊(duì)列可以在數(shù)據(jù)庫表中實(shí)現(xiàn)。下面的圖表顯示了它的工作原理:
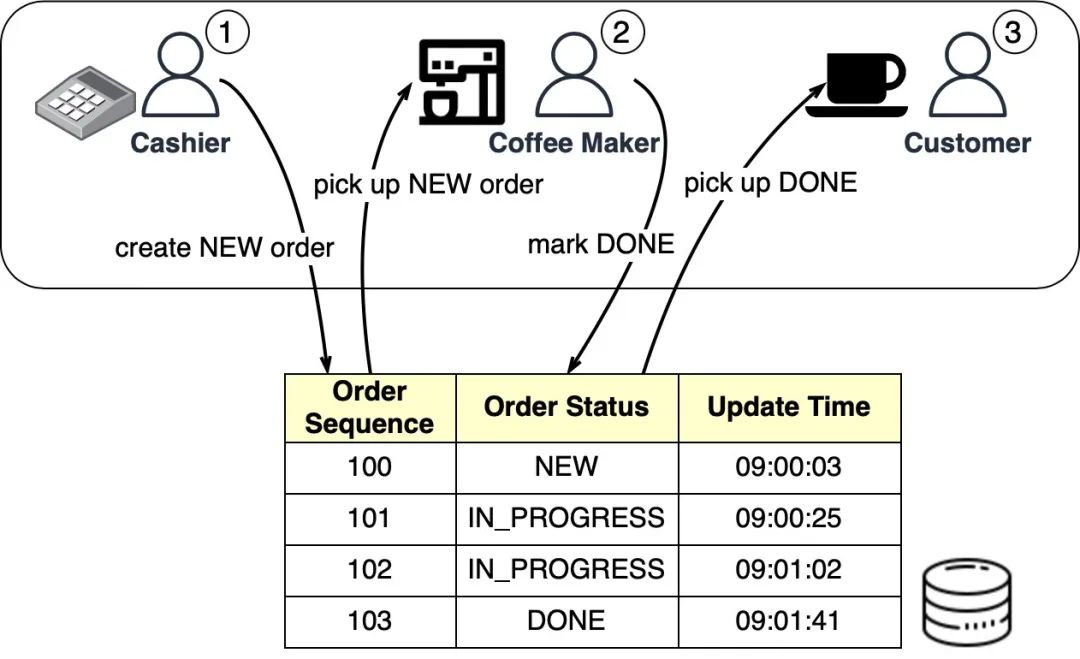
當(dāng)收銀員接受一個(gè)訂單時(shí),在數(shù)據(jù)庫支持的隊(duì)列中創(chuàng)建一個(gè)新訂單。然后收銀員可以繼續(xù)接受另一個(gè)訂單,而咖啡師則會批量獲取新的訂單。一旦訂單完成,咖啡師會在數(shù)據(jù)庫中標(biāo)記為已完成。然后顧客可以在柜臺上取走他們的咖啡。
每天結(jié)束時(shí)可以運(yùn)行一個(gè)維護(hù)作業(yè)來刪除已完成的訂單(即“DONE”狀態(tài)的訂單)。
對于星巴克的用例,一個(gè)簡單的數(shù)據(jù)庫隊(duì)列可以在不需要使用Kafka的情況下滿足需求。具有CRUD(創(chuàng)建-讀取-更新-刪除)操作的訂單表就可以勝任。
基于Redis的隊(duì)列
基于數(shù)據(jù)庫的消息隊(duì)列仍然需要開發(fā)工作來創(chuàng)建隊(duì)列表并從中讀取/寫入數(shù)據(jù)。對于預(yù)算有限且已經(jīng)使用Redis進(jìn)行緩存的小型創(chuàng)業(yè)公司,Redis也可以用作消息隊(duì)列。
有三種使用Redis作為消息隊(duì)列的方法:
- 發(fā)布/訂閱(Pub/Sub)
- 列表(List)
- 流(Stream)
下面的圖表顯示了它們的工作原理。
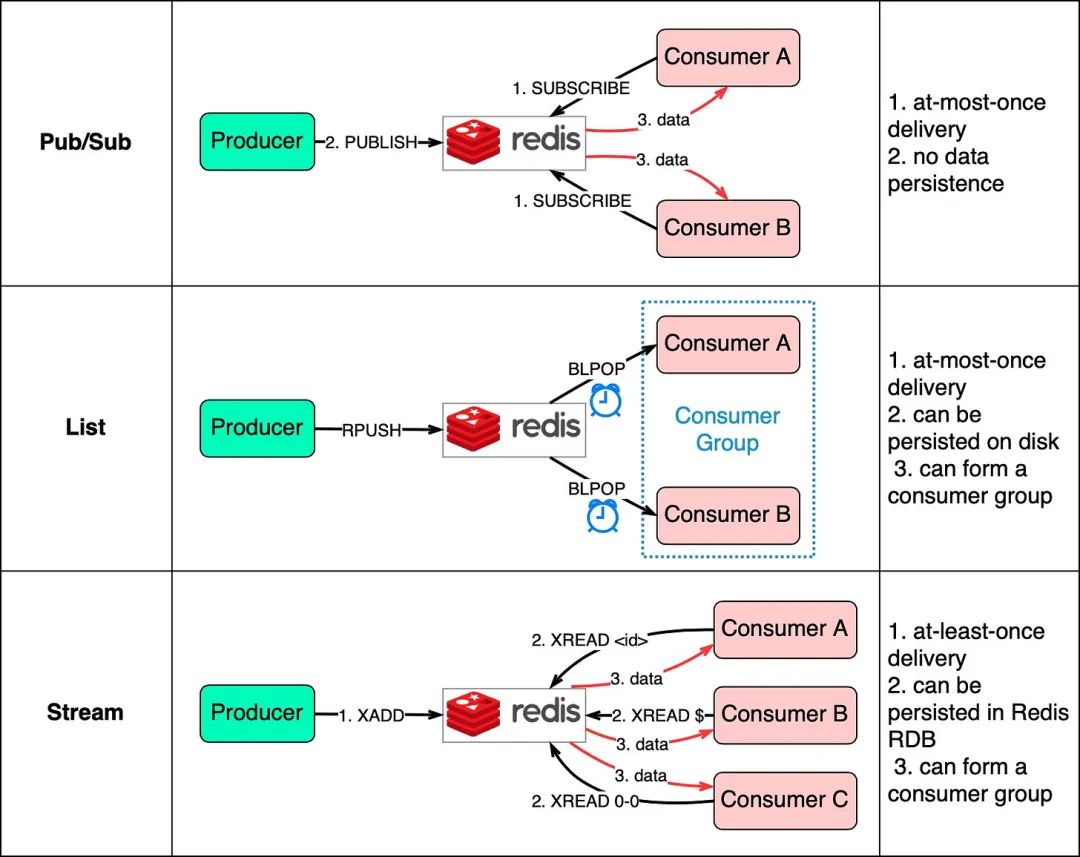
