













AI自主智能體大盤點,構(gòu)建、應(yīng)用、評估全覆蓋,人大高瓴文繼榮等32頁綜述
在當(dāng)今的 AI 時代,自主智能體被認為是通向通用人工智能(AGI)的一條有前途的道路。所謂自主智能體,即能夠通過自主規(guī)劃和指令來完成任務(wù)。在早期的開發(fā)范式中,決定智能體行動的策略功能是以啟發(fā)式為主的,并在環(huán)境交互中逐步得到完善。
不過,在不受約束的開放域環(huán)境中,自主智能體的行動往往很難企及人類水平的熟練程度。
隨著近年來大語言模型(LLM)取得了巨大成功,并展現(xiàn)出了實現(xiàn)類人智能的潛力。因而得益于強大的能力,LLM 越來越多地被用作創(chuàng)建自主智能體的核心協(xié)調(diào)者,并先后出現(xiàn)花樣繁多的 AI 智能體。這些智能體通過模仿類人的決策過程,為更復(fù)雜和適應(yīng)性更強的 AI 系統(tǒng)提供了一條可行性路徑。
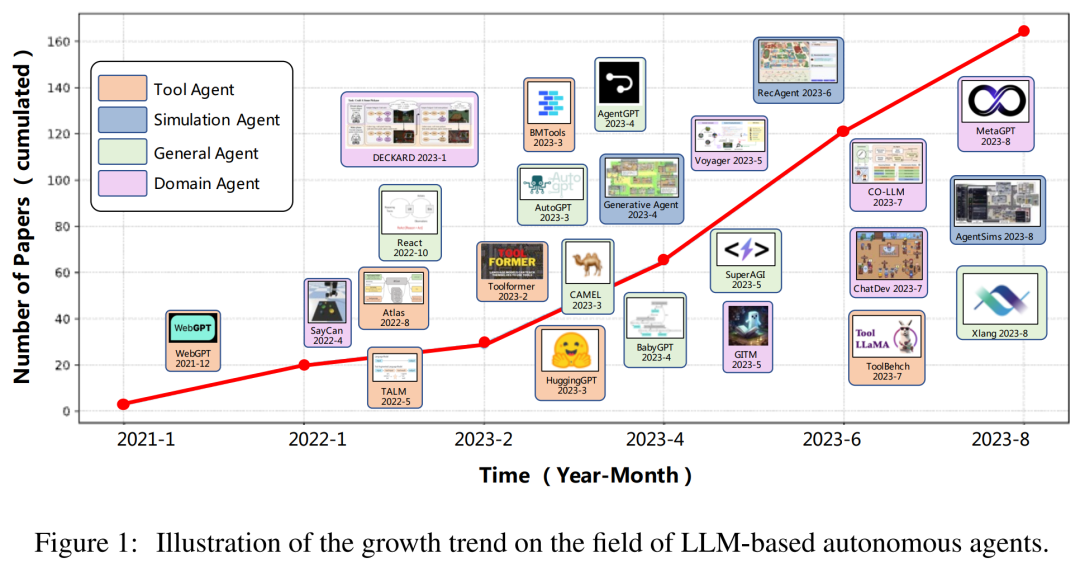
基于 LLM 的自主智能體一覽,包括工具智能體、模擬智能體、通用智能體和領(lǐng)域智能體。
在現(xiàn)階段,對已經(jīng)出現(xiàn)的基于 LLM 的自主智能體進行整體分析非常重要,并對全面了解該領(lǐng)域的發(fā)展現(xiàn)狀以及啟發(fā)未來的研究具有重要意義。
本文中,來自中國人民大學(xué)高瓴人工智能學(xué)院的研究者對基于 LLM 的自主智能體展開了全面調(diào)研,并著眼于它們的構(gòu)建、應(yīng)用和評估三個方面。

