帶你穿越清明上河圖!DragNUWA驚艷亮相:一拖一拽讓靜圖秒變視頻
微軟開發(fā)的視頻生成模型DragNUWA讓清明上河圖動起來了!

只要用拖動的方式給出運動軌跡,DragNUWA就能讓圖像中的物體對象按照該軌跡移動位置并生成連貫的視頻。

DragNUWA能同時控制攝像機和多個對象的移動以及復雜的軌跡,從而生成具有現(xiàn)實世界場景和藝術繪畫特色的視頻。
近年來,可控視頻生成技術備受關注。但現(xiàn)有可控視頻生成仍存在兩大局限:
1. 現(xiàn)有的大多數(shù)工作都集中在文本、圖像或基于軌跡的控制上,導致無法在視頻中實現(xiàn)細粒度控制。
2. 軌跡控制的研究仍處于早期階段,大多數(shù)實驗都是在Human3.6M等簡單數(shù)據(jù)集上進行的。這種局限性限制了模型處理開域圖像和有效處理復雜曲線軌跡的能力。
來自微軟的研究人員提出了基于開域擴散的視頻生成模型: DragNUWA。

論文地址:https://arxiv.org/abs/2308.08089
DragNUWA針對現(xiàn)有研究中控制粒度不足的問題,同時引入了文本、圖像和軌跡信息,從語義、空間和時間角度對視頻內容進行精細控制。

第一組展示了對復雜軌跡的控制,包括復雜運動(紅色彎曲箭頭和攝像機移動(紅色向右箭頭)。
第二組展示了語言控制的影響,將不同的文字與相同的圖像和軌跡配對,以達到在圖像中引入新對象的效果。
第三組展示了圖像控制的影響,展示了真實世界和藝術視頻的生成。
為了解決目前研究中開域軌跡控制有限的問題,研究人員從三個方面提出了軌跡建模:
首先,通過軌跡采樣器(TS)實現(xiàn)對任意軌跡的開域控制;其次,通過多尺度融合(MF)控制不同粒度的軌跡;最后,通過自適應訓練(AT)策略以根據(jù)軌跡生成一致的視頻。


工作原理
DragNUWA支持三種可選輸入:文本p、圖像s和軌跡g,并側重于從三個方面設計軌跡。
首先,軌跡采樣器(TS)從開域視頻流中動態(tài)采樣軌跡。
其次,多尺度融合(MF)將軌跡與文本和圖像深度融合到UNet 架構的每個區(qū)塊中。
最后,自適應訓練(AT)可根據(jù)光流條件調整模型,使軌跡更友好。
最終,DragNUWA 能夠處理包含多個物體及其復雜軌跡的開域視頻。
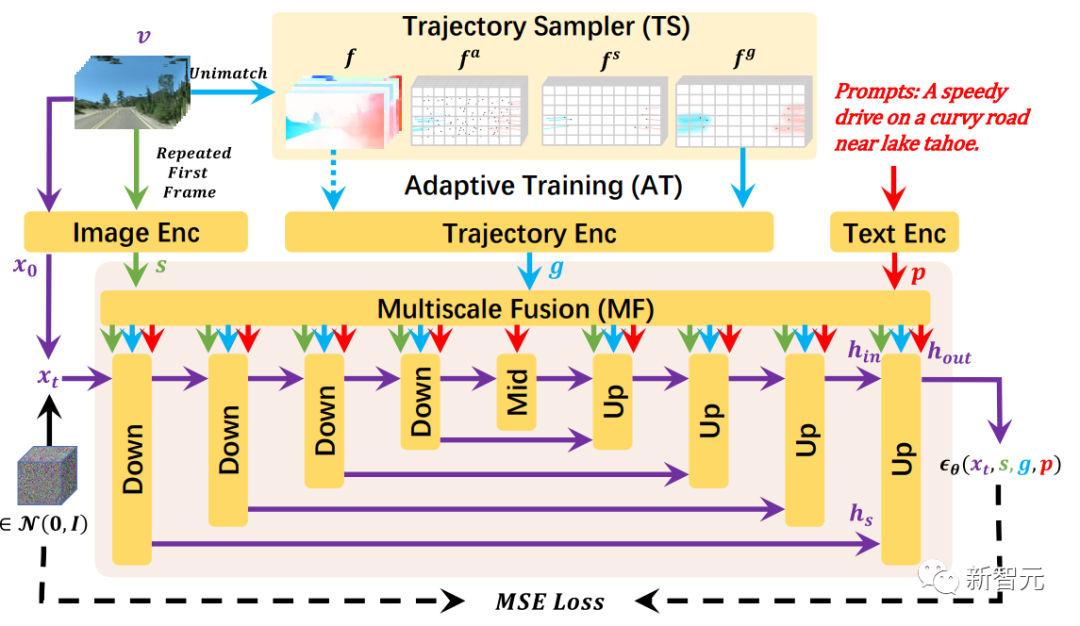
DragNUWA的訓練過程概覽
為了驗證軌跡控制的有效性,研究人員從攝像機移動和復雜軌跡兩個方面對DragNUWA進行了測試。
在視頻制作中,攝像機移動在為觀眾創(chuàng)造動態(tài)和引人入勝的視覺效果方面發(fā)揮著重要作用。
不同類型的鏡頭移動有助于敘述故事或強調場景中的元素。常見的鏡頭移動不僅包括水平和垂直移動,還包括放大和縮小。
如下圖所示,DragNUWA雖然沒有明確對攝像機運動進行建模,但它可以從開放域軌跡建模中學習到各種攝像機運動:
利用相同的文字和圖像,同時改變拖動軌跡,可以實現(xiàn)各種攝像機移動效果。例如,可通過在所需縮放位置繪制方向軌跡來表達放大和縮小效果。

