Meta AI 多語(yǔ)言閱讀理解數(shù)據(jù)集 Belebele,涵蓋 122 種語(yǔ)言變體
Meta AI 宣布推出一款涵蓋 122 種語(yǔ)言變體的多語(yǔ)言閱讀理解數(shù)據(jù)集,名為 Belebele。“我們希望這項(xiàng)工作能夠引發(fā)圍繞 LLM 多語(yǔ)言性的新討論”。

BELEBELE 是首個(gè)跨語(yǔ)言并行數(shù)據(jù)集,可以直接比較所有語(yǔ)言的模型性能。該數(shù)據(jù)集涵蓋了 29 種腳本和 27 個(gè)語(yǔ)系中不同類型的高、中、低資源語(yǔ)言。此外,還有 7 種語(yǔ)言包含在兩種不同的腳本中,從而為印地語(yǔ)、烏爾都語(yǔ)、孟加拉語(yǔ)、尼泊爾語(yǔ)和僧伽羅語(yǔ)的羅馬化變體制定了首個(gè) NLP 基準(zhǔn)。
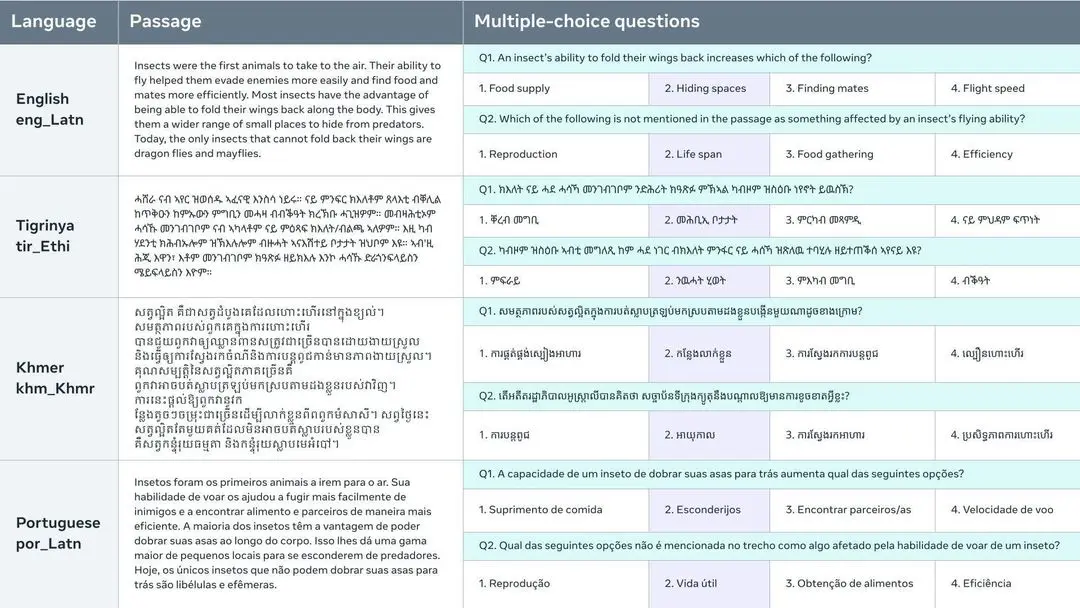
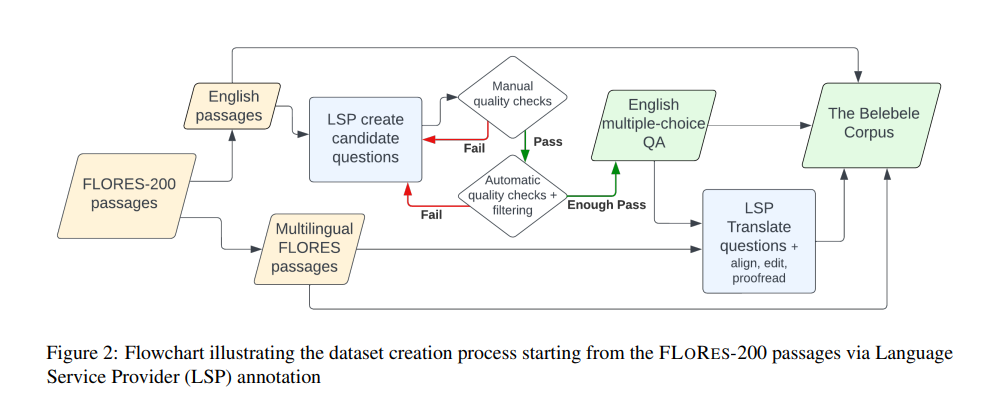
該數(shù)據(jù)集可對(duì)單語(yǔ)和多語(yǔ)模型進(jìn)行評(píng)估,但其并行性也可在一些跨語(yǔ)言環(huán)境中對(duì)跨語(yǔ)言文本表征進(jìn)行評(píng)估。通過(guò)從相關(guān)質(zhì)量保證數(shù)據(jù)集中收集訓(xùn)練集,可以對(duì)任務(wù)進(jìn)行全面微調(diào)評(píng)估。每個(gè)問(wèn)題都基于 Flores-200 數(shù)據(jù)集中的一段短文,并有四個(gè)多項(xiàng)選擇答案。這些問(wèn)題經(jīng)過(guò)精心設(shè)計(jì),以區(qū)分具有不同一般語(yǔ)言理解水平的模型。
- 每種語(yǔ)言有 900 道題
- 488 個(gè)不同段落,每個(gè)段落有 1-2 道相關(guān)問(wèn)題。
- 每道題有 4 個(gè)選擇答案,其中只有一個(gè)是正確的。
- 122 種語(yǔ)言 / 語(yǔ)言變體(包括英語(yǔ))。
- 900 x 122 = 109,800 個(gè)問(wèn)題。
研究人員利用這個(gè)數(shù)據(jù)集評(píng)估了多語(yǔ)言屏蔽語(yǔ)言模型(MLM)和大語(yǔ)言模型(LLM)的能力。結(jié)果表明,盡管以英語(yǔ)為中心的 LLM 有顯著的跨語(yǔ)言遷移能力,但在平衡的多語(yǔ)言數(shù)據(jù)上經(jīng)過(guò)預(yù)訓(xùn)練的更小的 MLM 仍然能理解更多的語(yǔ)言。且詞匯量越大、越有意識(shí)地構(gòu)建詞匯,在低資源語(yǔ)言上的表現(xiàn)就越好。