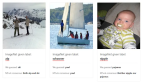
錯誤率降低44%!紐約大學最新「人臉生成」可讓年齡隨意變化:從少年到老年全覆蓋
當下的「人臉識別系統」抗衰老能力非常弱,人物面部老化會顯著降低識別性能,隔一段時間就需要更換人臉數據。

提升人臉識別系統的魯棒性需要收集個體老化的高質量數據,不過近幾年發布的數據集規模通常較小,年限也不夠長(如5年左右),或是在姿態、照明、背景等方面有較大變化,沒有專注于人臉數據。
最近,紐約大學的研究人員提出了一種通過隱擴散模型保留不同年齡身份特征的方法,并且只需要少樣本訓練,即可直觀地用「文本提示」來控制模型輸出。

論文鏈接:https://arxiv.org/pdf/2307.08585.pdf
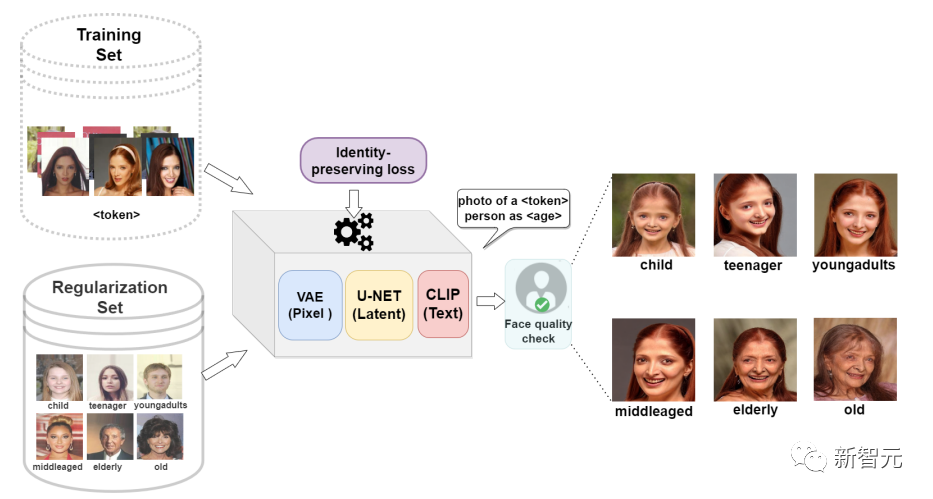
研究人員引入了兩個關鍵的組件:一個身份保持損失,以及一個小的(圖像,描述)正則化集合來解決現有的基于GAN的方法所帶來的限制。
在兩個基準數據集CeleA和AgeDB的評估中,在常用的生物特征忠誠度(biometric fidelity)指標上,該方法比最先進的基線模型在錯誤不匹配率上降低了約44%
追蹤人臉的年齡變化
DreamBooth
文中提出的方法基于潛擴散模型DreamBooth,其可以通過對文生圖擴散模型微調的方式將單個主體放置在其他上下文(re-contextualization)中。
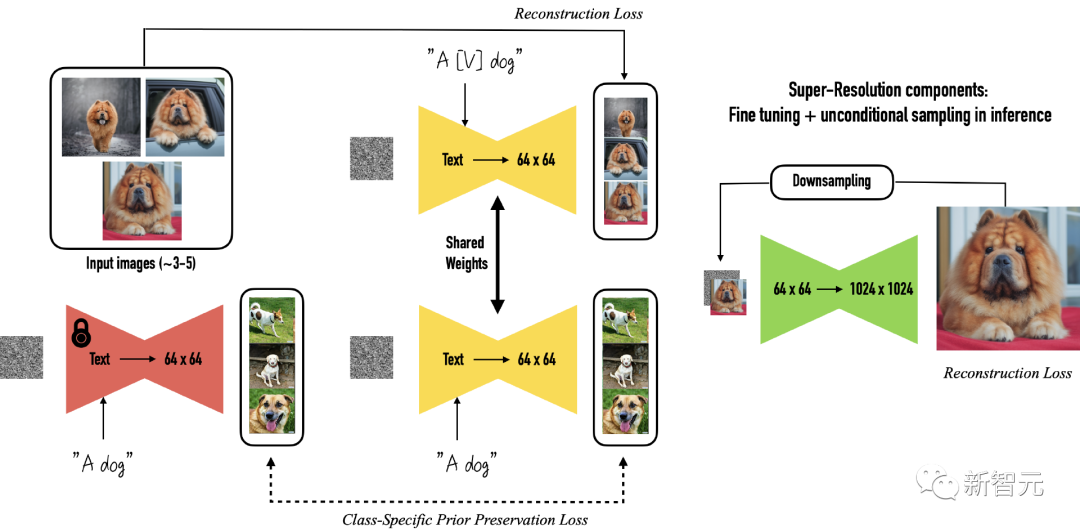
Dreambooth的輸入要求為目標主體多張圖像,以及包含主體的唯一標識符和類標簽(class label)的文本提示,其中類標簽是多個實例的集合表示,主體對應于屬于該類的特定示例。