發(fā)布/訂閱是方便的,但有一些傳遞限制。消費(fèi)者訂閱一個(gè)鍵,當(dāng)生產(chǎn)者向相同的鍵發(fā)布數(shù)據(jù)時(shí),消費(fèi)者會接收數(shù)據(jù)。限制在于數(shù)據(jù)最多只會傳遞一次。如果消費(fèi)者關(guān)閉并且未接收到已發(fā)布的數(shù)據(jù),則該數(shù)據(jù)會丟失。此外,數(shù)據(jù)不會持久保存在磁盤上。如果Redis宕機(jī),所有發(fā)布/訂閱數(shù)據(jù)都會丟失。發(fā)布/訂閱適用于度量監(jiān)視等情況,其中可以接受一些數(shù)據(jù)丟失。
Redis中的列表數(shù)據(jù)結(jié)構(gòu)可以構(gòu)建FIFO(先進(jìn)先出)隊(duì)列。消費(fèi)者使用BLPOP以阻塞模式等待消息,因此應(yīng)該應(yīng)用超時(shí)。等待相同列表的消費(fèi)者形成一個(gè)消費(fèi)者組,每個(gè)消息只由一個(gè)消費(fèi)者消費(fèi)。作為Redis數(shù)據(jù)結(jié)構(gòu),列表可以持久保存在磁盤上。
流解決了上述兩種方法的限制。消費(fèi)者可以選擇從何處讀取消息 - 使用“$”表示新消息,“”表示特定消息ID,或使用“0-0”從開始讀取消息。
總而言之,基于數(shù)據(jù)庫和基于Redis的消息隊(duì)列易于維護(hù)。如果它們無法滿足我們的需求,專用的消息隊(duì)列產(chǎn)品更好。接下來我們將比較兩個(gè)流行的選項(xiàng)。
RabbitMQ vs. Kafka
對于需要可靠、可擴(kuò)展和可維護(hù)的系統(tǒng)的大公司,在以下方面評估消息隊(duì)列產(chǎn)品:
- 功能
- 性能
- 可擴(kuò)展性
- 生態(tài)系統(tǒng)
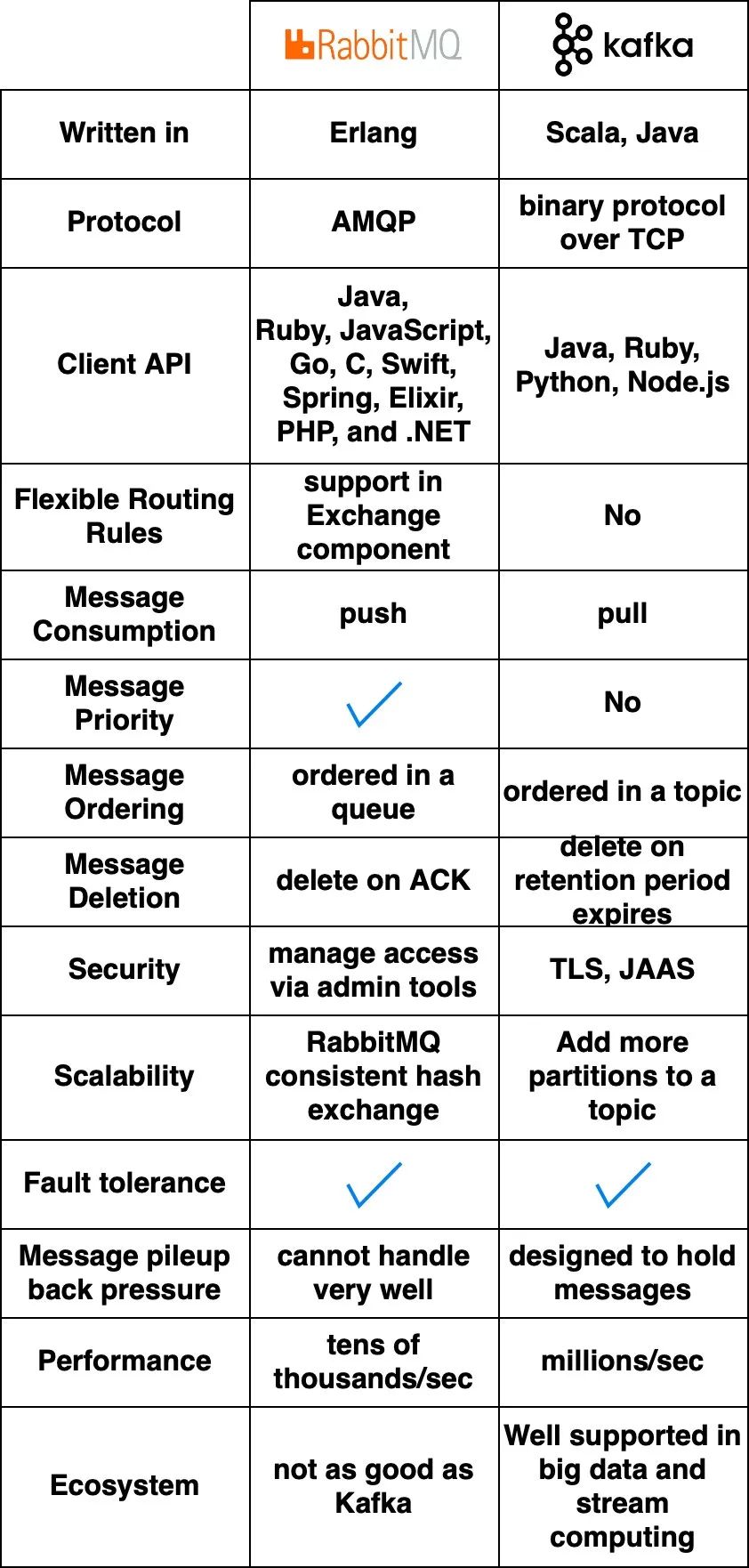