視頻中的物體往往具有復雜的運動軌跡。面對多個運動物體、復雜的運動軌跡以及不同物體之間不同的運動幅度,視頻生成中的運動建模是一個巨大的挑戰(zhàn)。
研究人員通過使用相同的文字和圖片,同時改變拖動軌跡,實現(xiàn)了各種復雜的軌跡效果。
這證明了DragNUWA具有復雜運動進行精確建模的能力:支持復雜的曲線軌跡,允許軌跡長度可變,并支持同時控制多個對象的軌跡。

DragNUWA通過整合三個基本控制來實現(xiàn)精細視頻生成:文本、圖像和軌跡,分別對應語義、空間和時間方面。
這三個條件是不可或缺的:
s2v和p2v說明了圖像和文本控制作為單獨條件使用時的限制:
如s2v所示,雖然圖像本身提供了一些潛在的語義和動力學信息,但它并不能實現(xiàn)對背景和角色運動的精確控制。
如p2v所示,當只提供文本時,模型能成功生成與文本相關的視頻,但外觀和動態(tài)仍完全無法控制。
gs2v和ps2v強調了文本(p)和軌跡(g)的重要性。在沒有文本的情況下,無法確定模糊圖像 (s) 代表的是海上沖浪還是雪地沖浪。在沒有軌跡的情況下,模型會自動假定人物正在向左移動。
在三個基本條件都滿足時,pgs2v中實現(xiàn)了在雪地上沖浪和向右移動的控制。

數(shù)據(jù)集
在訓練過程中,研究團隊利用WebVid和VideoHD數(shù)據(jù)集來優(yōu)化 DragNU。
WAWebVid是一個龐大的數(shù)據(jù)集,由1000萬個網(wǎng)絡視頻組成,涵蓋了現(xiàn)實世界中的各種場景,并配有相應的標題。其涵蓋了廣泛的運動模式,適用于基于軌跡的開放域視頻生成。
VideoHD是研究團隊基于網(wǎng)絡抓取的視頻建立的數(shù)據(jù)集。研究人員首先從互聯(lián)網(wǎng)上收集了75K高分辨率、高質量的視頻片段。然后,使用BLIP2對這些片段進行標注。最后,手動過濾掉了生成結果中的一些錯誤。
作者簡介

吳晨飛博士是微軟亞洲研究院的高級研究員。他的研究重心是大規(guī)模預訓練、多模態(tài)理解和生成。主要研究工作包括多模態(tài)生成模型NUWA(女媧)系列(NUWA, NUWA-LIP, NUWA-Infinity, NUWA-3D, NUWA-XL)、多模態(tài)理解模型Bridge Tower(橋塔)系列(KD-VLP, Bridge-Tower)以及多模態(tài)對話系統(tǒng)Visual ChatGPT。在CVPR, NeurIPS, ACL, ECCV, AAAI, MM等會發(fā)表多篇論文。

段楠博士,微軟亞洲研究院資深首席研究員,自然語言計算團隊研究經(jīng)理,中國科學技術大學、西安交通大學兼職博導,天津大學兼職教授,主要從事自然語言處理、多模態(tài)基礎模型、代碼智能、機器推理等研究,多次擔任NLP/AI學術會議程序主席和領域主席,發(fā)表學術論文100余篇,Google Scholar引用10000余次,持有專利20余項。他被評為中國計算機協(xié)會(CCF)杰出會員、CCF-NLPCC青年科學家(2019年)、DeepTech中國智能計算科技創(chuàng)新人物(2022年)。