論文地址:https://arxiv.org/pdf/2308.11432.pdf
對于智能體的構(gòu)建,他們提出了一個由四部分組成的統(tǒng)一框架,分別是表示智能體屬性的配置模塊、存儲歷史信息的記憶模塊、制定未來行動策略的規(guī)劃模塊和執(zhí)行規(guī)劃決定的行動模塊。在介紹了典型的智能體模塊之后,研究者還總結(jié)了常用的微調(diào)策略,通過這些策略來增強智能體對不同應(yīng)用場景的適應(yīng)性。
接下來研究者概述了自主智能體的潛在應(yīng)用,探討它們?nèi)绾螌ι鐣茖W(xué)、自然科學(xué)和工程學(xué)領(lǐng)域產(chǎn)生增益。最后討論了自主智能體的評估方法,包括主觀和客觀評估策略。下圖為文章整體架構(gòu)。
 圖源:https://github.com/Paitesanshi/LLM-Agent-Survey
圖源:https://github.com/Paitesanshi/LLM-Agent-Survey
基于 LLM 的自主智能體構(gòu)建
為了讓基于 LLM 的自主智能體更加高效,有兩個方面需要考慮:首先是應(yīng)該設(shè)計怎樣的架構(gòu)使得智能體能更好的利用 LLM;其次是如何有效地學(xué)習(xí)參數(shù)。
智能體架構(gòu)設(shè)計:本文提出了一個統(tǒng)一的框架來總結(jié)之前研究中提出的架構(gòu),整體結(jié)構(gòu)如圖 2 所示,它由分析(profiling)模塊、記憶模塊、規(guī)劃模塊以及動作模塊組成。
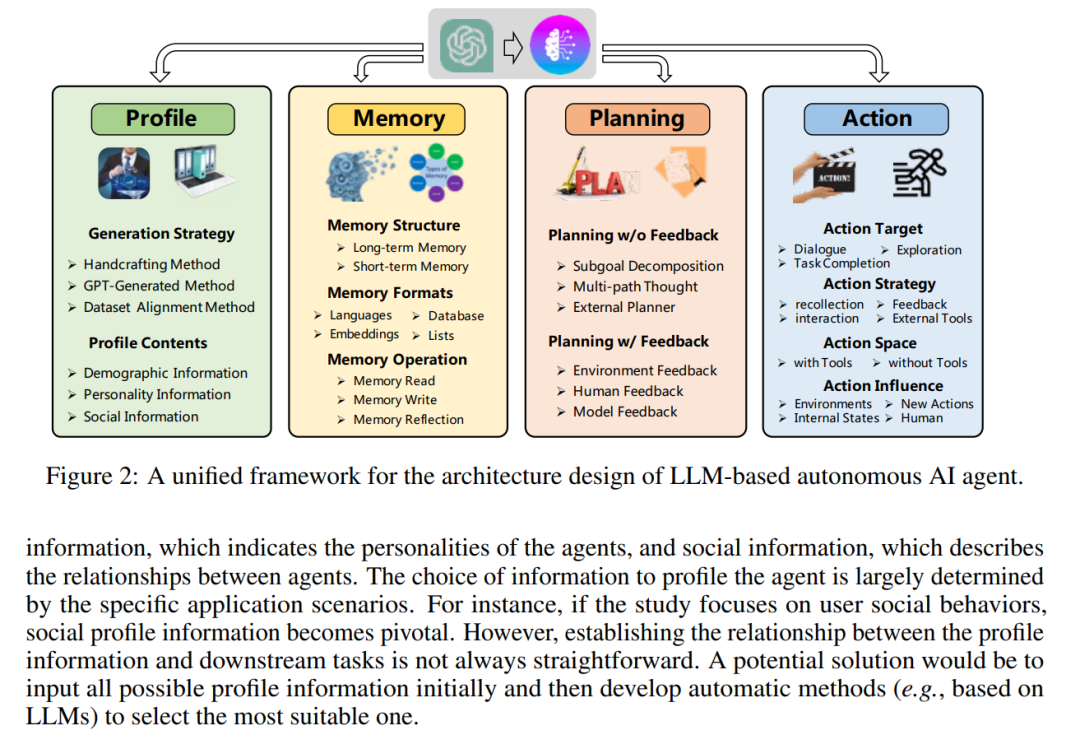
總結(jié)而言,分析模塊旨在識別智能體是什么角色;記憶和規(guī)劃模塊可將智能體置于動態(tài)環(huán)境中,使智能體能夠回憶過去的行為并計劃未來的行動;動作模塊負責(zé)將智能體的決策轉(zhuǎn)化為具體的輸出。在這些模塊中,分析模塊影響記憶和規(guī)劃模塊,這三個模塊共同影響動作模塊。
分析模塊
自主智能體通過特定角色來執(zhí)行任務(wù),例如程序員、教師和領(lǐng)域?qū)<摇7治瞿K旨在表明智能體的角色是什么,這些信息通常被寫入輸入提示中以影響 LLM 行為。在現(xiàn)有的工作中,有三種常用的策略來生成智能體配置文件:手工制作方法;LLM-generation 方法;數(shù)據(jù)集對齊方法。
記憶模塊
記憶模塊在 AI 智能體的構(gòu)建中起著非常重要的作用。它記憶從環(huán)境中感知到的信息,并利用記錄的記憶來促進智能體未來的動作。記憶模塊可以幫助智能體積累經(jīng)驗、實現(xiàn)自我進化,并以更加一致、合理、有效的方式完成任務(wù)。
規(guī)劃模塊
當(dāng)人類面臨復(fù)雜任務(wù)時,他們首先將其分解為簡單的子任務(wù),然后逐一解決每個子任務(wù)。規(guī)劃模塊賦予基于 LLM 的智能體解決復(fù)雜任務(wù)時需要的思考和規(guī)劃能力,使智能體更加全面、強大、可靠。本文介紹了兩種規(guī)劃模塊:沒有反饋的規(guī)劃以及有反饋的規(guī)劃。
動作模塊
動作模塊旨在將智能體的決策轉(zhuǎn)化為具體的結(jié)果輸出。它直接與環(huán)境交互,決定智能體完成任務(wù)的有效性。本節(jié)從動作目標(biāo)、策略、動作空間和動作影響來介紹。
除了上述 4 個部分外,本章還介紹了智能體的學(xué)習(xí)策略,包括從示例中學(xué)習(xí)、從環(huán)境反饋中學(xué)習(xí)、從交互的人類反饋中學(xué)習(xí)。
表 1 列出了之前的工作和本文的分類法之間的對應(yīng)關(guān)系:

基于 LLM 的自主智能體應(yīng)用
本章探討了基于 LLM 的自主智能體在三個不同領(lǐng)域的變革性影響:社會科學(xué)、自然科學(xué)和工程。

例如基于 LLM 的智能體可用于設(shè)計和優(yōu)化復(fù)雜結(jié)構(gòu),如建筑物、橋梁、水壩、道路等。此前,有研究者提出了一個交互式框架,人類建筑師和 AI 智能體協(xié)同辦公在 3D 模擬中構(gòu)建結(jié)構(gòu)環(huán)境。交互式智能體可以理解自然語言指令、放置模塊、尋求建議并結(jié)合人類反饋,顯示出工程設(shè)計中人機協(xié)作的潛力。
又比如在計算機科學(xué)和軟件工程領(lǐng)域,基于 LLM 的智能體提供了自動化編碼、測試、調(diào)試和文檔生成的潛力。有研究者提出了 ChatDev ,這是一個端到端的框架,其中多個智能體通過自然語言對話進行溝通和協(xié)作,以完成軟件開發(fā)生命周期;ToolBench 可以用于代碼自動補全和代碼推薦等任務(wù);MetaGPT 可以扮演產(chǎn)品經(jīng)理、架構(gòu)師、項目經(jīng)理和工程師等角色,內(nèi)部監(jiān)督代碼生成并提高最終輸出代碼的質(zhì)量等等。
下表為基于 LLM 的自主智能體的代表性應(yīng)用:

基于 LLM 的自主智能體評估
本文介紹了兩種常用的評估策略:主觀評估和客觀評估。
主觀評估是指人類通過交互、評分等多種手段對基于 LLM 的智能體的能力進行測試。在這種情況下,參與評估的人員往往是通過眾包平臺招募的;而一些研究者認為眾包人員由于個體能力差異而不穩(wěn)定,因而也會使用專家注釋來進行評估。
除此以外,在當(dāng)前的一些研究中,我們可以使用 LLM 智能體作為主觀評估者。例如在 ChemCrow 研究中,EvaluatorGPT 通過指定等級來評估實驗結(jié)果,該等級既考慮任務(wù)的成功完成,又考慮基本思維過程的準(zhǔn)確性。又比如 ChatEval 組建了一個基于 LLM 的多智能體裁判小組,通過辯論來評估模型的生成結(jié)果。
與主觀評估相比,客觀評估具有多種優(yōu)勢,客觀評估是指使用定量指標(biāo)來評估基于 LLM 自主智能體的能力。本節(jié)從指標(biāo)、策略和基準(zhǔn)的角度回顧和綜合客觀評估方法。
在使用評估過程中,我們可以將這兩種方法結(jié)合使用。
表 3 總結(jié)了以前的工作與這些評估策略之間的對應(yīng)關(guān)系:

了解更多內(nèi)容,請參考原論文。


