下面的圖表比較了兩種典型的消息隊(duì)列產(chǎn)品:RabbitMQ和Kafka。
工作原理
RabbitMQ的工作方式類似于消息中間件 - 它將消息推送給消費(fèi)者,然后在確認(rèn)后將其刪除。這避免了消息積壓,這是RabbitMQ認(rèn)為有問題的。
Kafka最初是為大規(guī)模日志處理而構(gòu)建的。它會保留消息直到過期,并允許消費(fèi)者以自己的速度拉取消息。
語言和API
RabbitMQ是用Erlang編寫的,這使得修改核心代碼變得具有挑戰(zhàn)性。然而,它提供了非常豐富的客戶端API和庫支持。
Kafka使用Scala和Java,但也有針對流行語言(如Python、Ruby 和Node.js)的客戶端庫和API。
性能和可擴(kuò)展性
RabbitMQ每秒可以處理數(shù)萬條消息。即使在更好的硬件上,吞吐量也不會大幅提高。
Kafka可以處理數(shù)百萬條每秒的消息,并具有很高的可擴(kuò)展性。
生態(tài)系統(tǒng)
許多現(xiàn)代大數(shù)據(jù)和流式應(yīng)用程序默認(rèn)集成了Kafka。這使得它非常適合這些用例。
消息隊(duì)列用例
既然我們已經(jīng)介紹了不同消息隊(duì)列的特點(diǎn),讓我們看一些如何選擇正確產(chǎn)品的示例。
日志處理與分析
對于具有購物車、訂單和付款等服務(wù)的電子商務(wù)網(wǎng)站,我們需要分析日志以調(diào)查顧客訂單。
下面的圖表顯示了使用“ELK”堆棧的典型架構(gòu):
- ElasticSearch - 為全文搜索索引日志
- LogStash - 日志收集代理
- Kibana - 用于搜索和可視化日志的用戶界面
- Kafka - 分布式消息隊(duì)列
 圖片
圖片