Dreambooth的目標是將唯一標識符與每個主體(類的特定實例)相關聯,然后在文本提示的指導下,在不同的上下文中重新創建同一主體的圖像。
類標簽需要利用指定類別預訓練擴散框架的先驗知識,如果類別標簽不正確或丟失可能會導致輸出質量下降,唯一token充當對特定主題的引用,并且需要足夠少見以避免與其他常用概念沖突。
原文作者使用了一組少于3個Unicode字符序列作為token,并用T5-XXL作為分詞器。
DreamBooth使用類別先驗保存損失(class-specific prior preservation loss)來增加生成圖像的可變性,同時確保目標對象和輸出圖像之間的偏差最小,原始訓練損失如下:
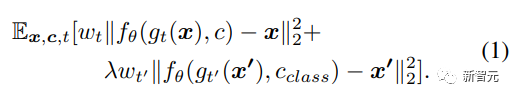
DreamBooth在先驗保存的幫助下可以有效地合成狗、貓、卡通等主體圖像,不過這篇論文中主要關注的是結構更復雜、紋理也偏細節的人臉圖像。
雖然類標簽「person」可以捕獲類似人類的特征,但這可能不足以捕獲因個體差異而形成的身份特征。
所以研究人員在損失函數中引入了一個身份保存(identity-preserving)項,可以最小化原始圖像和生成圖像生物特征之間的距離,并用新的損失函數微調VAE。
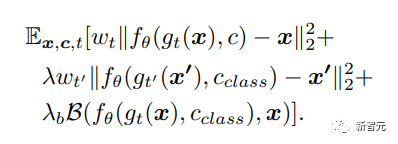
公式中的第三項代表被拍攝物體的真實圖像和生成圖像之間生物特征距離,其中B代表兩張圖像的L1距離,相同的圖像距離接近0,值越大代表兩個主體的差異越大,使用預訓練VGGFace作為特征抽取器。

下一步是針對特定目標進行微調,使用凍結的VAE和文本編碼器,同時保持U-Net模型解凍。

UNet對VAE的編碼器產生的潛在表征進行去噪,使用身份保持對比損失進行訓練。
研究人員采用SimCLR框架,使用正負樣本對之間的歸一化溫標交叉熵損失(temperature-scaled cross-entropy loss)來增強潛在表征,即下式中的S函數。

在加權項λs=0.1且溫度值=0.5的情況下,計算無噪聲輸入(z0)和去噪聲輸出(zt)的潛在表征之間的對比損失。
U-Net架構中潛在表征之間的對比損失使得模型能夠微調不同主體的擴散模型。
除了定制損失外,研究人員還使用正則化集將面部年齡發展(progression)和回歸(regression)的概念賦給潛在擴散模型,其中正則化集合包括一個類別中所有代表性的圖像,在本例中為person.
如果目標是生成真實的人臉圖像,那從互聯網上選擇人臉圖像的正則化集就足夠了。
不過本文中的任務是讓模型學習衰老和返老還童的概念,并且還要應用到不同的個體上,所以研究人員選擇使用不同年齡組的人臉圖像,然后將其與一個單詞描述(one-word caption)進行配對。
圖像描述對應于六個年齡組 :兒童(child)、青少年(tennager)、年輕人(youngadults)、中年人(middleaged)、中老年人(elderly)、老年人(old )。
相比數字提示(20歲、40歲),年齡描述的性能更好,并且可以在推理中用文本來提示擴散模型((photo of a ? token ? ? class label ? as ? age group ?)
實驗結果
實驗設置
研究人員使用Stable Diffusion v1.4實現的DreamBooth進行實驗,使用CLIP文本編碼器(在laion-aesthetics v2 5+上訓練)和矢量量化VAE來完成年齡變化,在訓練擴散模型時,文本編碼器保持凍結狀態。
研究人員使用來自CelebA數據集100名受試者的2258張人臉圖像和來自AgeDB數據集100名受試者的659張圖像構成訓練集。

除了二元屬性「Young」之外,CelebA數據集沒有受試者的年齡信息;AgeDB數據集包含精確年齡值,研究人員選擇圖像數量最多的年齡組,并將其用作訓練集,其余圖像則用于測試集(共2369幅圖像)。
研究人員使用(圖像,描述)數據對作為正則化集,其中每個人臉圖像與指示其相應年齡標簽的標題相關聯,具體兒童<15歲、青少年15-30歲、年輕人30-40歲、中年人40-50歲、中老年人50-65歲、老年人>65歲,使用四個稀少token作為標記:wzx, sks, ams, ukj
對比結果
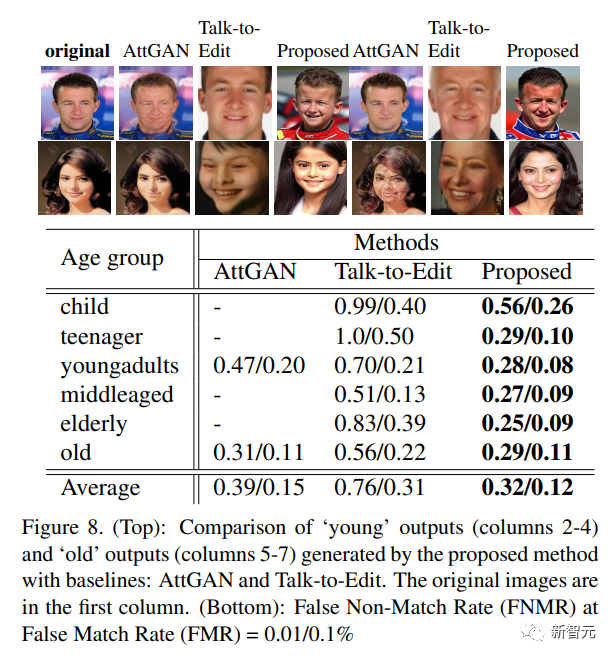
研究人員使用IPCGAN、AttGAN和Talk-toEdit作為評估對比基線模型。
由于IPCGAN是在CACD數據集上訓練的,所以研究人員對來自CACD數據集的62名受試者進行了微調,可以觀察到FNMR=2%,而文中提出的方法FNMR( False NonMatch Rate)=11%

可以看到IPCGAN默認情況無法執行老化或變年輕的操作,導致FNMR值很低。
研究人員使用DeepFace年齡預測器進行自動年齡預測,可以觀察到,與原始圖像和IPCGAN生成的圖像相比,文中方法合成的圖像會讓年齡預測得更分散,表明年齡編輯操作已經成功。

在CelebA數據集上應用AttGAN和對話編輯時,在圖像對比和生物特征匹配性能上,可以觀察到,在FMR=0.01時,文中方法在「young」類別的圖像上優于AttGAN 19%,在「old」類別圖像上優于AttGAN 7%
用戶研究
研究人員收集了26份用戶反饋,rank-1生物特征識別準確率(響應總數的平均值)達到了78.8%,各年齡組的正確識別準確率分別為:兒童=99.6%、青少年=72.7%、青少年=68.1%、中年=70.7%、老年人=93.8%

也就是說,用戶能夠以相當高的準確度成功地區分來自不同年齡組的生成圖像。